Goldfish: An Efficient Federated Unlearning Framework

0
Sign in to get full access
Overview
- This paper presents "Goldfish," an efficient federated unlearning framework for machine learning models.
- Federated unlearning allows users to request the removal of their data from trained models, which is important for privacy and compliance.
- Goldfish aims to make federated unlearning more efficient by using a distillation model to quickly retrain the model after removing user data.
Plain English Explanation
Goldfish is a new system designed to make it easier for machine learning models to "forget" data from individual users. In many applications, users may want to request that their personal data be removed from a model, for privacy or regulatory reasons. This process, called "federated unlearning," can be time-consuming and computationally expensive.
Goldfish addresses this by using a clever technique called "distillation." Instead of retraining the entire model from scratch after removing user data, Goldfish creates a smaller "distillation model" that captures the key knowledge from the original model. This distillation model can then be used to efficiently retrain the main model, saving a significant amount of time and computational resources.
The researchers demonstrate that Goldfish can achieve high accuracy on benchmark machine learning tasks, while drastically reducing the cost of federated unlearning compared to conventional methods. This could make it much easier for companies and organizations to quickly remove user data from their models when requested, improving privacy and regulatory compliance.
Technical Explanation
The paper introduces the Goldfish framework for efficient federated unlearning. In federated unlearning, users can request the removal of their data from a centralized machine learning model. This is an important capability for privacy and compliance reasons. However, conventional federated unlearning approaches require retraining the entire model from scratch, which can be computationally expensive.
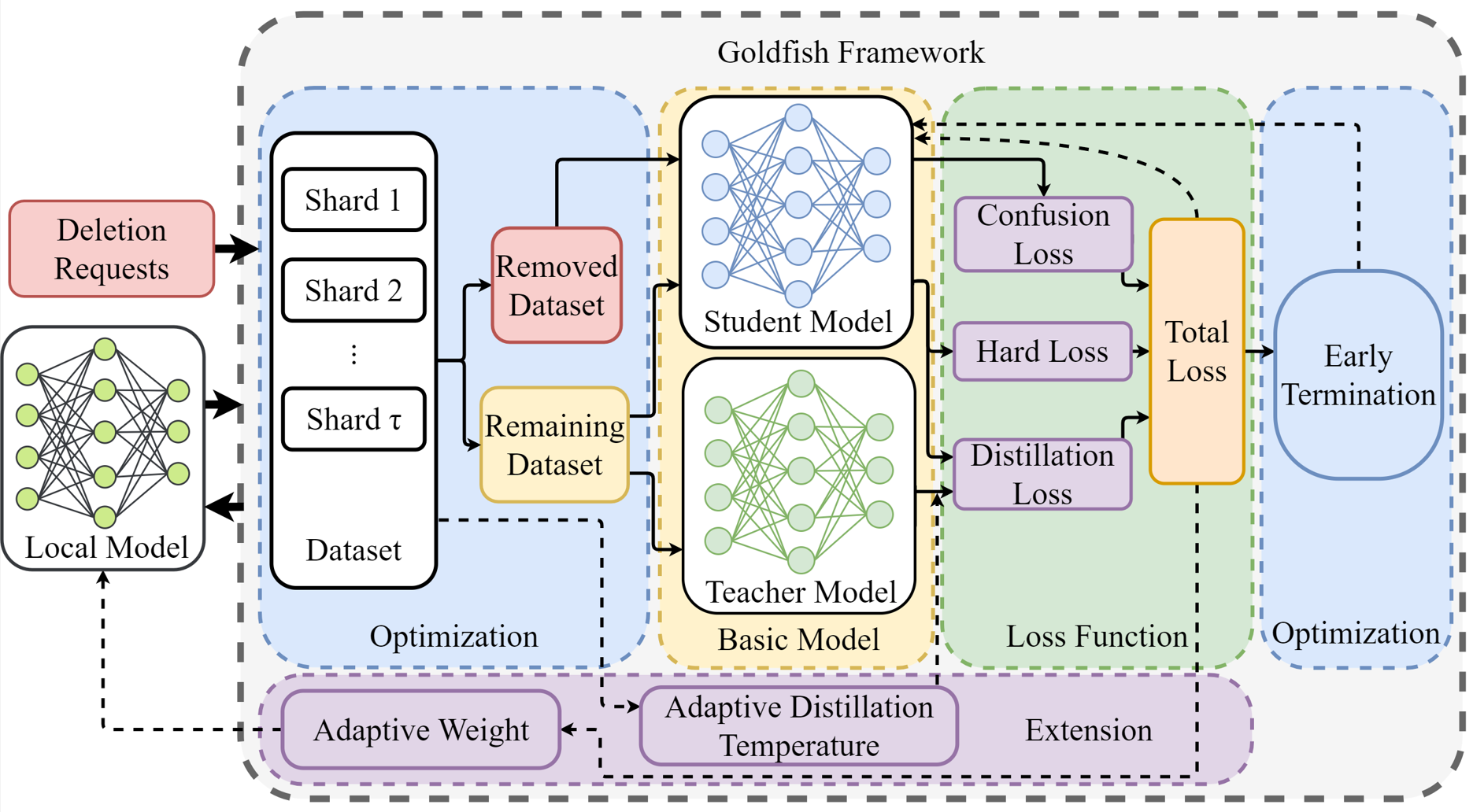
Goldfish addresses this by using a distillation-based approach. After a user's data is removed, Goldfish creates a small "distillation model" that captures the core knowledge of the original model. This distillation model is then used to efficiently retrain the main model, significantly reducing the computational cost of the unlearning process.
The authors evaluate Goldfish on several benchmark machine learning tasks, including image classification and language modeling. They show that Goldfish can match the accuracy of models trained from scratch, while reducing the unlearning time by over 90% compared to standard federated unlearning techniques.
Critical Analysis
The Goldfish framework represents an innovative approach to the important problem of federated unlearning. By leveraging distillation, the authors have developed a method that can dramatically reduce the computational resources required to remove user data from machine learning models.
That said, the paper does not address some potential limitations and concerns. For example, it is unclear how well Goldfish would scale to extremely large models or datasets. The distillation process itself may also introduce some accuracy degradation, which could be a concern in high-stakes applications.
