How Graph Neural Networks Learn: Lessons from Training Dynamics
2310.05105
0
0
🧠
Abstract
A long-standing goal in deep learning has been to characterize the learning behavior of black-box models in a more interpretable manner. For graph neural networks (GNNs), considerable advances have been made in formalizing what functions they can represent, but whether GNNs will learn desired functions during the optimization process remains less clear. To fill this gap, we study their training dynamics in function space. In particular, we find that the gradient descent optimization of GNNs implicitly leverages the graph structure to update the learned function, as can be quantified by a phenomenon which we call emph{kernel-graph alignment}. We provide theoretical explanations for the emergence of this phenomenon in the overparameterized regime and empirically validate it on real-world GNNs. This finding offers new interpretable insights into when and why the learned GNN functions generalize, highlighting their limitations in heterophilic graphs. Practically, we propose a parameter-free algorithm that directly uses a sparse matrix (i.e. graph adjacency) to update the learned function. We demonstrate that this embarrassingly simple approach can be as effective as GNNs while being orders-of-magnitude faster.
Create account to get full access
Overview
- Researchers aim to better understand how graph neural networks (GNNs) learn and represent functions during training
- They find that GNNs implicitly leverage the structure of the input graph to update the learned function, a phenomenon called "kernel-graph alignment"
- This provides new insights into when and why GNNs generalize well, especially on heterophilic graphs
- The researchers propose a simple, parameter-free algorithm that directly uses the graph structure to update the function, matching the performance of GNNs while being much faster
Plain English Explanation
Graph neural networks (GNNs) are a powerful type of deep learning model that can process and learn from graph-structured data. [A graph is a mathematical representation of a set of objects (nodes) and the connections (edges) between them.] One of the key goals in deep learning has been to better understand how these "black-box" models like GNNs actually learn and represent the functions they are trying to learn.
The researchers in this paper have made an interesting discovery about how GNNs learn. They found that during the training process, GNNs implicitly use the structure of the input graph to update the function they are learning. This phenomenon, which they call "kernel-graph alignment," helps explain when and why GNNs are able to generalize well to new data, especially on graphs where the connections between different types of nodes (heterophilic graphs) are important.
The researchers were able to provide theoretical explanations for why this kernel-graph alignment happens, and they validated their findings on real-world GNN models. This gives us a more interpretable view into how these powerful models work under the hood.
Importantly, the researchers also propose a very simple, parameter-free algorithm that directly uses the graph structure to update the learned function. Remarkably, this embarrassingly simple approach can match the performance of full-fledged GNNs, while being orders of magnitude faster. This could lead to much more efficient and practical use of graph-based deep learning models.
Technical Explanation
The researchers start by noting that while there has been significant progress in understanding the representative power of GNNs - i.e. what functions they can theoretically learn - it remains less clear how they will actually learn these desired functions during the optimization process.
To shed light on this, the researchers study the training dynamics of GNNs in function space. They find that the gradient descent optimization of GNNs implicitly leverages the structure of the input graph to update the learned function. This phenomenon, which they call "kernel-graph alignment," can be quantified and theoretically explained, especially in the overparameterized regime where GNNs often excel.
Empirically, the researchers validate this kernel-graph alignment on real-world GNN models, showing that it helps explain when and why the learned GNN functions generalize well, particularly on heterophilic graphs where the connections between different types of nodes are important.
Building on these insights, the researchers propose a parameter-free algorithm that directly uses the sparse graph adjacency matrix to update the learned function. They demonstrate that this embarrassingly simple approach can match the performance of full-fledged GNNs, while being orders-of-magnitude faster. This highlights the potential for more efficient and practical use of graph neural networks by better leveraging the underlying graph structure.
Critical Analysis
The researchers provide a thoughtful and rigorous analysis of GNN training dynamics, uncovering an important phenomenon that offers new interpretable insights into the successes and limitations of these models. The theoretical explanations for kernel-graph alignment, backed by empirical validation, are compelling and contribute to our fundamental understanding of how GNNs work.
That said, the paper does acknowledge some caveats and limitations. The theoretical analysis is focused on the overparameterized regime, and it remains to be seen if the insights extend to more practical, resource-constrained settings. Additionally, the proposed parameter-free algorithm, while impressive in its simplicity and efficiency, may not capture the full expressive power of learnable GNN architectures.
