Graph Convolutions Enrich the Self-Attention in Transformers!
2312.04234
0
0
Abstract
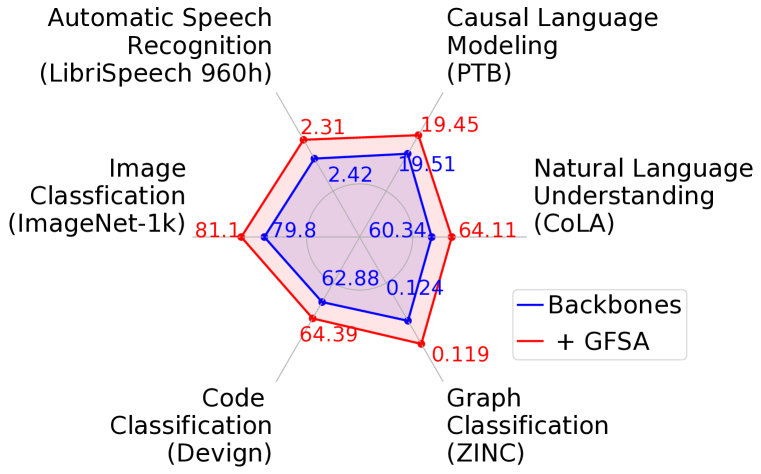
Transformers, renowned for their self-attention mechanism, have achieved state-of-the-art performance across various tasks in natural language processing, computer vision, time-series modeling, etc. However, one of the challenges with deep Transformer models is the oversmoothing problem, where representations across layers converge to indistinguishable values, leading to significant performance degradation. We interpret the original self-attention as a simple graph filter and redesign it from a graph signal processing (GSP) perspective. We propose a graph-filter-based self-attention (GFSA) to learn a general yet effective one, whose complexity, however, is slightly larger than that of the original self-attention mechanism. We demonstrate that GFSA improves the performance of Transformers in various fields, including computer vision, natural language processing, graph regression, speech recognition, and code classification.
Create account to get full access
Overview
- The paper explores incorporating graph convolutions into the self-attention mechanism of Transformers to enrich the model's understanding of input data.
- The proposed approach, called Graph-enriched Transformers (GET), leverages graph convolutional networks to capture structural information and enhance the self-attention process.
- Experiments on various tasks, including language modeling, machine translation, and visual recognition, demonstrate the effectiveness of the GET model in improving performance compared to standard Transformer architectures.
Plain English Explanation
The paper introduces a new way to make Transformer models, which are a type of machine learning model, smarter. Transformers are good at understanding things like text and images, but they can struggle to capture the underlying structure or relationships in the data.
The researchers propose adding "graph convolutions" to the self-attention mechanism in Transformers. Self-attention is a key part of Transformers that helps the model understand how different parts of the input are related. By incorporating graph convolutions, the model can better learn the connections and structure within the data, which can lead to improved performance on various tasks.
The graph convolutions essentially allow the Transformer to "see" the relationships between different elements in the input, similar to how a social network graph can show how people are connected. This extra information helps the model make more informed decisions when processing the data.
The researchers test their Graph-enriched Transformer (GET) model on language modeling, machine translation, and visual recognition tasks. They find that the GET model outperforms standard Transformer architectures, demonstrating the benefits of incorporating graph-based information into the self-attention mechanism.
Technical Explanation
The paper presents the Graph-enriched Transformer (GET) model, which integrates graph convolutional networks (GCNs) into the self-attention mechanism of Transformer models. The key idea is to leverage the structural information captured by GCNs to enrich the self-attention process, allowing the model to better understand the underlying relationships in the input data.
The self-attention mechanism in Transformers [<a href="https://aimodels.fyi/papers/arxiv/mansformer-efficient-transformer-mixed-attention-image-deblurring">1</a>, <a href="https://aimodels.fyi/papers/arxiv/conv-basis-new-paradigm-efficient-attention-inference">2</a>] computes attention weights based on the similarity between the query and key vectors. The GET model extends this by introducing a graph convolution module that operates on the input features and the attention weights. This allows the model to incorporate graph-based information into the self-attention process, capturing structural relationships that can be beneficial for various tasks.
The researchers evaluate the GET model on language modeling, machine translation, and visual recognition tasks, and demonstrate its superior performance compared to standard Transformer architectures. The improvements are particularly notable in tasks where the underlying structure of the input data plays a crucial role, such as in graph-structured data or images with strong spatial relationships.
Critical Analysis
The paper provides a compelling approach to enhance Transformer models by incorporating graph-based information through the use of graph convolutions. The key strengths of the proposed GET model are its ability to capture structural relationships and its versatility in improving performance across different application domains.
One potential limitation of the study is the reliance on pre-defined graph structures for the graph convolution module. In some cases, the graph structure may not be readily available or may need to be inferred from the input data. Further research could explore methods to automatically construct the graph structure or learn it as part of the model training process.
Additionally, the paper does not provide a comprehensive analysis of the computational overhead and inference latency of the GET model compared to standard Transformers. As model efficiency is a critical consideration for real-world applications, it would be valuable to evaluate the trade-offs between the performance gains and the computational requirements of the proposed approach.
Despite these minor caveats, the paper presents a promising direction for improving Transformer models by leveraging graph-based information. The successful integration of graph convolutions into the self-attention mechanism opens up new avenues for further research and development in this area. Readers are encouraged to critically examine the findings and consider how the GET model could be adapted or extended to address their specific needs or challenges.
