ViG: Linear-complexity Visual Sequence Learning with Gated Linear Attention
2405.18425
0
0
Abstract
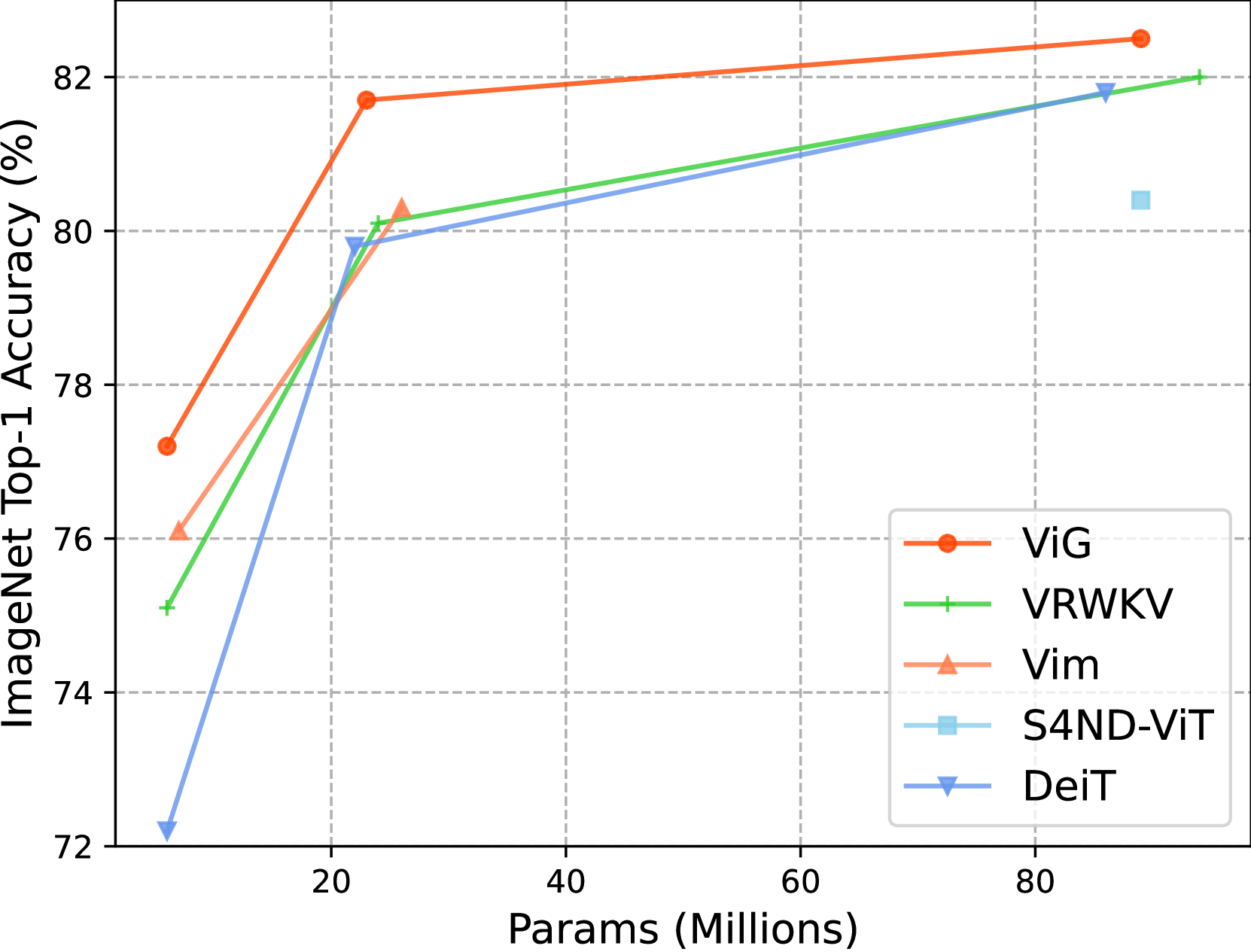
Recently, linear complexity sequence modeling networks have achieved modeling capabilities similar to Vision Transformers on a variety of computer vision tasks, while using fewer FLOPs and less memory. However, their advantage in terms of actual runtime speed is not significant. To address this issue, we introduce Gated Linear Attention (GLA) for vision, leveraging its superior hardware-awareness and efficiency. We propose direction-wise gating to capture 1D global context through bidirectional modeling and a 2D gating locality injection to adaptively inject 2D local details into 1D global context. Our hardware-aware implementation further merges forward and backward scanning into a single kernel, enhancing parallelism and reducing memory cost and latency. The proposed model, ViG, offers a favorable trade-off in accuracy, parameters, and FLOPs on ImageNet and downstream tasks, outperforming popular Transformer and CNN-based models. Notably, ViG-S matches DeiT-B's accuracy while using only 27% of the parameters and 20% of the FLOPs, running 2$times$ faster on $224times224$ images. At $1024times1024$ resolution, ViG-T uses 5.2$times$ fewer FLOPs, saves 90% GPU memory, runs 4.8$times$ faster, and achieves 20.7% higher top-1 accuracy than DeiT-T. These results position ViG as an efficient and scalable solution for visual representation learning. Code is available at url{https://github.com/hustvl/ViG}.
