Gradient Boosting Mapping for Dimensionality Reduction and Feature Extraction

0
📉
Sign in to get full access
Overview
- Supervised learning often struggles to find good features or distance measures for the data
- Dimensionality reduction can help by finding a lower-dimensional representation that is easier to work with
- The paper proposes a new method called Gradient Boosting Mapping (GBMAP) that uses the outputs of weak learners to define an embedding
- This embedding can provide better features for supervised learning tasks and a principled distance measure between data points
- GBMAP is fast and can handle large datasets, and its performance is comparable to state-of-the-art methods
Plain English Explanation
In machine learning, one of the fundamental challenges is figuring out the right set of features or ways to measure the distance between data points. If we can find a lower-dimensional representation of the data that is easy to work with, it can make the machine learning model more understandable, reduce the risk of overfitting, and even help detect when the data distribution has changed over time.
The paper introduces a new method called Gradient Boosting Mapping (GBMAP) that addresses this challenge. GBMAP uses the outputs of simple one-layer neural networks, called "weak learners," to define an embedding or lower-dimensional representation of the data. This embedding can provide better features for supervised learning tasks than the original data, allowing simple linear models to perform as well as more complex state-of-the-art methods. The embedding also gives us a principled way to measure the distance between data points, automatically focusing on the directions that are most relevant for the supervised learning task.
An additional benefit of GBMAP is that it can reliably detect when a data point is outside the distribution of the training data, which could indicate a large error in regression or classification. This out-of-distribution detection can be useful for monitoring the performance of a machine learning system in the real world. GBMAP is also very fast, able to process datasets with millions of data points or hundreds of features in just a few seconds.
Technical Explanation
The key idea behind GBMAP is to use the outputs of "weak learners" – simple one-layer neural networks – to define an embedding or lower-dimensional representation of the data. This is similar to the approach used in the CBMAP method for dimensionality reduction. The authors show that this embedding can provide better features for supervised learning tasks than the original high-dimensional data.
To create the embedding, GBMAP trains a series of weak learners, each of which is a simple one-layer perceptron that takes the input data and produces a single output value. The outputs of these weak learners are then used as the coordinates of the low-dimensional embedding. The authors demonstrate that this embedding automatically focuses on the directions in the data that are most relevant for the supervised learning task, similar to the feature-preserving manifold approach.
In addition to providing better features, the GBMAP embedding also allows for the definition of a principled distance measure between data points. This distance measure automatically ignores directions in the data that are irrelevant for the supervised learning task, making it more robust than standard distance metrics like Euclidean distance.
Another interesting aspect of GBMAP is its ability to reliably detect out-of-distribution data points, which could indicate large errors in regression or classification. This is similar to the approach used in the DIMVIS method for interpreting visual clusters in dimensionality reduction.
Critical Analysis
The paper presents a strong and well-designed study, but there are a few potential limitations and areas for further research:
-
Interpretability: While the GBMAP embedding provides better features for supervised learning, the authors don't explore in depth how interpretable the embedding is to human users. Further work could investigate ways to enhance the interpretability of the dimensionality-reduced representations, as in the feature-preserving manifold approach.
-
Generalization: The authors demonstrate the effectiveness of GBMAP on a range of supervised learning tasks, but it would be valuable to see how the method performs on a broader set of datasets and problem domains, especially those with different types of data or more complex relationships between features.
-
Computational Efficiency: While GBMAP is fast for large datasets, the training process still involves training a series of weak learners, which could be computationally intensive for extremely large-scale problems. Exploring ways to further optimize the training process could make the method even more scalable.
-
Robustness to Noise: The paper doesn't extensively explore the method's robustness to noisy or corrupted input data. Understanding how GBMAP's performance might be affected by real-world data quality issues would be an important area for future research.
Overall, the GBMAP method represents a promising approach to supervised dimensionality reduction, with interesting applications in feature engineering, distance metric learning, and out-of-distribution detection. Further research building on this work could lead to even more powerful and versatile tools for machine learning practitioners.
Conclusion
The GBMAP method proposed in this paper addresses a fundamental challenge in supervised learning: finding good features and distance measures for the data. By using the outputs of simple weak learners to define a low-dimensional embedding, GBMAP can provide better features for supervised learning tasks and a principled distance measure between data points.