Additionally, the paper does not explore the security or privacy implications of the Goldfish approach. While it enables efficient unlearning, there may be vulnerabilities or side-effects that need to be carefully considered, especially when dealing with sensitive user data.
Overall, Goldfish represents an important and promising step forward for federated unlearning. However, further research is needed to fully understand the capabilities and limitations of this approach, as well as its broader implications for machine learning system design and user privacy.
Conclusion
The Goldfish framework presented in this paper offers an efficient solution for federated unlearning, a critical capability for preserving user privacy and meeting regulatory requirements in machine learning systems. By leveraging a distillation-based approach, Goldfish can drastically reduce the computational cost of removing user data from trained models, while maintaining high accuracy.
This innovation has the potential to make it much easier for companies and organizations to honor user requests to delete their data, improving data protection and building greater trust in AI-powered services. As machine learning systems become increasingly ubiquitous, efficient federated unlearning will only grow in importance. The Goldfish framework represents an important step forward in this direction, and its insights could inspire further advancements in this crucial area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Goldfish: An Efficient Federated Unlearning Framework
Houzhe Wang, Xiaojie Zhu, Chi Chen, Paulo Esteves-Ver'issimo
With recent legislation on the right to be forgotten, machine unlearning has emerged as a crucial research area. It facilitates the removal of a user's data from federated trained machine learning models without the necessity for retraining from scratch. However, current machine unlearning algorithms are confronted with challenges of efficiency and validity. To address the above issues, we propose a new framework, named Goldfish. It comprises four modules: basic model, loss function, optimization, and extension. To address the challenge of low validity in existing machine unlearning algorithms, we propose a novel loss function. It takes into account the loss arising from the discrepancy between predictions and actual labels in the remaining dataset. Simultaneously, it takes into consideration the bias of predicted results on the removed dataset. Moreover, it accounts for the confidence level of predicted results. Additionally, to enhance efficiency, we adopt knowledge a distillation technique in the basic model and introduce an optimization module that encompasses the early termination mechanism guided by empirical risk and the data partition mechanism. Furthermore, to bolster the robustness of the aggregated model, we propose an extension module that incorporates a mechanism using adaptive distillation temperature to address the heterogeneity of user local data and a mechanism using adaptive weight to handle the variety in the quality of uploaded models. Finally, we conduct comprehensive experiments to illustrate the effectiveness of proposed approach.
