Gradient descent provably escapes saddle points in the training of shallow ReLU networks

0
🏋️
Sign in to get full access
Overview
- Dynamical systems theory has been applied to show that gradient descent algorithms can avoid strict saddle points in optimization problems.
- However, in many modern machine learning applications, the required conditions for this result are not satisfied.
- This paper presents a variant of the relevant dynamical systems result, a center-stable manifold theorem, that relaxes some of the regularity requirements.
- The paper explores the relevance of this theorem for various machine learning tasks, with a particular focus on shallow rectified linear unit (ReLU) and leaky ReLU networks with scalar input.
Plain English Explanation
In machine learning, researchers often use an optimization technique called gradient descent to train their models. Gradient descent algorithms can sometimes get stuck in what are called "saddle points" of the model's loss function, which are points where the function has a local minimum in some directions and a local maximum in others.
However, recent work has shown that gradient descent can often avoid these saddle points, thanks to a mathematical concept called "dynamical systems theory." But this previous work had some strict requirements that aren't always met in real-world machine learning problems.
In this paper, the researchers relaxed some of those requirements and proved a new version of the relevant dynamical systems result. They then explored how this new theorem applies to different types of neural networks, particularly simple ones with ReLU activations.
The key finding is that gradient descent can indeed bypass most saddle points in these neural network models, and under certain conditions, it can even converge to the global minimum of the loss function.
Technical Explanation
The paper presents a variant of the center-stable manifold theorem, a key result from dynamical systems theory, that relaxes some of the regularity conditions required in previous work. This allows the authors to apply it to a broader range of machine learning problems.
Specifically, the paper focuses on shallow rectified linear unit (ReLU) and leaky ReLU neural networks with scalar input. The researchers provide a detailed examination of the critical points (including saddle points) of the square integral loss function for these network architectures relative to an affine target function.
Building on this analysis, the paper shows that gradient descent can circumvent most saddle points in these models. Furthermore, the authors prove convergence to global minima under favorable initialization conditions, quantified by an explicit threshold on the limiting loss.
Critical Analysis
The paper makes an important theoretical contribution by relaxing the regularity conditions required in previous work on gradient descent and saddle points. This allows the authors to apply the relevant dynamical systems results to a broader range of machine learning problems, particularly those involving simple neural network architectures.
However, the paper focuses primarily on shallow ReLU and leaky ReLU networks with scalar input, which may not be representative of the more complex models used in many real-world applications. Additional research would be needed to understand how well the findings generalize to deeper networks, multi-dimensional inputs, and other activation functions.
Furthermore, the paper does not address potential issues that could arise in the presence of unbounded gradients or the challenges of optimizing nonconvex loss functions in high-dimensional spaces. These are important practical concerns that the research community continues to grapple with.
Conclusion
This paper presents a significant theoretical advance in our understanding of how gradient descent can bypass saddle points in the optimization of machine learning models. By relaxing some of the regularity conditions required in previous work, the authors have shown that their center-stable manifold theorem can be applied to a broader range of neural network architectures.
The key finding - that gradient descent can circumvent most saddle points and converge to global minima under favorable conditions - has important implications for the training and deployment of shallow ReLU and leaky ReLU networks. While further research is needed to understand the generalizability of these results, this paper represents a meaningful step forward in the ongoing effort to build a more robust and comprehensive theory of optimization in machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
Gradient descent provably escapes saddle points in the training of shallow ReLU networks
Patrick Cheridito, Arnulf Jentzen, Florian Rossmannek
Dynamical systems theory has recently been applied in optimization to prove that gradient descent algorithms bypass so-called strict saddle points of the loss function. However, in many modern machine learning applications, the required regularity conditions are not satisfied. In this paper, we prove a variant of the relevant dynamical systems result, a center-stable manifold theorem, in which we relax some of the regularity requirements. We explore its relevance for various machine learning tasks, with a particular focus on shallow rectified linear unit (ReLU) and leaky ReLU networks with scalar input. Building on a detailed examination of critical points of the square integral loss function for shallow ReLU and leaky ReLU networks relative to an affine target function, we show that gradient descent circumvents most saddle points. Furthermore, we prove convergence to global minima under favourable initialization conditions, quantified by an explicit threshold on the limiting loss.
