Going Forward-Forward in Distributed Deep Learning

0

Sign in to get full access
Overview
- The paper proposes a new algorithm called "Forward-Forward" (F2) for distributed deep learning
- F2 aims to reduce communication overhead and improve efficiency in large-scale distributed deep learning systems
- The algorithm leverages a forward-forward approach to training, which reduces the need for full model updates and gradient exchanges
Plain English Explanation
The paper introduces a new technique called the Forward-Forward algorithm for training deep learning models in a distributed setting. In traditional distributed deep learning, multiple machines or "workers" collaborate to train a single model. This requires frequently sharing large amounts of data, like model parameters and gradients, between the workers, which can be slow and inefficient, especially when working with very large models.
The Forward-Forward algorithm aims to address this by using a different approach. Instead of sharing full model updates, the workers only share a small amount of information needed to update the model. This reduces the overall communication overhead and speeds up the training process.
The key idea is that each worker performs a "forward-forward" pass, where they calculate both the model output and the gradients needed to update the model. They then share just the gradients, rather than the full model parameters. This allows the central coordinator to update the model without needing to receive the complete model from each worker.
Technical Explanation
The Forward-Forward algorithm works as follows:
- The central coordinator (e.g. parameter server) initializes the model parameters.
- Workers receive the initial parameters, perform a forward and backward pass on their local data, and send the gradients back to the coordinator.
- The coordinator aggregates the gradients (e.g. using FedAgg) and updates the model parameters.
- The updated parameters are sent back to the workers.
- Workers perform another forward-forward pass using the new parameters and send the gradients to the coordinator.
- Steps 3-5 are repeated until convergence.
This approach reduces the amount of data that needs to be communicated between the workers and the coordinator, as only the gradients are shared, not the full model parameters. The authors show that this can lead to significant improvements in communication efficiency, especially for large-scale distributed training.
The paper also explores extensions of the F2 algorithm, such as cross-silo federated learning and quantum-inspired federated learning, which further improve the scalability and applicability of the approach.
Critical Analysis
The Forward-Forward algorithm presents a promising approach to improving the efficiency of large-scale distributed deep learning. By reducing the communication overhead, the method can significantly speed up training, especially for very large models.
One potential limitation mentioned in the paper is that the approach may not be as effective for non-convex optimization problems, where the gradients shared by the workers may not accurately represent the true gradient of the global objective function. The authors suggest that further research is needed to understand the theoretical properties and convergence guarantees of the F2 algorithm in such scenarios.
Additionally, the paper does not extensively explore the practical considerations of deploying the F2 algorithm in real-world distributed systems, such as the impact of heterogeneous worker hardware, network latency, or fault tolerance. These are important factors that would need to be addressed for the algorithm to be widely adopted in production environments.
Overall, the Forward-Forward algorithm represents an interesting and potentially impactful contribution to the field of distributed deep learning. The reduced communication requirements could enable more efficient training of large-scale models, but further research is needed to fully understand the algorithm's capabilities and limitations.
Conclusion
The Forward-Forward algorithm proposed in this paper offers a novel approach to improving the efficiency of distributed deep learning. By reducing the amount of data that needs to be communicated between workers and the central coordinator, the method can significantly speed up the training process, especially for large-scale models.
While the paper presents promising results and interesting extensions of the algorithm, there are still some open questions and practical considerations that would need to be addressed for the F2 approach to be widely adopted. Nevertheless, this research represents an important step forward in the ongoing effort to make distributed deep learning more scalable and efficient.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Going Forward-Forward in Distributed Deep Learning
Ege Aktemur, Ege Zorlutuna, Kaan Bilgili, Tacettin Emre Bok, Berrin Yanikoglu, Suha Orhun Mutluergil
We introduce a new approach in distributed deep learning, utilizing Geoffrey Hinton's Forward-Forward (FF) algorithm to speed up the training of neural networks in distributed computing environments. Unlike traditional methods that rely on forward and backward passes, the FF algorithm employs a dual forward pass strategy, significantly diverging from the conventional backpropagation process. This novel method aligns more closely with the human brain's processing mechanisms, potentially offering a more efficient and biologically plausible approach to neural network training. Our research explores different implementations of the FF algorithm in distributed settings, to explore its capacity for parallelization. While the original FF algorithm focused on its ability to match the performance of the backpropagation algorithm, the parallelism aims to reduce training times and resource consumption, thereby addressing the long training times associated with the training of deep neural networks. Our evaluation shows a 3.75 times speed up on MNIST dataset without compromising accuracy when training a four-layer network with four compute nodes. The integration of the FF algorithm into distributed deep learning represents a significant step forward in the field, potentially revolutionizing the way neural networks are trained in distributed environments.
