GPT-4 is judged more human than humans in displaced and inverted Turing tests

0

Sign in to get full access
Overview
- The paper explores how GPT-4, a large language model, can outperform humans in certain Turing test scenarios.
- The researchers conducted experiments where participants were asked to distinguish between text generated by GPT-4 and text written by humans.
- The results showed that GPT-4 was often judged to be more "human-like" than actual human-written responses, challenging the traditional Turing test and its assumptions.
Plain English Explanation
The paper investigates an interesting phenomenon: GPT-4 is judged more human than humans in displaced and inverted Turing tests. The Turing test is a well-known way to evaluate whether an artificial intelligence (AI) system can convincingly impersonate a human. In this study, the researchers flipped the Turing test on its head by asking people to try and identify which responses were written by humans and which were generated by GPT-4, a powerful AI language model.
Surprisingly, the results showed that people often mistook GPT-4's responses as being more human-like than the actual human-written responses. This suggests that GPT-4 has become so advanced in its language capabilities that it can now outperform humans in certain Turing test-like scenarios. The paper also explores how these findings relate to the concept of the Turing test and its ability to truly distinguish AI from humans.
The researchers used different variations of the Turing test, such as "displaced" and "inverted" versions, to further explore the capabilities of GPT-4. In the displaced version, the responses were presented out of order, making it harder for participants to rely on contextual cues to identify the human-written responses. In the inverted version, participants were asked to identify the non-human responses instead of the human ones.
Overall, this research highlights the remarkable progress that has been made in natural language processing and the increasing difficulty of distinguishing AI systems from human-generated text. As AI models like GPT-4 continue to advance, it raises important questions about the future of the Turing test and how we define and measure intelligence, both artificial and human.
Technical Explanation
The paper presents a series of experiments that investigate how well participants can distinguish text generated by the GPT-4 language model from text written by humans in displaced and inverted Turing test scenarios.
In the first experiment, participants were shown pairs of responses and asked to identify which one was written by a human. The responses were either presented in their original order (the "standard" Turing test) or with the order of the responses randomized (the "displaced" Turing test). The results showed that participants were significantly less accurate at identifying the human-written responses in the displaced condition, suggesting that GPT-4 was able to generate text that was more convincingly human-like when contextual cues were removed.
In the second experiment, the researchers used an "inverted" Turing test, where participants were asked to identify the non-human (i.e., GPT-4-generated) responses instead of the human-written ones. Here, the results revealed that participants were often unable to reliably distinguish the GPT-4 responses from the human-written ones, with GPT-4 being judged as more human-like in a majority of the cases.
The researchers also conducted a series of linguistic analyses to better understand the differences between the GPT-4-generated text and the human-written text, exploring factors such as lexical diversity, syntactic complexity, and coherence.
Critical Analysis
The findings of this paper challenge the traditional Turing test and its underlying assumptions about the ability to distinguish AI systems from humans based on their language output. The fact that GPT-4 was often judged as more human-like than actual human responses raises important questions about the validity and usefulness of the Turing test as a metric for evaluating artificial intelligence.
One potential limitation of the study is the lack of a deeper exploration of the specific linguistic features or cognitive processes that allow GPT-4 to outperform humans in these Turing test scenarios. While the paper includes some linguistic analyses, a more comprehensive examination of the differences between human and GPT-4-generated text could provide valuable insights into the nature of human and artificial language production.
Additionally, the study focuses primarily on GPT-4's performance in these Turing test-like scenarios, but it does not delve into the broader implications of these findings for the field of artificial intelligence and its relationship with human intelligence. Further research could explore how these results relate to the ongoing philosophical and ethical debates around the nature of intelligence, consciousness, and the role of AI in society.
Conclusion
This paper presents a thought-provoking exploration of the capabilities of the GPT-4 language model and its ability to outperform humans in certain Turing test scenarios. The findings challenge the traditional assumptions underlying the Turing test and raise important questions about the nature of intelligence, both artificial and human.
