A Primal-Dual Framework for Transformers and Neural Networks
2406.13781
0
0

Abstract
Self-attention is key to the remarkable success of transformers in sequence modeling tasks including many applications in natural language processing and computer vision. Like neural network layers, these attention mechanisms are often developed by heuristics and experience. To provide a principled framework for constructing attention layers in transformers, we show that the self-attention corresponds to the support vector expansion derived from a support vector regression problem, whose primal formulation has the form of a neural network layer. Using our framework, we derive popular attention layers used in practice and propose two new attentions: 1) the Batch Normalized Attention (Attention-BN) derived from the batch normalization layer and 2) the Attention with Scaled Head (Attention-SH) derived from using less training data to fit the SVR model. We empirically demonstrate the advantages of the Attention-BN and Attention-SH in reducing head redundancy, increasing the model's accuracy, and improving the model's efficiency in a variety of practical applications including image and time-series classification.
Create account to get full access
Overview
- Introduces a new "primal-dual" framework for understanding transformers and neural networks
- Provides a theoretical analysis of self-attention mechanisms in transformers
- Connects transformers to classical optimization and game theory concepts
Plain English Explanation
This paper presents a new way of thinking about transformers, a type of neural network that has been very successful in tasks like language modeling and machine translation. The key idea is to view transformers through the lens of "primal-dual" optimization, a concept from classical optimization theory.
The researchers show that the self-attention mechanism at the heart of transformers can be reinterpreted as a way of solving an optimization problem with two sides - a "primal" problem and a "dual" problem. This allows them to draw connections between transformers and classical ideas from game theory and optimization. <a href="https://aimodels.fyi/papers/arxiv/role-attention-masks-layernorm-transformers">For example, they show that the attention weights in a transformer can be seen as the solution to a game between different parts of the network.</a>
By casting transformers in this new light, the paper offers insights into how these powerful models work under the hood. This could lead to new ways of designing and analyzing neural network architectures, beyond just transformers. The links to optimization and game theory also suggest potential applications in areas like reinforcement learning and multi-agent systems.
Technical Explanation
The core of the paper is a new "primal-dual" framework for understanding transformers and other neural networks. The key idea is to reinterpret the self-attention mechanism in transformers as a way of solving a constrained optimization problem.
Specifically, the authors show that the attention weights in a transformer can be seen as the solution to a "primal" optimization problem, where the goal is to maximize the similarity between each input and its corresponding output. This primal problem is constrained by a "dual" problem, which aims to ensure that the attention weights satisfy certain desirable properties, like being non-negative and summing to 1.
<a href="https://aimodels.fyi/papers/arxiv/unveiling-hidden-structure-self-attention-via-kernel">By casting self-attention in this primal-dual framework, the authors are able to uncover new insights about its structure and behavior.</a> For example, they show that the attention weights can be interpreted as the solution to a game between different parts of the network, with each part trying to maximize its own similarity measure.
The authors also draw connections between their primal-dual framework and classical ideas from optimization theory and game theory. <a href="https://aimodels.fyi/papers/arxiv/attention-as-hypernetwork">For instance, they show that the attention weights can be seen as the solution to a "generalized linear complementarity problem," which is a well-studied concept in optimization.</a>
<a href="https://aimodels.fyi/papers/arxiv/dissecting-interplay-attention-paths-statistical-mechanics-theory">Furthermore, the authors provide a detailed statistical mechanics analysis of the attention mechanism, shedding light on the complex interplay between different attention paths within the network.</a>
Critical Analysis
The primal-dual framework introduced in this paper provides a novel and insightful way of thinking about transformers and other neural networks. By connecting these models to classical optimization and game theory concepts, the authors open up new avenues for theoretical analysis and potential architectural innovations.
One limitation of the current work is that the analysis is primarily theoretical, with limited experimental validation. While the authors demonstrate the mathematical soundness of their framework, it would be valuable to see how it performs in practical applications and whether it can lead to tangible improvements in model design or training.
Additionally, the paper focuses mainly on the self-attention mechanism, and it's not entirely clear how the primal-dual perspective might extend to other components of transformers or other neural network architectures. Exploring the generalizability of this framework to a wider range of models could be an exciting direction for future research.
