GR-MG: Leveraging Partially Annotated Data via Multi-Modal Goal Conditioned Policy

0

Sign in to get full access
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GR-MG: Leveraging Partially Annotated Data via Multi-Modal Goal Conditioned Policy
Peiyan Li, Hongtao Wu, Yan Huang, Chilam Cheang, Liang Wang, Tao Kong
The robotics community has consistently aimed to achieve generalizable robot manipulation with flexible natural language instructions. One of the primary challenges is that obtaining robot data fully annotated with both actions and texts is time-consuming and labor-intensive. However, partially annotated data, such as human activity videos without action labels and robot play data without language labels, is much easier to collect. Can we leverage these data to enhance the generalization capability of robots? In this paper, we propose GR-MG, a novel method which supports conditioning on both a language instruction and a goal image. During training, GR-MG samples goal images from trajectories and conditions on both the text and the goal image or solely on the image when text is unavailable. During inference, where only the text is provided, GR-MG generates the goal image via a diffusion-based image-editing model and condition on both the text and the generated image. This approach enables GR-MG to leverage large amounts of partially annotated data while still using language to flexibly specify tasks. To generate accurate goal images, we propose a novel progress-guided goal image generation model which injects task progress information into the generation process, significantly improving the fidelity and the performance. In simulation experiments, GR-MG improves the average number of tasks completed in a row of 5 from 3.35 to 4.04. In real-robot experiments, GR-MG is able to perform 47 different tasks and improves the success rate from 62.5% to 75.0% and 42.4% to 57.6% in simple and generalization settings, respectively. Code and checkpoints will be available at the project page: https://gr-mg.github.io/.
Read more8/27/2024
0
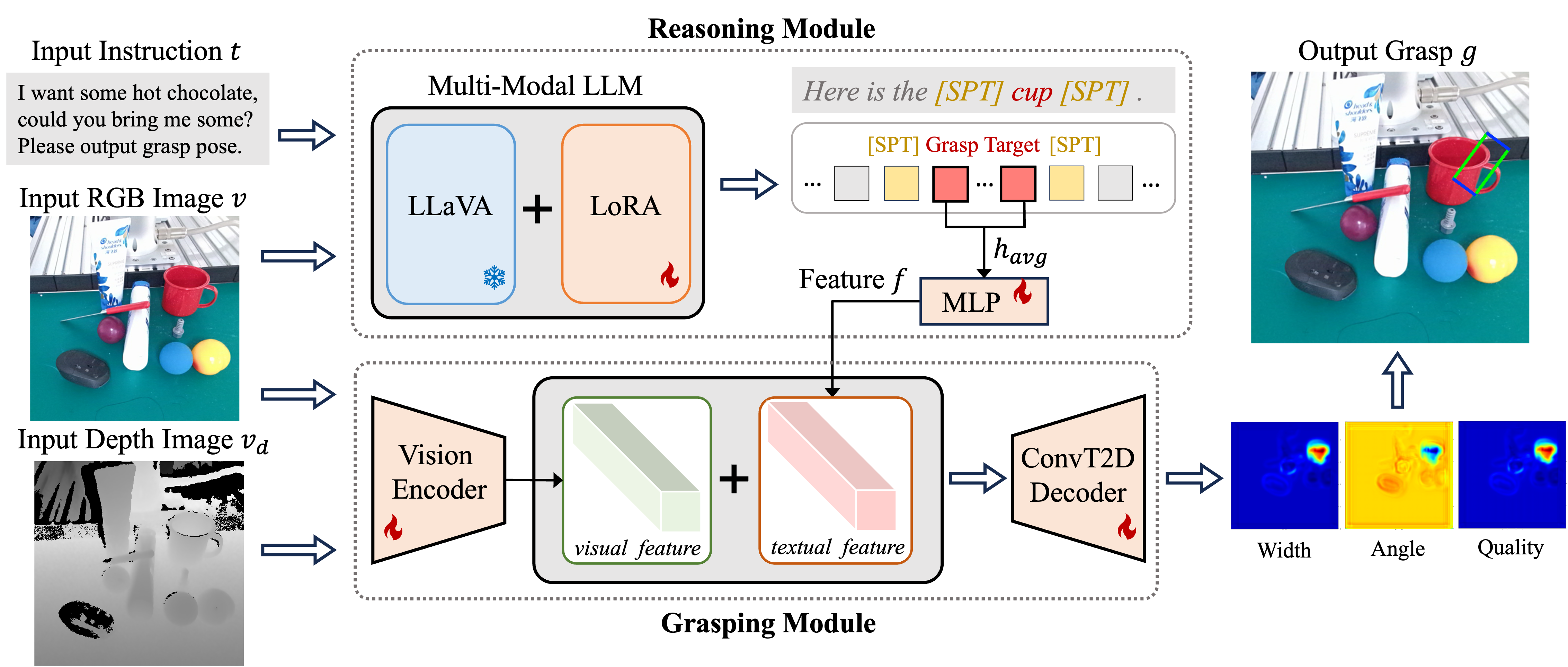
Reasoning Grasping via Multimodal Large Language Model
Shiyu Jin, Jinxuan Xu, Yutian Lei, Liangjun Zhang
Despite significant progress in robotic systems for operation within human-centric environments, existing models still heavily rely on explicit human commands to identify and manipulate specific objects. This limits their effectiveness in environments where understanding and acting on implicit human intentions are crucial. In this study, we introduce a novel task: reasoning grasping, where robots need to generate grasp poses based on indirect verbal instructions or intentions. To accomplish this, we propose an end-to-end reasoning grasping model that integrates a multi-modal Large Language Model (LLM) with a vision-based robotic grasping framework. In addition, we present the first reasoning grasping benchmark dataset generated from the GraspNet-1 billion, incorporating implicit instructions for object-level and part-level grasping, and this dataset will soon be available for public access. Our results show that directly integrating CLIP or LLaVA with the grasp detection model performs poorly on the challenging reasoning grasping tasks, while our proposed model demonstrates significantly enhanced performance both in the reasoning grasping benchmark and real-world experiments.
Read more4/29/2024