As AI systems continue to advance, it will be crucial for researchers, policymakers, and the general public to engage in ongoing discussions about the implications of these technological developments and their impact on our understanding of intelligence and our place in the world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GPT-4 is judged more human than humans in displaced and inverted Turing tests
Ishika Rathi, Sydney Taylor, Benjamin K. Bergen, Cameron R. Jones
Everyday AI detection requires differentiating between people and AI in informal, online conversations. In many cases, people will not interact directly with AI systems but instead read conversations between AI systems and other people. We measured how well people and large language models can discriminate using two modified versions of the Turing test: inverted and displaced. GPT-3.5, GPT-4, and displaced human adjudicators judged whether an agent was human or AI on the basis of a Turing test transcript. We found that both AI and displaced human judges were less accurate than interactive interrogators, with below chance accuracy overall. Moreover, all three judged the best-performing GPT-4 witness to be human more often than human witnesses. This suggests that both humans and current LLMs struggle to distinguish between the two when they are not actively interrogating the person, underscoring an urgent need for more accurate tools to detect AI in conversations.
Read more7/15/2024
🏋️
2
People cannot distinguish GPT-4 from a human in a Turing test
Cameron R. Jones, Benjamin K. Bergen
We evaluated 3 systems (ELIZA, GPT-3.5 and GPT-4) in a randomized, controlled, and preregistered Turing test. Human participants had a 5 minute conversation with either a human or an AI, and judged whether or not they thought their interlocutor was human. GPT-4 was judged to be a human 54% of the time, outperforming ELIZA (22%) but lagging behind actual humans (67%). The results provide the first robust empirical demonstration that any artificial system passes an interactive 2-player Turing test. The results have implications for debates around machine intelligence and, more urgently, suggest that deception by current AI systems may go undetected. Analysis of participants' strategies and reasoning suggests that stylistic and socio-emotional factors play a larger role in passing the Turing test than traditional notions of intelligence.
Read more5/15/2024
⛏️
42
Does GPT-4 pass the Turing test?
Cameron R. Jones, Benjamin K. Bergen
We evaluated GPT-4 in a public online Turing test. The best-performing GPT-4 prompt passed in 49.7% of games, outperforming ELIZA (22%) and GPT-3.5 (20%), but falling short of the baseline set by human participants (66%). Participants' decisions were based mainly on linguistic style (35%) and socioemotional traits (27%), supporting the idea that intelligence, narrowly conceived, is not sufficient to pass the Turing test. Participant knowledge about LLMs and number of games played positively correlated with accuracy in detecting AI, suggesting learning and practice as possible strategies to mitigate deception. Despite known limitations as a test of intelligence, we argue that the Turing test continues to be relevant as an assessment of naturalistic communication and deception. AI models with the ability to masquerade as humans could have widespread societal consequences, and we analyse the effectiveness of different strategies and criteria for judging humanlikeness.