Another potential area for further exploration is the connection between the primal-dual framework and other recent advancements in neural network theory, such as <a href="https://aimodels.fyi/papers/arxiv/mansformer-efficient-transformer-mixed-attention-image-deblurring">the use of mixed attention mechanisms</a> or the analysis of attention from a statistical mechanics perspective.
Overall, this paper represents a significant contribution to the theoretical understanding of transformers and neural networks more broadly. The primal-dual framework offers a fresh perspective that could inspire new breakthroughs in model design and analysis.
Conclusion
The paper introduces a novel "primal-dual" framework for understanding transformers and other neural networks, with a particular focus on the self-attention mechanism. By reinterpreting attention as the solution to a constrained optimization problem, the authors uncover new insights about the structure and behavior of these powerful models.
The connections drawn between transformers and classical optimization and game theory concepts open up exciting possibilities for further theoretical and practical advancements. While the current work is primarily theoretical, it lays the groundwork for potential improvements in neural network architecture and training, as well as applications in related fields like reinforcement learning and multi-agent systems.
Overall, this paper represents an important contribution to the ongoing efforts to better understand the inner workings of neural networks and unlock their full potential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

On the Role of Attention Masks and LayerNorm in Transformers
Xinyi Wu, Amir Ajorlou, Yifei Wang, Stefanie Jegelka, Ali Jadbabaie
0
0
Self-attention is the key mechanism of transformers, which are the essential building blocks of modern foundation models. Recent studies have shown that pure self-attention suffers from an increasing degree of rank collapse as depth increases, limiting model expressivity and further utilization of model depth. The existing literature on rank collapse, however, has mostly overlooked other critical components in transformers that may alleviate the rank collapse issue. In this paper, we provide a general analysis of rank collapse under self-attention, taking into account the effects of attention masks and layer normalization (LayerNorm). In particular, we find that although pure masked attention still suffers from exponential collapse to a rank one subspace, local masked attention can provably slow down the collapse rate. In the case of self-attention with LayerNorm, we first show that for certain classes of value matrices, collapse to a rank one subspace still happens exponentially. However, through construction of nontrivial counterexamples, we then establish that with proper choice of value matrices, a general class of sequences may not converge to a rank one subspace, and the self-attention dynamics with LayerNorm can simultaneously possess a rich set of equilibria with any possible rank between one and full. Our result refutes the previous hypothesis that LayerNorm plays no role in the rank collapse of self-attention and suggests that self-attention with LayerNorm constitutes a much more expressive, versatile nonlinear dynamical system than what was originally thought.
5/30/2024

Unveiling the Hidden Structure of Self-Attention via Kernel Principal Component Analysis
Rachel S. Y. Teo, Tan M. Nguyen
0
0
The remarkable success of transformers in sequence modeling tasks, spanning various applications in natural language processing and computer vision, is attributed to the critical role of self-attention. Similar to the development of most deep learning models, the construction of these attention mechanisms rely on heuristics and experience. In our work, we derive self-attention from kernel principal component analysis (kernel PCA) and show that self-attention projects its query vectors onto the principal component axes of its key matrix in a feature space. We then formulate the exact formula for the value matrix in self-attention, theoretically and empirically demonstrating that this value matrix captures the eigenvectors of the Gram matrix of the key vectors in self-attention. Leveraging our kernel PCA framework, we propose Attention with Robust Principal Components (RPC-Attention), a novel class of robust attention that is resilient to data contamination. We empirically demonstrate the advantages of RPC-Attention over softmax attention on the ImageNet-1K object classification, WikiText-103 language modeling, and ADE20K image segmentation task.
6/21/2024
🖼️
Attention as a Hypernetwork
Simon Schug, Seijin Kobayashi, Yassir Akram, Jo~ao Sacramento, Razvan Pascanu
0
0
Transformers can under some circumstances generalize to novel problem instances whose constituent parts might have been encountered during training but whose compositions have not. What mechanisms underlie this ability for compositional generalization? By reformulating multi-head attention as a hypernetwork, we reveal that a low-dimensional latent code specifies key-query specific operations. We find empirically that this latent code is highly structured, capturing information about the subtasks performed by the network. Using the framework of attention as a hypernetwork we further propose a simple modification of multi-head linear attention that strengthens the ability for compositional generalization on a range of abstract reasoning tasks. In particular, we introduce a symbolic version of the Raven Progressive Matrices human intelligence test on which we demonstrate how scaling model size and data enables compositional generalization and gives rise to a functionally structured latent code in the transformer.
