GMT: A Robust Global Association Model for Multi-Target Multi-Camera Tracking

0

Sign in to get full access
Overview
- This paper presents GMT, a robust global association model for multi-target multi-camera tracking (MTMC).
- MTMC is a challenging computer vision problem that involves tracking multiple targets across multiple non-overlapping cameras.
- The authors propose a vision transformer-based approach that combines global and local features to improve tracking performance.
Plain English Explanation
The paper addresses the problem of multi-target multi-camera tracking (MTMC). This is a challenging computer vision task where the goal is to track multiple people or objects as they move through a network of cameras with non-overlapping fields of view.
The authors introduce a new model called GMT (Global Multi-Target Tracker) that uses a vision transformer to combine global and local features for more robust tracking. Global features capture the overall context and appearance of a target, while local features focus on the details of the target's shape and movement.
By combining these complementary types of information, GMT is able to more accurately associate detections of the same target across different cameras, even when the target's appearance changes or it moves between cameras with non-overlapping views. This helps address some of the key challenges in large-scale MTMC tracking.
The authors evaluate GMT on several MTMC benchmarks and show that it outperforms previous state-of-the-art methods, demonstrating the effectiveness of their global association approach. This work advances the field of multi-object tracking and brings us closer to generalizable multi-object tracking systems that can operate reliably in complex, real-world environments.
Technical Explanation
The key innovation of this work is the Global Multi-Target Tracker (GMT) model, which leverages a vision transformer architecture to combine global and local features for robust multi-target multi-camera (MTMC) tracking.
The authors first extract appearance features from target bounding boxes using a convolutional neural network. They then feed these features into a vision transformer, which learns to aggregate global context information across all targets. This global representation is combined with the local appearance features to produce a final feature embedding for each target.
These combined features are used to perform data association across camera views, linking detections of the same target even as it moves between non-overlapping cameras. The authors formulate MTMC tracking as a graph optimization problem, where nodes represent detections and edges represent potential associations.
To improve efficiency, the authors propose a two-stage approach. First, they perform local data association within each camera view. Then, they optimize the global graph to associate detections across all cameras, leveraging the rich global and local features learned by GMT.
Experiments on several MTMC benchmarks show that GMT outperforms previous state-of-the-art methods by a significant margin. The authors attribute this improved performance to the vision transformer's ability to effectively capture global context, which complements the local appearance features for more robust target association.
Critical Analysis
The authors provide a thorough evaluation of GMT across multiple MTMC datasets, demonstrating its strong performance compared to prior work. However, the paper does not deeply discuss potential limitations or areas for further research.
One potential concern is the computational complexity of the two-stage optimization approach, which may limit the scalability of GMT to extremely large-scale multi-camera networks. The authors could explore ways to further improve the efficiency of their global association model.
Additionally, the paper does not address potential biases or fairness issues that may arise from the use of vision transformers and deep learning models for MTMC tracking. As these systems are deployed in real-world applications, it will be important to carefully assess their impacts and ensure they do not amplify harmful societal biases.
Overall, this work represents a significant advancement in the field of multi-object tracking, and the authors' global association approach shows promise for improving the reliability and generalizability of MTMC tracking systems. Further research is needed to address the potential limitations and ensure the responsible development of these technologies.
Conclusion
This paper presents GMT, a robust global association model for multi-target multi-camera tracking. By combining global and local features using a vision transformer, GMT is able to more accurately associate detections of the same target across cameras with non-overlapping views.
The authors' experiments demonstrate that GMT outperforms previous state-of-the-art MTMC tracking methods, highlighting the effectiveness of their global association approach. This work advances the field of multi-object tracking and brings us closer to generalizable, large-scale tracking systems that can operate reliably in complex, real-world environments.
While the paper does not address all potential limitations, it represents an important step forward in the development of robust and scalable MTMC tracking solutions. As these technologies continue to evolve, it will be crucial to carefully consider their societal impacts and ensure they are deployed responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GMT: A Robust Global Association Model for Multi-Target Multi-Camera Tracking
Huijie Fan, Tinghui Zhao, Qiang Wang, Baojie Fan, Yandong Tang, LianQing Liu
In the task of multi-target multi-camera (MTMC) tracking of pedestrians, the data association problem is a key issue and main challenge, especially with complications arising from camera movements, lighting variations, and obstructions. However, most MTMC models adopt two-step approaches, thus heavily depending on the results of the first-step tracking in practical applications. Moreover, the same targets crossing different cameras may exhibit significant appearance variations, which further increases the difficulty of cross-camera matching. To address the aforementioned issues, we propose a global online MTMC tracking model that addresses the dependency on the first tracking stage in two-step methods and enhances cross-camera matching. Specifically, we propose a transformer-based global MTMC association module to explore target associations across different cameras and frames, generating global trajectories directly. Additionally, to integrate the appearance and spatio-temporal features of targets, we propose a feature extraction and fusion module for MTMC tracking. This module enhances feature representation and establishes correlations between the features of targets across multiple cameras. To accommodate high scene diversity and complex lighting condition variations, we have established the VisionTrack dataset, which enables the development of models that are more generalized and robust to various environments. Our model demonstrates significant improvements over comparison methods on the VisionTrack dataset and others.