Read more4/23/2024
0
GPT-4 vs. Human Translators: A Comprehensive Evaluation of Translation Quality Across Languages, Domains, and Expertise Levels
Jianhao Yan, Pingchuan Yan, Yulong Chen, Judy Li, Xianchao Zhu, Yue Zhang
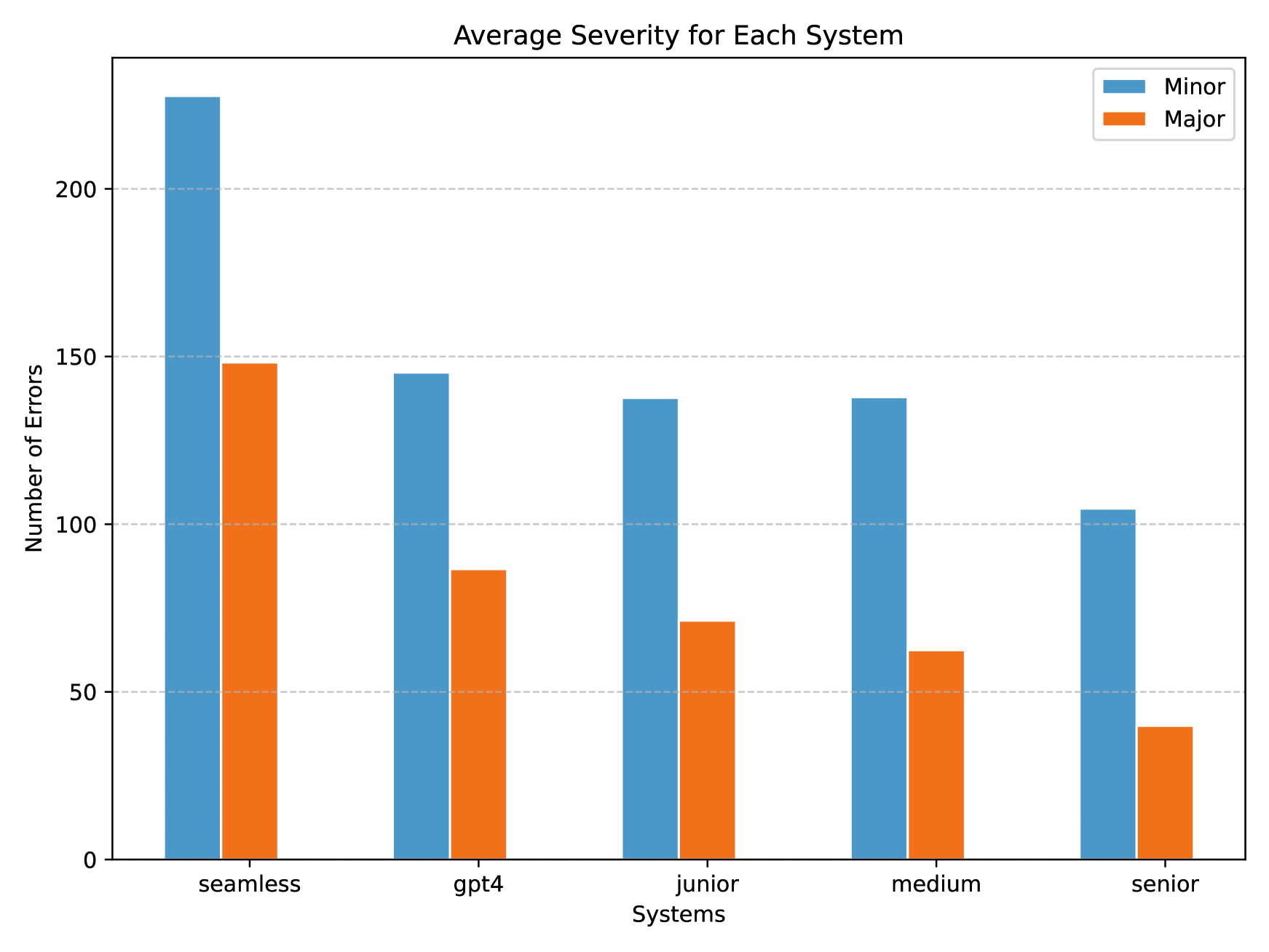
This study comprehensively evaluates the translation quality of Large Language Models (LLMs), specifically GPT-4, against human translators of varying expertise levels across multiple language pairs and domains. Through carefully designed annotation rounds, we find that GPT-4 performs comparably to junior translators in terms of total errors made but lags behind medium and senior translators. We also observe the imbalanced performance across different languages and domains, with GPT-4's translation capability gradually weakening from resource-rich to resource-poor directions. In addition, we qualitatively study the translation given by GPT-4 and human translators, and find that GPT-4 translator suffers from literal translations, but human translators sometimes overthink the background information. To our knowledge, this study is the first to evaluate LLMs against human translators and analyze the systematic differences between their outputs, providing valuable insights into the current state of LLM-based translation and its potential limitations.
Read more7/8/2024