0
Multi-objective Cross-task Learning via Goal-conditioned GPT-based Decision Transformers for Surgical Robot Task Automation
Jiawei Fu, Yonghao Long, Kai Chen, Wang Wei, Qi Dou
Surgical robot task automation has been a promising research topic for improving surgical efficiency and quality. Learning-based methods have been recognized as an interesting paradigm and been increasingly investigated. However, existing approaches encounter difficulties in long-horizon goal-conditioned tasks due to the intricate compositional structure, which requires decision-making for a sequence of sub-steps and understanding of inherent dynamics of goal-reaching tasks. In this paper, we propose a new learning-based framework by leveraging the strong reasoning capability of the GPT-based architecture to automate surgical robotic tasks. The key to our approach is developing a goal-conditioned decision transformer to achieve sequential representations with goal-aware future indicators in order to enhance temporal reasoning. Moreover, considering to exploit a general understanding of dynamics inherent in manipulations, thus making the model's reasoning ability to be task-agnostic, we also design a cross-task pretraining paradigm that uses multiple training objectives associated with data from diverse tasks. We have conducted extensive experiments on 10 tasks using the surgical robot learning simulator SurRoL~cite{long2023human}. The results show that our new approach achieves promising performance and task versatility compared to existing methods. The learned trajectories can be deployed on the da Vinci Research Kit (dVRK) for validating its practicality in real surgical robot settings. Our project website is at: https://med-air.github.io/SurRoL.
Read more5/30/2024
🏅
0
GOPlan: Goal-conditioned Offline Reinforcement Learning by Planning with Learned Models
Mianchu Wang, Rui Yang, Xi Chen, Hao Sun, Meng Fang, Giovanni Montana
Offline Goal-Conditioned RL (GCRL) offers a feasible paradigm for learning general-purpose policies from diverse and multi-task offline datasets. Despite notable recent progress, the predominant offline GCRL methods, mainly model-free, face constraints in handling limited data and generalizing to unseen goals. In this work, we propose Goal-conditioned Offline Planning (GOPlan), a novel model-based framework that contains two key phases: (1) pretraining a prior policy capable of capturing multi-modal action distribution within the multi-goal dataset; (2) employing the reanalysis method with planning to generate imagined trajectories for funetuning policies. Specifically, we base the prior policy on an advantage-weighted conditioned generative adversarial network, which facilitates distinct mode separation, mitigating the pitfalls of out-of-distribution (OOD) actions. For further policy optimization, the reanalysis method generates high-quality imaginary data by planning with learned models for both intra-trajectory and inter-trajectory goals. With thorough experimental evaluations, we demonstrate that GOPlan achieves state-of-the-art performance on various offline multi-goal navigation and manipulation tasks. Moreover, our results highlight the superior ability of GOPlan to handle small data budgets and generalize to OOD goals.
Read more5/17/2024