City-Scale Multi-Camera Vehicle Tracking System with Improved Self-Supervised Camera Link Model

0
📈
Sign in to get full access
Overview
- Multi-Target Multi-Camera Tracking (MTMCT) has important applications in areas like traffic management and crash detection.
- Matching vehicle trajectories across different cameras based only on feature extraction is a significant challenge.
- This paper introduces an innovative MTMCT system that uses a self-supervised camera link model to automatically establish crucial multi-camera relationships for vehicle matching.
Plain English Explanation
The paper describes a new system for tracking vehicles across multiple cameras. Tracking vehicles across cameras is an important task with applications in areas like traffic management and crash detection. However, matching vehicle trajectories based solely on features like appearance is very difficult, as vehicles can look similar and cameras may have complex spatial-temporal relationships.
The key innovation in this system is the use of a self-supervised camera link model. This model automatically discovers the important connections between different cameras, without the need for manual annotation of spatial-temporal relationships. It does this by evaluating feature similarities, pair counts, and time differences to calculate the probability that pairs of cameras are linked. The highest-scoring camera pairs are then used to establish the camera links.
This automated process significantly reduces the time and effort required to deploy the system, making it much more practical and cost-effective for real-world use compared to approaches that rely on manual annotation.
Technical Explanation
The proposed MTMCT system uses a self-supervised camera link model to automatically extract the crucial multi-camera relationships needed for effective vehicle matching. In contrast to related work that relies on manual spatial-temporal annotations, this model evaluates feature similarities, pair numbers, and time variance to calculate the probability of spatial linkage for all camera combinations. The highest scoring camera pairs are then selected to create the camera links.
This pre-matching process supports cross-camera matching by establishing spatial-temporal constraints, which reduces the search space for potential vehicle matches. According to the experimental results, the proposed method achieves state-of-the-art performance on the CityFlow V2 benchmark, with a 61.07% IDF1 score for automatic camera-link based methods.
Critical Analysis
The paper presents a novel and practical approach to the challenging problem of multi-target multi-camera vehicle tracking. The self-supervised camera link model is a clever solution that eliminates the need for manual annotation, significantly improving deployment times and cost-effectiveness.
However, the paper does not discuss any potential limitations or caveats of the proposed system. For example, it's unclear how the method would perform in more complex environments with occlusions, lighting changes, or a large number of cameras. Additionally, the paper does not explore potential biases or failure modes that could arise from the automated camera link discovery process.
Further research could investigate the robustness of the system to different real-world conditions, as well as ways to provide transparency and interpretability into the camera link model's decision-making. Comparing the performance to approaches that use manual annotations could also help contextualize the advantages and trade-offs of the self-supervised approach.
Conclusion
This paper introduces an innovative MTMCT system that uses a self-supervised camera link model to automatically establish the crucial multi-camera relationships needed for effective vehicle matching. By eliminating the need for manual annotation, the proposed method significantly improves deployment times and cost-effectiveness, making it a highly practical solution for real-world applications like traffic management and crash detection.
The experimental results demonstrate state-of-the-art performance on the CityFlow V2 benchmark, highlighting the potential of this approach to advance the field of multi-target multi-camera tracking. While the paper does not explore potential limitations, the core idea of automated camera link discovery is a promising direction for further research and development in this important area of computer vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
City-Scale Multi-Camera Vehicle Tracking System with Improved Self-Supervised Camera Link Model
Yuqiang Lin, Sam Lockyer, Adrian Evans, Markus Zarbock, Nic Zhang
Multi-Target Multi-Camera Tracking (MTMCT) has broad applications and forms the basis for numerous future city-wide systems (e.g. traffic management, crash detection, etc.). However, the challenge of matching vehicle trajectories across different cameras based solely on feature extraction poses significant difficulties. This article introduces an innovative multi-camera vehicle tracking system that utilizes a self-supervised camera link model. In contrast to related works that rely on manual spatial-temporal annotations, our model automatically extracts crucial multi-camera relationships for vehicle matching. The camera link is established through a pre-matching process that evaluates feature similarities, pair numbers, and time variance for high-quality tracks. This process calculates the probability of spatial linkage for all camera combinations, selecting the highest scoring pairs to create camera links. Our approach significantly improves deployment times by eliminating the need for human annotation, offering substantial improvements in efficiency and cost-effectiveness when it comes to real-world application. This pairing process supports cross camera matching by setting spatial-temporal constraints, reducing the searching space for potential vehicle matches. According to our experimental results, the proposed method achieves a new state-of-the-art among automatic camera-link based methods in CityFlow V2 benchmarks with 61.07% IDF1 Score.
Read more7/10/2024
0
Towards Effective Multi-Moving-Camera Tracking: A New Dataset and Lightweight Link Model
Yanting Zhang, Shuanghong Wang, Qingxiang Wang, Cairong Yan, Rui Fan
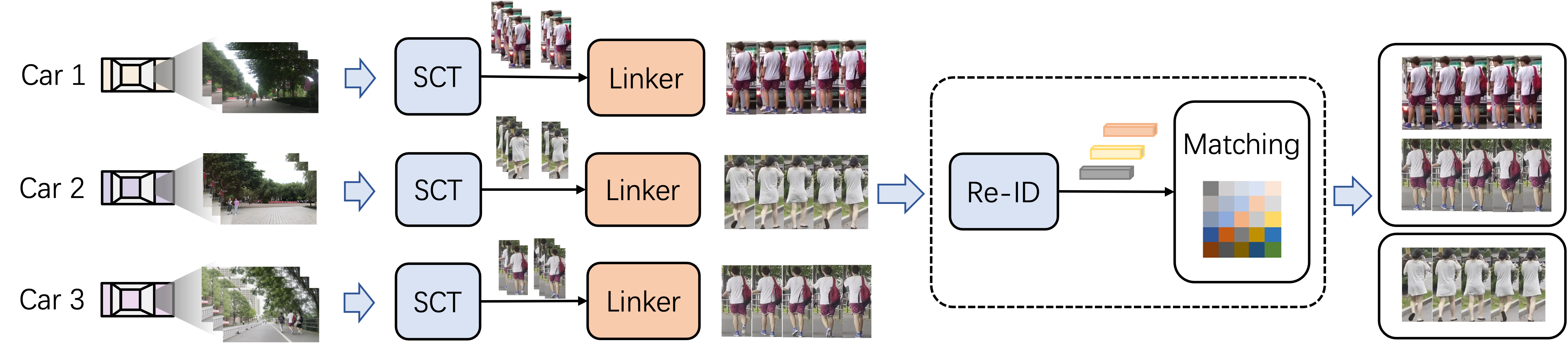
Ensuring driving safety for autonomous vehicles has become increasingly crucial, highlighting the need for systematic tracking of on-road pedestrians. Most vehicles are equipped with visual sensors, however, the large-scale visual data has not been well studied yet. Multi-target multi-camera (MTMC) tracking systems are composed of two modules: single-camera tracking (SCT) and inter-camera tracking (ICT). To reliably coordinate between them, MTMC tracking has been a very complicated task, while tracking across multiple moving cameras makes it even more challenging. In this paper, we focus on multi-target multi-moving-camera (MTMMC) tracking, which is attracting increasing attention from the research community. Observing there are few datasets for MTMMC tracking, we collect a new dataset, called Multi-Moving-Camera Track (MMCT), which contains sequences under various driving scenarios. To address the common problems of identity switch easily faced by most existing SCT trackers, especially for moving cameras due to ego-motion between the camera and targets, a lightweight appearance-free global link model, called Linker, is proposed to mitigate the identity switch by associating two disjoint tracklets of the same target into a complete trajectory within the same camera. Incorporated with Linker, existing SCT trackers generally obtain a significant improvement. Moreover, to alleviate the impact of the image style variations caused by different cameras, a color transfer module is effectively incorporated to extract cross-camera consistent appearance features for pedestrian association across moving cameras for ICT, resulting in a much improved MTMMC tracking system, which can constitute a step further towards coordinated mining of multiple moving cameras. The project page is available at https://dhu-mmct.github.io/.
Read more4/24/2024