Read more5/10/2024

0
Distance-Forward Learning: Enhancing the Forward-Forward Algorithm Towards High-Performance On-Chip Learning
Yujie Wu, Siyuan Xu, Jibin Wu, Lei Deng, Mingkun Xu, Qinghao Wen, Guoqi Li
The Forward-Forward (FF) algorithm was recently proposed as a local learning method to address the limitations of backpropagation (BP), offering biological plausibility along with memory-efficient and highly parallelized computational benefits. However, it suffers from suboptimal performance and poor generalization, largely due to inadequate theoretical support and a lack of effective learning strategies. In this work, we reformulate FF using distance metric learning and propose a distance-forward algorithm (DF) to improve FF performance in supervised vision tasks while preserving its local computational properties, making it competitive for efficient on-chip learning. To achieve this, we reinterpret FF through the lens of centroid-based metric learning and develop a goodness-based N-pair margin loss to facilitate the learning of discriminative features. Furthermore, we integrate layer-collaboration local update strategies to reduce information loss caused by greedy local parameter updates. Our method surpasses existing FF models and other advanced local learning approaches, with accuracies of 99.7% on MNIST, 88.2% on CIFAR-10, 59% on CIFAR-100, 95.9% on SVHN, and 82.5% on ImageNette, respectively. Moreover, it achieves comparable performance with less than 40% memory cost compared to BP training, while exhibiting stronger robustness to multiple types of hardware-related noise, demonstrating its potential for online learning and energy-efficient computation on neuromorphic chips.
Read more8/28/2024
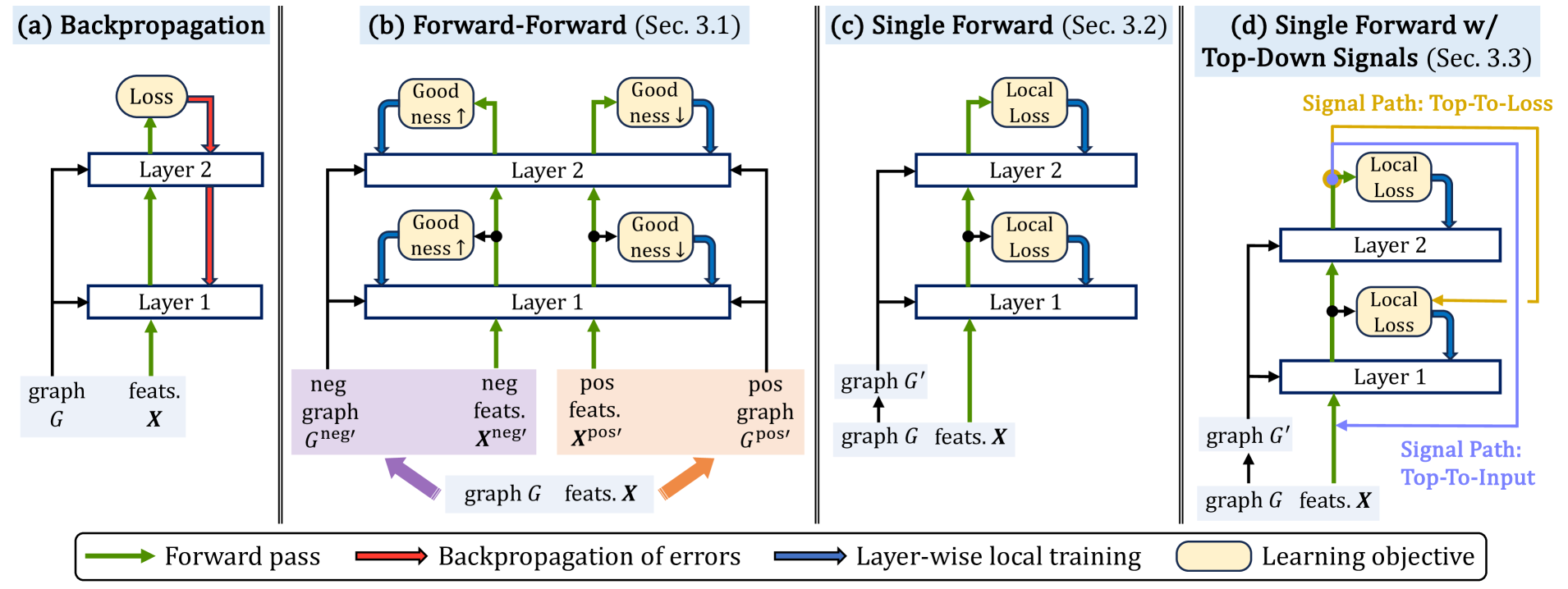
0
Forward Learning of Graph Neural Networks
Namyong Park, Xing Wang, Antoine Simoulin, Shuai Yang, Grey Yang, Ryan Rossi, Puja Trivedi, Nesreen Ahmed
Graph neural networks (GNNs) have achieved remarkable success across a wide range of applications, such as recommendation, drug discovery, and question answering. Behind the success of GNNs lies the backpropagation (BP) algorithm, which is the de facto standard for training deep neural networks (NNs). However, despite its effectiveness, BP imposes several constraints, which are not only biologically implausible, but also limit the scalability, parallelism, and flexibility in learning NNs. Examples of such constraints include storage of neural activities computed in the forward