Read more7/2/2024
0
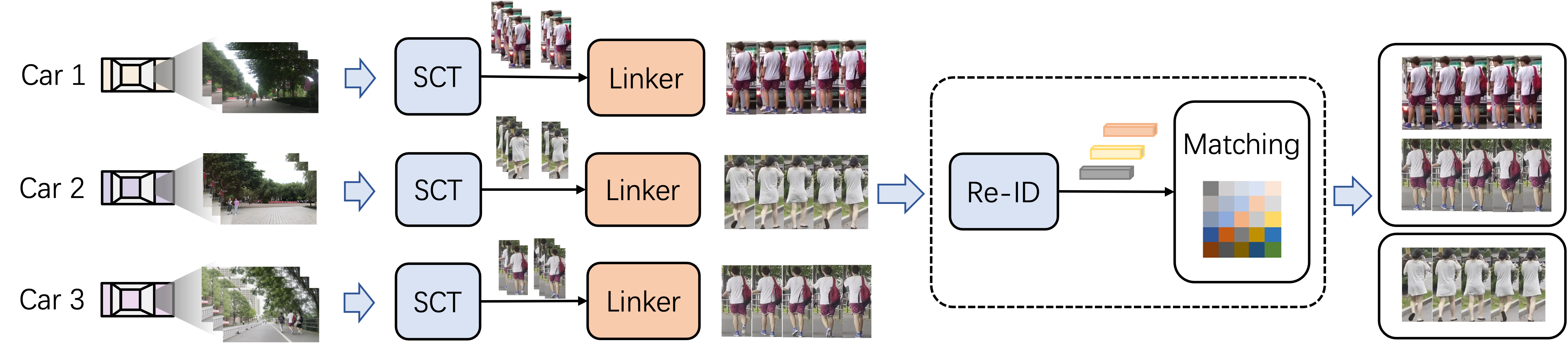
Towards Effective Multi-Moving-Camera Tracking: A New Dataset and Lightweight Link Model
Yanting Zhang, Shuanghong Wang, Qingxiang Wang, Cairong Yan, Rui Fan
Ensuring driving safety for autonomous vehicles has become increasingly crucial, highlighting the need for systematic tracking of on-road pedestrians. Most vehicles are equipped with visual sensors, however, the large-scale visual data has not been well studied yet. Multi-target multi-camera (MTMC) tracking systems are composed of two modules: single-camera tracking (SCT) and inter-camera tracking (ICT). To reliably coordinate between them, MTMC tracking has been a very complicated task, while tracking across multiple moving cameras makes it even more challenging. In this paper, we focus on multi-target multi-moving-camera (MTMMC) tracking, which is attracting increasing attention from the research community. Observing there are few datasets for MTMMC tracking, we collect a new dataset, called Multi-Moving-Camera Track (MMCT), which contains sequences under various driving scenarios. To address the common problems of identity switch easily faced by most existing SCT trackers, especially for moving cameras due to ego-motion between the camera and targets, a lightweight appearance-free global link model, called Linker, is proposed to mitigate the identity switch by associating two disjoint tracklets of the same target into a complete trajectory within the same camera. Incorporated with Linker, existing SCT trackers generally obtain a significant improvement. Moreover, to alleviate the impact of the image style variations caused by different cameras, a color transfer module is effectively incorporated to extract cross-camera consistent appearance features for pedestrian association across moving cameras for ICT, resulting in a much improved MTMMC tracking system, which can constitute a step further towards coordinated mining of multiple moving cameras. The project page is available at https://dhu-mmct.github.io/.
Read more4/24/2024
📈
0
City-Scale Multi-Camera Vehicle Tracking System with Improved Self-Supervised Camera Link Model
Yuqiang Lin, Sam Lockyer, Adrian Evans, Markus Zarbock, Nic Zhang
Multi-Target Multi-Camera Tracking (MTMCT) has broad applications and forms the basis for numerous future city-wide systems (e.g. traffic management, crash detection, etc.). However, the challenge of matching vehicle trajectories across different cameras based solely on feature extraction poses significant difficulties. This article introduces an innovative multi-camera vehicle tracking system that utilizes a self-supervised camera link model. In contrast to related works that rely on manual spatial-temporal annotations, our model automatically extracts crucial multi-camera relationships for vehicle matching. The camera link is established through a pre-matching process that evaluates feature similarities, pair numbers, and time variance for high-quality tracks. This process calculates the probability of spatial linkage for all camera combinations, selecting the highest scoring pairs to create camera links. Our approach significantly improves deployment times by eliminating the need for human annotation, offering substantial improvements in efficiency and cost-effectiveness when it comes to real-world application. This pairing process supports cross camera matching by setting spatial-temporal constraints, reducing the searching space for potential vehicle matches. According to our experimental results, the proposed method achieves a new state-of-the-art among automatic camera-link based methods in CityFlow V2 benchmarks with 61.07% IDF1 Score.
Read more7/10/2024
📊
0
Multi-Camera Multi-Person Association using Transformer-Based Dense Pixel Correspondence Estimation and Detection-Based Masking
Daniel Kathein, Byron Hernandez, Henry Medeiros
Multi-camera Association (MCA) is the task of identifying objects and individuals across camera views and is an active research topic, given its numerous applications across robotics, surveillance, and agriculture. We investigate a novel multi-camera multi-target association algorithm based on dense pixel correspondence estimation with a Transformer-based architecture and underlying detection-based masking. After the algorithm generates a set of corresponding keypoints and their respective confidence levels between every pair of detections in the camera views are computed, an affinity matrix is determined containing the probabilities of matches between each pair. Finally, the Hungarian algorithm is applied to generate an optimal assignment matrix with all the predicted associations between the camera views. Our method is evaluated on the WILDTRACK Seven-Camera HD Dataset, a high-resolution dataset containing footage of walking pedestrians as well as precise annotations and camera calibrations. Our results conclude that the algorithm performs exceptionally well associating pedestrians on camera pairs that are positioned close to each other and observe the scene from similar perspectives. On camera pairs with orientations that are drastically different in distance or angle, there is still significant room for improvement.
Read more8/20/2024