0
GMT: A Robust Global Association Model for Multi-Target Multi-Camera Tracking
Huijie Fan, Tinghui Zhao, Qiang Wang, Baojie Fan, Yandong Tang, LianQing Liu
In the task of multi-target multi-camera (MTMC) tracking of pedestrians, the data association problem is a key issue and main challenge, especially with complications arising from camera movements, lighting variations, and obstructions. However, most MTMC models adopt two-step approaches, thus heavily depending on the results of the first-step tracking in practical applications. Moreover, the same targets crossing different cameras may exhibit significant appearance variations, which further increases the difficulty of cross-camera matching. To address the aforementioned issues, we propose a global online MTMC tracking model that addresses the dependency on the first tracking stage in two-step methods and enhances cross-camera matching. Specifically, we propose a transformer-based global MTMC association module to explore target associations across different cameras and frames, generating global trajectories directly. Additionally, to integrate the appearance and spatio-temporal features of targets, we propose a feature extraction and fusion module for MTMC tracking. This module enhances feature representation and establishes correlations between the features of targets across multiple cameras. To accommodate high scene diversity and complex lighting condition variations, we have established the VisionTrack dataset, which enables the development of models that are more generalized and robust to various environments. Our model demonstrates significant improvements over comparison methods on the VisionTrack dataset and others.
Read more7/2/2024

0
Deep Learning-Based Robust Multi-Object Tracking via Fusion of mmWave Radar and Camera Sensors
Lei Cheng, Arindam Sengupta, Siyang Cao
Autonomous driving holds great promise in addressing traffic safety concerns by leveraging artificial intelligence and sensor technology. Multi-Object Tracking plays a critical role in ensuring safer and more efficient navigation through complex traffic scenarios. This paper presents a novel deep learning-based method that integrates radar and camera data to enhance the accuracy and robustness of Multi-Object Tracking in autonomous driving systems. The proposed method leverages a Bi-directional Long Short-Term Memory network to incorporate long-term temporal information and improve motion prediction. An appearance feature model inspired by FaceNet is used to establish associations between objects across different frames, ensuring consistent tracking. A tri-output mechanism is employed, consisting of individual outputs for radar and camera sensors and a fusion output, to provide robustness against sensor failures and produce accurate tracking results. Through extensive evaluations of real-world datasets, our approach demonstrates remarkable improvements in tracking accuracy, ensuring reliable performance even in low-visibility scenarios.
Read more7/12/2024