pass for use in the subsequent backward pass, and the dependence of parameter updates on non-local signals. To address these limitations, the forward-forward algorithm (FF) was recently proposed as an alternative to BP in the image classification domain, which trains NNs by performing two forward passes over positive and negative data. Inspired by this advance, we propose ForwardGNN in this work, a new forward learning procedure for GNNs, which avoids the constraints imposed by BP via an effective layer-wise local forward training. ForwardGNN extends the original FF to deal with graph data and GNNs, and makes it possible to operate without generating negative inputs (hence no longer forward-forward). Further, ForwardGNN enables each layer to learn from both the bottom-up and top-down signals without relying on the backpropagation of errors. Extensive experiments on real-world datasets show the effectiveness and generality of the proposed forward graph learning framework. We release our code at https://github.com/facebookresearch/forwardgnn.
Read more4/16/2024
🤷
0
Employing Layerwised Unsupervised Learning to Lessen Data and Loss Requirements in Forward-Forward Algorithms
Taewook Hwang, Hyein Seo, Sangkeun Jung
Recent deep learning models such as ChatGPT utilizing the back-propagation algorithm have exhibited remarkable performance. However, the disparity between the biological brain processes and the back-propagation algorithm has been noted. The Forward-Forward algorithm, which trains deep learning models solely through the forward pass, has emerged to address this. Although the Forward-Forward algorithm cannot replace back-propagation due to limitations such as having to use special input and loss functions, it has the potential to be useful in special situations where back-propagation is difficult to use. To work around this limitation and verify usability, we propose an Unsupervised Forward-Forward algorithm. Using an unsupervised learning model enables training with usual loss functions and inputs without restriction. Through this approach, we lead to stable learning and enable versatile utilization across various datasets and tasks. From a usability perspective, given the characteristics of the Forward-Forward algorithm and the advantages of the proposed method, we anticipate its practical application even in scenarios such as federated learning, where deep learning layers need to be trained separately in physically distributed environments.
Read more4/24/2024