The key benefits of GBMAP include its ability to automatically focus on the most relevant directions in the data, its reliable detection of out-of-distribution samples, and its computational efficiency even for large datasets. While the method has some potential limitations, such as interpretability and robustness, the paper represents an important contribution to the field of dimensionality reduction and feature engineering for supervised learning.
As machine learning continues to be applied to increasingly complex and high-dimensional datasets, techniques like GBMAP will likely become increasingly valuable for extracting meaningful insights and improving the performance of supervised models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
Gradient Boosting Mapping for Dimensionality Reduction and Feature Extraction
Anri Patron, Ayush Prasad, Hoang Phuc Hau Luu, Kai Puolamaki
A fundamental problem in supervised learning is to find a good set of features or distance measures. If the new set of features is of lower dimensionality and can be obtained by a simple transformation of the original data, they can make the model understandable, reduce overfitting, and even help to detect distribution drift. We propose a supervised dimensionality reduction method Gradient Boosting Mapping (GBMAP), where the outputs of weak learners -- defined as one-layer perceptrons -- define the embedding. We show that the embedding coordinates provide better features for the supervised learning task, making simple linear models competitive with the state-of-the-art regressors and classifiers. We also use the embedding to find a principled distance measure between points. The features and distance measures automatically ignore directions irrelevant to the supervised learning task. We also show that we can reliably detect out-of-distribution data points with potentially large regression or classification errors. GBMAP is fast and works in seconds for dataset of million data points or hundreds of features. As a bonus, GBMAP provides a regression and classification performance comparable to the state-of-the-art supervised learning methods.
Read more5/15/2024
0
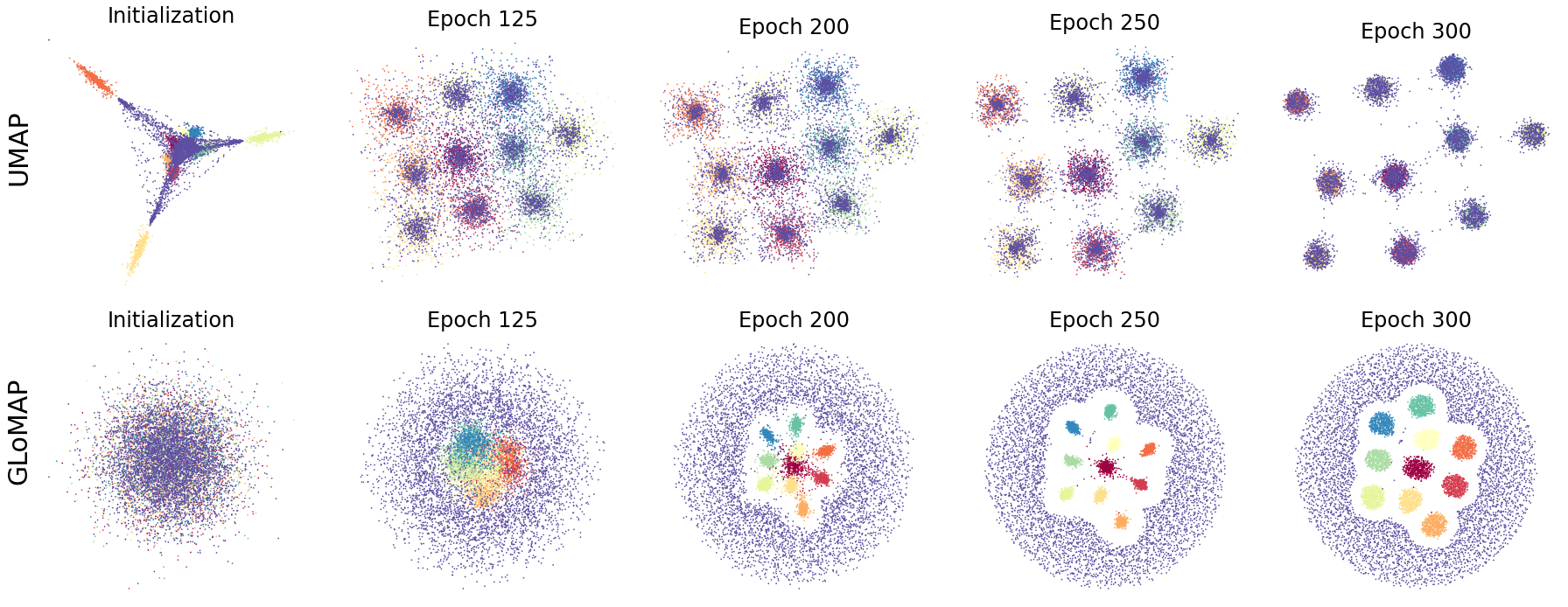
Inductive Global and Local Manifold Approximation and Projection
Jungeum Kim, Xiao Wang
Nonlinear dimensional reduction with the manifold assumption, often called manifold learning, has proven its usefulness in a wide range of high-dimensional data analysis. The significant impact of t-SNE and UMAP has catalyzed intense research interest, seeking further innovations toward visualizing not only the local but also the global structure information of the data. Moreover, there have been consistent efforts toward generalizable dimensional reduction that handles unseen data. In this paper, we first propose GLoMAP, a novel manifold learning method for dimensional reduction and high-dimensional data visualization. GLoMAP preserves locally and globally meaningful distance estimates and displays a progression from global to local formation during the course of optimization. Furthermore, we extend GLoMAP to its inductive version, iGLoMAP, which utilizes a deep neural network to map data to its lower-dimensional representation. This allows iGLoMAP to provide lower-dimensional embeddings for unseen points without needing to re-train the algorithm. iGLoMAP is also well-suited for mini-batch learning, enabling large-scale, accelerated gradient calculations. We have successfully applied both GLoMAP and iGLoMAP to the simulated and real-data settings, with competitive experiments against the state-of-the-art methods.