Create account to get full access
Overview
- This paper introduces ViG (Visual Sequence Learning with Gated Linear Attention), a novel neural network architecture for learning visual sequences.
- ViG uses a gated linear attention mechanism to efficiently process visual inputs, achieving linear computational complexity.
- The authors demonstrate ViG's strong performance on several benchmark tasks, including video classification and image-to-text generation, while maintaining high computational efficiency.
Plain English Explanation
The ViG model is a new type of neural network designed to learn from sequences of visual data, such as videos or image-text pairs. Traditional neural networks can struggle to process long sequences efficiently, as the computational complexity often grows quadratically with sequence length. ViG addresses this issue by using a specialized "gated linear attention" mechanism, which allows the model to process visual inputs in a more efficient, linear-time manner.
This gated linear attention is a key innovation that enables ViG to achieve strong performance on tasks like video classification and image-to-text generation, while being much faster and more computationally efficient than previous approaches. The authors show that ViG can outperform other state-of-the-art models on these benchmarks, demonstrating the benefits of their linear-complexity architecture.
The plain English takeaway is that ViG is a new neural network that can effectively learn from sequential visual data, like videos or image-text pairs, in a much more efficient way than previous models. This efficiency allows ViG to achieve high performance on various tasks while being faster and requiring less computational resources.
Technical Explanation
The core of ViG is its gated linear attention mechanism, which is a novel attention-based module that can process visual inputs with linear computational complexity. This is in contrast to standard attention mechanisms, which have quadratic complexity and can become prohibitively expensive for long sequences.
ViG's gated linear attention works by first projecting the input features into a set of "key" and "value" vectors. These vectors are then used to compute attention weights, but in a way that avoids the quadratic bottleneck. Specifically, ViG uses a gating mechanism to selectively attend to only a subset of the input features, rather than computing attention over the entire sequence.
This gated linear attention module is integrated into ViG's overall architecture, which combines it with convolutional and transformer-based layers to effectively process visual sequences. The authors demonstrate the effectiveness of this design through extensive experiments on video classification and image-to-text generation tasks, where ViG achieves state-of-the-art results while being significantly more efficient than competing models.
Critical Analysis
The key innovation in this work is the gated linear attention mechanism, which allows ViG to process visual sequences in a highly efficient manner. The authors provide a thorough theoretical and empirical analysis of this component, demonstrating its benefits in terms of computational complexity and performance.
However, the paper does not extensively explore the limitations or potential issues with the ViG architecture. For example, it would be helpful to understand how ViG's performance and efficiency scale as the input sequence length increases, or how it compares to other linear-complexity attention mechanisms like GViT or FasterViT.
Additionally, the paper focuses primarily on vision-related tasks, and it's unclear how well ViG would perform on other sequence learning problems, such as natural language processing or audio processing. Exploring the generalization of ViG to a wider range of sequence-to-sequence tasks could provide valuable insights into the model's broader applicability.
Conclusion
The ViG model presented in this paper is a promising new approach to efficient visual sequence learning. By introducing a gated linear attention mechanism, the authors have developed a neural network architecture that can process long visual sequences with high computational efficiency, while still achieving state-of-the-art performance on benchmark tasks.