Read more4/24/2024
🏅
0
Unlearning during Learning: An Efficient Federated Machine Unlearning Method
Hanlin Gu, Gongxi Zhu, Jie Zhang, Xinyuan Zhao, Yuxing Han, Lixin Fan, Qiang Yang
In recent years, Federated Learning (FL) has garnered significant attention as a distributed machine learning paradigm. To facilitate the implementation of the right to be forgotten, the concept of federated machine unlearning (FMU) has also emerged. However, current FMU approaches often involve additional time-consuming steps and may not offer comprehensive unlearning capabilities, which renders them less practical in real FL scenarios. In this paper, we introduce FedAU, an innovative and efficient FMU framework aimed at overcoming these limitations. Specifically, FedAU incorporates a lightweight auxiliary unlearning module into the learning process and employs a straightforward linear operation to facilitate unlearning. This approach eliminates the requirement for extra time-consuming steps, rendering it well-suited for FL. Furthermore, FedAU exhibits remarkable versatility. It not only enables multiple clients to carry out unlearning tasks concurrently but also supports unlearning at various levels of granularity, including individual data samples, specific classes, and even at the client level. We conducted extensive experiments on MNIST, CIFAR10, and CIFAR100 datasets to evaluate the performance of FedAU. The results demonstrate that FedAU effectively achieves the desired unlearning effect while maintaining model accuracy.
Read more5/27/2024
0
Federated Learning driven Large Language Models for Swarm Intelligence: A Survey
Youyang Qu
Federated learning (FL) offers a compelling framework for training large language models (LLMs) while addressing data privacy and decentralization challenges. This paper surveys recent advancements in the federated learning of large language models, with a particular focus on machine unlearning, a crucial aspect for complying with privacy regulations like the Right to be Forgotten. Machine unlearning in the context of federated LLMs involves systematically and securely removing individual data contributions from the learned model without retraining from scratch. We explore various strategies that enable effective unlearning, such as perturbation techniques, model decomposition, and incremental learning, highlighting their implications for maintaining model performance and data privacy. Furthermore, we examine case studies and experimental results from recent literature to assess the effectiveness and efficiency of these approaches in real-world scenarios. Our survey reveals a growing interest in developing more robust and scalable federated unlearning methods, suggesting a vital area for future research in the intersection of AI ethics and distributed machine learning technologies.
Read more6/17/2024

0
Fast-FedUL: A Training-Free Federated Unlearning with Provable Skew Resilience
Thanh Trung Huynh, Trong Bang Nguyen, Phi Le Nguyen, Thanh Tam Nguyen, Matthias Weidlich, Quoc Viet Hung Nguyen, Karl Aberer
Federated learning (FL) has recently emerged as a compelling machine learning paradigm, prioritizing the protection of privacy for training data. The increasing demand to address issues such as ``the right to be forgotten'' and combat data poisoning attacks highlights the importance of techniques, known as textit{unlearning}, which facilitate the removal of specific training data from trained FL models. Despite numerous unlearning methods proposed for centralized learning, they often prove inapplicable to FL due to fundamental differences in the operation of the two learning paradigms. Consequently, unlearning in FL remains in its early stages, presenting several challenges. Many existing unlearning solutions in FL require a costly retraining process, which can be burdensome for clients. Moreover, these methods are primarily validated through experiments, lacking theoretical assurances. In this study, we introduce Fast-FedUL, a tailored unlearning method for FL, which eliminates the need for retraining entirely. Through meticulous analysis of the target client's influence on the global model in each round, we develop an algorithm to systematically remove the impact of the target client from the trained model. In addition to presenting empirical findings, we offer a theoretical analysis delineating the upper bound of our unlearned model and the exact retrained model (the one obtained through retraining using untargeted clients). Experimental results with backdoor attack scenarios indicate that Fast-FedUL effectively removes almost all traces of the target client, while retaining the knowledge of untargeted clients (obtaining a high accuracy of up to 98% on the main task). Significantly, Fast-FedUL attains the lowest time complexity, providing a speed that is 1000 times faster than retraining. Our source code is publicly available at url{https://github.com/thanhtrunghuynh93/fastFedUL}.
Read more5/29/2024