Read more9/12/2024
🧠
0
Loss Landscape of Shallow ReLU-like Neural Networks: Stationary Points, Saddle Escaping, and Network Embedding
Zhengqing Wu, Berfin Simsek, Francois Ged
In this paper, we investigate the loss landscape of one-hidden-layer neural networks with ReLU-like activation functions trained with the empirical squared loss. As the activation function is non-differentiable, it is so far unclear how to completely characterize the stationary points. We propose the conditions for stationarity that apply to both non-differentiable and differentiable cases. Additionally, we show that, if a stationary point does not contain escape neurons, which are defined with first-order conditions, then it must be a local minimum. Moreover, for the scalar-output case, the presence of an escape neuron guarantees that the stationary point is not a local minimum. Our results refine the description of the saddle-to-saddle training process starting from infinitesimally small (vanishing) initialization for shallow ReLU-like networks, linking saddle escaping directly with the parameter changes of escape neurons. Moreover, we are also able to fully discuss how network embedding, which is to instantiate a narrower network within a wider network, reshapes the stationary points.
Read more6/13/2024
🤿
0
The loss landscape of deep linear neural networks: a second-order analysis
El Mehdi Achour (IMT), Franc{c}ois Malgouyres (IMT), S'ebastien Gerchinovitz (IMT)
We study the optimization landscape of deep linear neural networks with the square loss. It is known that, under weak assumptions, there are no spurious local minima and no local maxima. However, the existence and diversity of non-strict saddle points, which can play a role in first-order algorithms' dynamics, have only been lightly studied. We go a step further with a full analysis of the optimization landscape at order 2. We characterize, among all critical points, which are global minimizers, strict saddle points, and non-strict saddle points. We enumerate all the associated critical values. The characterization is simple, involves conditions on the ranks of partial matrix products, and sheds some light on global convergence or implicit regularization that have been proved or observed when optimizing linear neural networks. In passing, we provide an explicit parameterization of the set of all global minimizers and exhibit large sets of strict and non-strict saddle points.
Read more9/26/2024
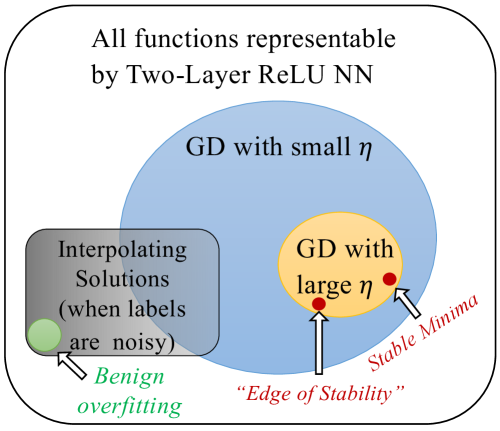
0
Stable Minima Cannot Overfit in Univariate ReLU Networks: Generalization by Large Step Sizes
Dan Qiao, Kaiqi Zhang, Esha Singh, Daniel Soudry, Yu-Xiang Wang
We study the generalization of two-layer ReLU neural networks in a univariate nonparametric regression problem with noisy labels. This is a problem where kernels (emph{e.g.} NTK) are provably sub-optimal and benign overfitting does not happen, thus disqualifying existing theory for interpolating (0-loss, global optimal) solutions. We present a new theory of generalization for local minima that gradient descent with a constant learning rate can emph{stably} converge to. We show that gradient descent with a fixed learning rate $eta$ can only find local minima that represent smooth functions with a certain weighted emph{first order total variation} bounded by $1/eta - 1/2 + widetilde{O}(sigma + sqrt{mathrm{MSE}})$ where $sigma$ is the label noise level, $mathrm{MSE}$ is short for mean squared error against the ground truth, and $widetilde{O}(cdot)$ hides a logarithmic factor. Under mild assumptions, we also prove a nearly-optimal MSE bound of $widetilde{O}(n^{-4/5})$ within the strict interior of the support of the $n$ data points. Our theoretical results are validated by extensive simulation that demonstrates large learning rate training induces sparse linear spline fits. To the best of our knowledge, we are the first to obtain generalization bound via minima stability in the non-interpolation case and the first to show ReLU NNs without regularization can achieve near-optimal rates in nonparametric regression.
Read more6/12/2024