This work contributes to the ongoing research efforts to develop more scalable and practical deep learning models for processing sequential data, such as DIG and GLIMS. The ViG model's linear-complexity attention mechanism and its strong empirical results suggest that it could be a valuable tool for a wide range of applications involving visual sequence data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Gated Linear Attention Transformers with Hardware-Efficient Training
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, Yoon Kim
0
0
Transformers with linear attention allow for efficient parallel training but can simultaneously be formulated as an RNN with 2D (matrix-valued) hidden states, thus enjoying linear-time inference complexity. However, linear attention generally underperforms ordinary softmax attention. Moreover, current implementations of linear attention lack I/O-awareness and are thus slower than highly optimized implementations of softmax attention. This work describes a hardware-efficient algorithm for linear attention that trades off memory movement against parallelizability. The resulting implementation, dubbed FLASHLINEARATTENTION, is faster than FLASHATTENTION-2 (Dao, 2023) as a standalone layer even on short sequence lengths (e.g., 1K). We then generalize this algorithm to a more expressive variant of linear attention with data-dependent gates. When used as a replacement for the standard attention layer in Transformers, the resulting gated linear attention (GLA) Transformer is found to perform competitively against the LLaMA-architecture Transformer (Touvron et al., 2023) as well recent linear-time-inference baselines such as RetNet (Sun et al., 2023a) and Mamba (Gu & Dao, 2023) on moderate-scale language modeling experiments. GLA Transformer is especially effective at length generalization, enabling a model trained on 2K to generalize to sequences longer than 20K without significant perplexity degradations. For training speed, the GLA Transformer has higher throughput than a similarly-sized Mamba model.
6/6/2024

DiG: Scalable and Efficient Diffusion Models with Gated Linear Attention
Lianghui Zhu, Zilong Huang, Bencheng Liao, Jun Hao Liew, Hanshu Yan, Jiashi Feng, Xinggang Wang
0
0
Diffusion models with large-scale pre-training have achieved significant success in the field of visual content generation, particularly exemplified by Diffusion Transformers (DiT). However, DiT models have faced challenges with scalability and quadratic complexity efficiency. In this paper, we aim to leverage the long sequence modeling capability of Gated Linear Attention (GLA) Transformers, expanding its applicability to diffusion models. We introduce Diffusion Gated Linear Attention Transformers (DiG), a simple, adoptable solution with minimal parameter overhead, following the DiT design, but offering superior efficiency and effectiveness. In addition to better performance than DiT, DiG-S/2 exhibits $2.5times$ higher training speed than DiT-S/2 and saves $75.7%$ GPU memory at a resolution of $1792 times 1792$. Moreover, we analyze the scalability of DiG across a variety of computational complexity. DiG models, with increased depth/width or augmentation of input tokens, consistently exhibit decreasing FID. We further compare DiG with other subquadratic-time diffusion models. With the same model size, DiG-XL/2 is $4.2times$ faster than the recent Mamba-based diffusion model at a $1024$ resolution, and is $1.8times$ faster than DiT with CUDA-optimized FlashAttention-2 under the $2048$ resolution. All these results demonstrate its superior efficiency among the latest diffusion models. Code is released at https://github.com/hustvl/DiG.