Further research could explore the interplay between kernel-graph alignment, model capacity, and generalization on a broader range of graph tasks and datasets, including those with more complex, heterogeneous structures. Investigating how these insights might inform the design of more interpretable and efficient GNN architectures would also be a valuable direction.
Overall, this work represents an important step forward in the quest to demystify the inner workings of powerful graph neural network models. By shedding light on their training dynamics, the researchers have opened up new avenues for improving the transparency, efficiency, and real-world applicability of these increasingly influential tools.
Conclusion
This paper offers a fascinating look under the hood of graph neural networks, uncovering a key mechanism by which they leverage the input graph structure to learn effective functions. The discovery of "kernel-graph alignment" provides interpretable insights into the strengths and limitations of GNNs, especially when it comes to modeling heterophilic relationships.
Importantly, the researchers have also demonstrated a simple, parameter-free algorithm that directly utilizes the graph structure to update the learned function. This approach can match the performance of full-fledged GNNs while being orders of magnitude faster, suggesting promising paths toward more efficient and practical graph-based deep learning.
As the field of graph machine learning continues to advance, works like this that deepen our understanding of how these models work under the hood will be crucial. By shedding light on the training dynamics and inductive biases of GNNs, this research opens up new directions for designing more transparent, generalizable, and computationally efficient graph neural network architectures that can be robustly deployed in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
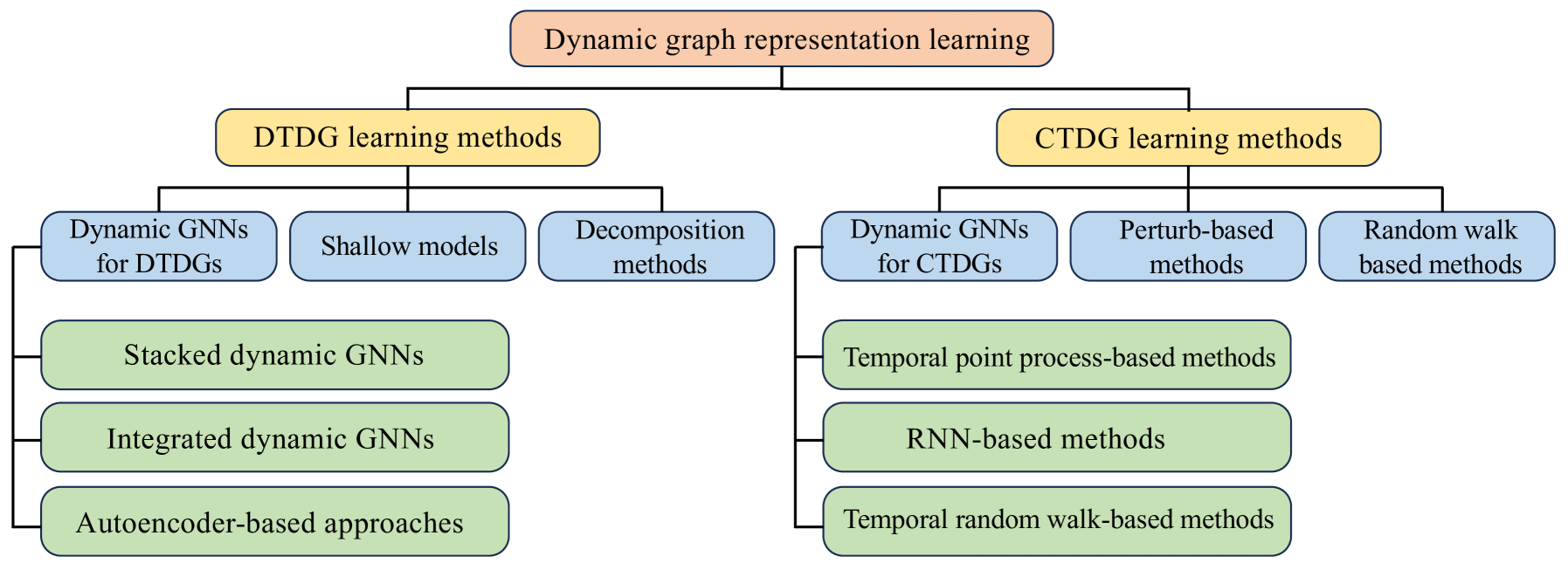
A survey of dynamic graph neural networks
Yanping Zheng, Lu Yi, Zhewei Wei
0
0
Graph neural networks (GNNs) have emerged as a powerful tool for effectively mining and learning from graph-structured data, with applications spanning numerous domains. However, most research focuses on static graphs, neglecting the dynamic nature of real-world networks where topologies and attributes evolve over time. By integrating sequence modeling modules into traditional GNN architectures, dynamic GNNs aim to bridge this gap, capturing the inherent temporal dependencies of dynamic graphs for a more authentic depiction of complex networks. This paper provides a comprehensive review of the fundamental concepts, key techniques, and state-of-the-art dynamic GNN models. We present the mainstream dynamic GNN models in detail and categorize models based on how temporal information is incorporated. We also discuss large-scale dynamic GNNs and pre-training techniques. Although dynamic GNNs have shown superior performance, challenges remain in scalability, handling heterogeneous information, and lack of diverse graph datasets. The paper also discusses possible future directions, such as adaptive and memory-enhanced models, inductive learning, and theoretical analysis.