Read more6/13/2024

0
GNUMAP: A Parameter-Free Approach to Unsupervised Dimensionality Reduction via Graph Neural Networks
Jihee You, So Won Jeong, Claire Donnat
With the proliferation of Graph Neural Network (GNN) methods stemming from contrastive learning, unsupervised node representation learning for graph data is rapidly gaining traction across various fields, from biology to molecular dynamics, where it is often used as a dimensionality reduction tool. However, there remains a significant gap in understanding the quality of the low-dimensional node representations these methods produce, particularly beyond well-curated academic datasets. To address this gap, we propose here the first comprehensive benchmarking of various unsupervised node embedding techniques tailored for dimensionality reduction, encompassing a range of manifold learning tasks, along with various performance metrics. We emphasize the sensitivity of current methods to hyperparameter choices -- highlighting a fundamental issue as to their applicability in real-world settings where there is no established methodology for rigorous hyperparameter selection. Addressing this issue, we introduce GNUMAP, a robust and parameter-free method for unsupervised node representation learning that merges the traditional UMAP approach with the expressivity of the GNN framework. We show that GNUMAP consistently outperforms existing state-of-the-art GNN embedding methods in a variety of contexts, including synthetic geometric datasets, citation networks, and real-world biomedical data -- making it a simple but reliable dimensionality reduction tool.
Read more8/1/2024
📉
0
Interpretable Dimensionality Reduction by Feature Preserving Manifold Approximation and Projection
Yang Yang, Hongjian Sun, Jialei Gong, Di Yu
Nonlinear dimensionality reduction lacks interpretability due to the absence of source features in low-dimensional embedding space. We propose an interpretable method featMAP to preserve source features by tangent space embedding. The core of our proposal is to utilize local singular value decomposition (SVD) to approximate the tangent space which is embedded to low-dimensional space by maintaining the alignment. Based on the embedding tangent space, featMAP enables the interpretability by locally demonstrating the source features and feature importance. Furthermore, featMAP embeds the data points by anisotropic projection to preserve the local similarity and original density. We apply featMAP to interpreting digit classification, object detection and MNIST adversarial examples. FeatMAP uses source features to explicitly distinguish the digits and objects and to explain the misclassification of adversarial examples. We also compare featMAP with other state-of-the-art methods on local and global metrics.
Read more4/3/2024