5/29/2024
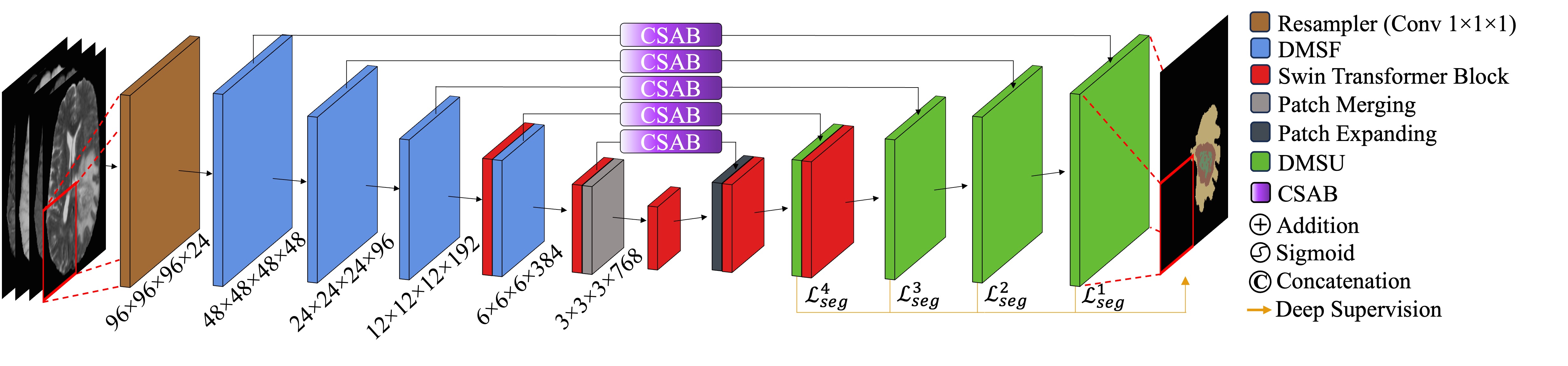
GLIMS: Attention-Guided Lightweight Multi-Scale Hybrid Network for Volumetric Semantic Segmentation
Ziya Ata Yaz{i}c{i}, .Ilkay Oksuz, Haz{i}m Kemal Ekenel
0
0
Convolutional Neural Networks (CNNs) have become widely adopted for medical image segmentation tasks, demonstrating promising performance. However, the inherent inductive biases in convolutional architectures limit their ability to model long-range dependencies and spatial correlations. While recent transformer-based architectures address these limitations by leveraging self-attention mechanisms to encode long-range dependencies and learn expressive representations, they often struggle to extract low-level features and are highly dependent on data availability. This motivated us for the development of GLIMS, a data-efficient attention-guided hybrid volumetric segmentation network. GLIMS utilizes Dilated Feature Aggregator Convolutional Blocks (DACB) to capture local-global feature correlations efficiently. Furthermore, the incorporated Swin Transformer-based bottleneck bridges the local and global features to improve the robustness of the model. Additionally, GLIMS employs an attention-guided segmentation approach through Channel and Spatial-Wise Attention Blocks (CSAB) to localize expressive features for fine-grained border segmentation. Quantitative and qualitative results on glioblastoma and multi-organ CT segmentation tasks demonstrate GLIMS' effectiveness in terms of complexity and accuracy. GLIMS demonstrated outstanding performance on BraTS2021 and BTCV datasets, surpassing the performance of Swin UNETR. Notably, GLIMS achieved this high performance with a significantly reduced number of trainable parameters. Specifically, GLIMS has 47.16M trainable parameters and 72.30G FLOPs, while Swin UNETR has 61.98M trainable parameters and 394.84G FLOPs. The code is publicly available on https://github.com/yaziciz/GLIMS.
4/30/2024
👀
FasterViT: Fast Vision Transformers with Hierarchical Attention
Ali Hatamizadeh, Greg Heinrich, Hongxu Yin, Andrew Tao, Jose M. Alvarez, Jan Kautz, Pavlo Molchanov
0
0
We design a new family of hybrid CNN-ViT neural networks, named FasterViT, with a focus on high image throughput for computer vision (CV) applications. FasterViT combines the benefits of fast local representation learning in CNNs and global modeling properties in ViT. Our newly introduced Hierarchical Attention (HAT) approach decomposes global self-attention with quadratic complexity into a multi-level attention with reduced computational costs. We benefit from efficient window-based self-attention. Each window has access to dedicated carrier tokens that participate in local and global representation learning. At a high level, global self-attentions enable the efficient cross-window communication at lower costs. FasterViT achieves a SOTA Pareto-front in terms of accuracy and image throughput. We have extensively validated its effectiveness on various CV tasks including classification, object detection and segmentation. We also show that HAT can be used as a plug-and-play module for existing networks and enhance them. We further demonstrate significantly faster and more accurate performance than competitive counterparts for images with high resolution. Code is available at https://github.com/NVlabs/FasterViT.
4/3/2024