4/30/2024
🔄
Future Directions in the Theory of Graph Machine Learning
Christopher Morris, Fabrizio Frasca, Nadav Dym, Haggai Maron, .Ismail .Ilkan Ceylan, Ron Levie, Derek Lim, Michael Bronstein, Martin Grohe, Stefanie Jegelka
0
0
Machine learning on graphs, especially using graph neural networks (GNNs), has seen a surge in interest due to the wide availability of graph data across a broad spectrum of disciplines, from life to social and engineering sciences. Despite their practical success, our theoretical understanding of the properties of GNNs remains highly incomplete. Recent theoretical advancements primarily focus on elucidating the coarse-grained expressive power of GNNs, predominantly employing combinatorial techniques. However, these studies do not perfectly align with practice, particularly in understanding the generalization behavior of GNNs when trained with stochastic first-order optimization techniques. In this position paper, we argue that the graph machine learning community needs to shift its attention to developing a balanced theory of graph machine learning, focusing on a more thorough understanding of the interplay of expressive power, generalization, and optimization.
6/17/2024
Deep learning for dynamic graphs: models and benchmarks
Alessio Gravina, Davide Bacciu
0
0
Recent progress in research on Deep Graph Networks (DGNs) has led to a maturation of the domain of learning on graphs. Despite the growth of this research field, there are still important challenges that are yet unsolved. Specifically, there is an urge of making DGNs suitable for predictive tasks on realworld systems of interconnected entities, which evolve over time. With the aim of fostering research in the domain of dynamic graphs, at first, we survey recent advantages in learning both temporal and spatial information, providing a comprehensive overview of the current state-of-the-art in the domain of representation learning for dynamic graphs. Secondly, we conduct a fair performance comparison among the most popular proposed approaches on node and edge-level tasks, leveraging rigorous model selection and assessment for all the methods, thus establishing a sound baseline for evaluating new architectures and approaches
4/10/2024
🧠
Gradient Transformation: Towards Efficient and Model-Agnostic Unlearning for Dynamic Graph Neural Networks
He Zhang, Bang Wu, Xiangwen Yang, Xingliang Yuan, Chengqi Zhang, Shirui Pan
0
0
Graph unlearning has emerged as an essential tool for safeguarding user privacy and mitigating the negative impacts of undesirable data. Meanwhile, the advent of dynamic graph neural networks (DGNNs) marks a significant advancement due to their superior capability in learning from dynamic graphs, which encapsulate spatial-temporal variations in diverse real-world applications (e.g., traffic forecasting). With the increasing prevalence of DGNNs, it becomes imperative to investigate the implementation of dynamic graph unlearning. However, current graph unlearning methodologies are designed for GNNs operating on static graphs and exhibit limitations including their serving in a pre-processing manner and impractical resource demands. Furthermore, the adaptation of these methods to DGNNs presents non-trivial challenges, owing to the distinctive nature of dynamic graphs. To this end, we propose an effective, efficient, model-agnostic, and post-processing method to implement DGNN unlearning. Specifically, we first define the unlearning requests and formulate dynamic graph unlearning in the context of continuous-time dynamic graphs. After conducting a role analysis on the unlearning data, the remaining data, and the target DGNN model, we propose a method called Gradient Transformation and a loss function to map the unlearning request to the desired parameter update. Evaluations on six real-world datasets and state-of-the-art DGNN backbones demonstrate its effectiveness (e.g., limited performance drop even obvious improvement) and efficiency (e.g., at most 7.23$times$ speed-up) outperformance, and potential advantages in handling future unlearning requests (e.g., at most 32.59$times$ speed-up).
5/24/2024