Conclusion
The paper introduces the Graph-enriched Transformer (GET) model, which incorporates graph convolutions into the self-attention mechanism of Transformer architectures. By leveraging structural information captured by graph convolutional networks, the GET model can better understand the underlying relationships in the input data, leading to improved performance on a variety of tasks, including language modeling, machine translation, and visual recognition.
The key contribution of this work is the effective integration of graph-based information into the self-attention process, allowing Transformers to go beyond capturing only local dependencies and instead learn from the broader structural context. This approach demonstrates the potential for enhancing the capabilities of Transformer models, particularly in domains where the input data exhibits strong relational or spatial structure.
As the field of machine learning continues to evolve, the insights and techniques presented in this paper can serve as a valuable reference for researchers and practitioners seeking to develop more powerful and adaptable Transformer-based models. By blending the strengths of self-attention and graph-based reasoning, the GET model represents a promising step towards building more versatile and effective artificial intelligence systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

What Improves the Generalization of Graph Transformers? A Theoretical Dive into the Self-attention and Positional Encoding
Hongkang Li, Meng Wang, Tengfei Ma, Sijia Liu, Zaixi Zhang, Pin-Yu Chen
0
0
Graph Transformers, which incorporate self-attention and positional encoding, have recently emerged as a powerful architecture for various graph learning tasks. Despite their impressive performance, the complex non-convex interactions across layers and the recursive graph structure have made it challenging to establish a theoretical foundation for learning and generalization. This study introduces the first theoretical investigation of a shallow Graph Transformer for semi-supervised node classification, comprising a self-attention layer with relative positional encoding and a two-layer perceptron. Focusing on a graph data model with discriminative nodes that determine node labels and non-discriminative nodes that are class-irrelevant, we characterize the sample complexity required to achieve a desirable generalization error by training with stochastic gradient descent (SGD). This paper provides the quantitative characterization of the sample complexity and number of iterations for convergence dependent on the fraction of discriminative nodes, the dominant patterns, and the initial model errors. Furthermore, we demonstrate that self-attention and positional encoding enhance generalization by making the attention map sparse and promoting the core neighborhood during training, which explains the superior feature representation of Graph Transformers. Our theoretical results are supported by empirical experiments on synthetic and real-world benchmarks.
6/5/2024
🧠
Demystifying Oversmoothing in Attention-Based Graph Neural Networks
Xinyi Wu, Amir Ajorlou, Zihui Wu, Ali Jadbabaie
0
0
Oversmoothing in Graph Neural Networks (GNNs) refers to the phenomenon where increasing network depth leads to homogeneous node representations. While previous work has established that Graph Convolutional Networks (GCNs) exponentially lose expressive power, it remains controversial whether the graph attention mechanism can mitigate oversmoothing. In this work, we provide a definitive answer to this question through a rigorous mathematical analysis, by viewing attention-based GNNs as nonlinear time-varying dynamical systems and incorporating tools and techniques from the theory of products of inhomogeneous matrices and the joint spectral radius. We establish that, contrary to popular belief, the graph attention mechanism cannot prevent oversmoothing and loses expressive power exponentially. The proposed framework extends the existing results on oversmoothing for symmetric GCNs to a significantly broader class of GNN models, including random walk GCNs, Graph Attention Networks (GATs) and (graph) transformers. In particular, our analysis accounts for asymmetric, state-dependent and time-varying aggregation operators and a wide range of common nonlinear activation functions, such as ReLU, LeakyReLU, GELU and SiLU.
6/5/2024
🛸
Gransformer: Transformer-based Graph Generation
Ahmad Khajenezhad, Seyed Ali Osia, Mahmood Karimian, Hamid Beigy
0
0
Transformers have become widely used in various tasks, such as natural language processing and machine vision. This paper proposes Gransformer, an algorithm based on Transformer for generating graphs. We modify the Transformer encoder to exploit the structural information of the given graph. The attention mechanism is adapted to consider the presence or absence of edges between each pair of nodes. We also introduce a graph-based familiarity measure between node pairs that applies to both the attention and the positional encoding. This measure of familiarity is based on message-passing algorithms and contains structural information about the graph. Also, this measure is autoregressive, which allows our model to acquire the necessary conditional probabilities in a single forward pass. In the output layer, we also use a masked autoencoder for density estimation to efficiently model the sequential generation of dependent edges connected to each node. In addition, we propose a technique to prevent the model from generating isolated nodes without connection to preceding nodes by using BFS node orderings. We evaluate this method using synthetic and real-world datasets and compare it with related ones, including recurrent models and graph convolutional networks. Experimental results show that the proposed method performs comparatively to these methods.
6/3/2024

A Primal-Dual Framework for Transformers and Neural Networks
Tan M. Nguyen, Tam Nguyen, Nhat Ho, Andrea L. Bertozzi, Richard G. Baraniuk, Stanley J. Osher
0
0
Self-attention is key to the remarkable success of transformers in sequence modeling tasks including many applications in natural language processing and computer vision. Like neural network layers, these attention mechanisms are often developed by heuristics and experience. To provide a principled framework for constructing attention layers in transformers, we show that the self-attention corresponds to the support vector expansion derived from a support vector regression problem, whose primal formulation has the form of a neural network layer. Using our framework, we derive popular attention layers used in practice and propose two new attentions: 1) the Batch Normalized Attention (Attention-BN) derived from the batch normalization layer and 2) the Attention with Scaled Head (Attention-SH) derived from using less training data to fit the SVR model. We empirically demonstrate the advantages of the Attention-BN and Attention-SH in reducing head redundancy, increasing the model's accuracy, and improving the model's efficiency in a variety of practical applications including image and time-series classification.
6/21/2024