6/24/2024
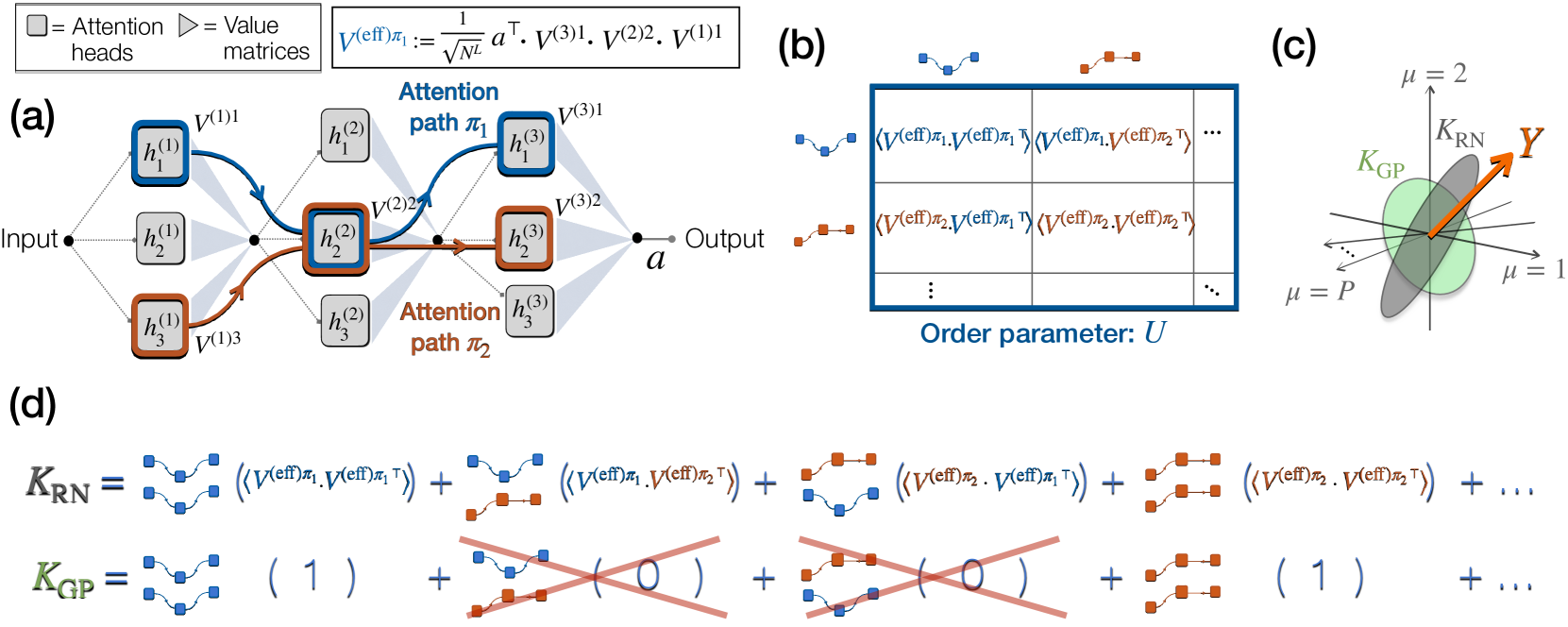
Dissecting the Interplay of Attention Paths in a Statistical Mechanics Theory of Transformers
Lorenzo Tiberi, Francesca Mignacco, Kazuki Irie, Haim Sompolinsky
0
0
Despite the remarkable empirical performance of Transformers, their theoretical understanding remains elusive. Here, we consider a deep multi-head self-attention network, that is closely related to Transformers yet analytically tractable. We develop a statistical mechanics theory of Bayesian learning in this model, deriving exact equations for the network's predictor statistics under the finite-width thermodynamic limit, i.e., $N,Prightarrowinfty$, $P/N=mathcal{O}(1)$, where $N$ is the network width and $P$ is the number of training examples. Our theory shows that the predictor statistics are expressed as a sum of independent kernels, each one pairing different 'attention paths', defined as information pathways through different attention heads across layers. The kernels are weighted according to a 'task-relevant kernel combination' mechanism that aligns the total kernel with the task labels. As a consequence, this interplay between attention paths enhances generalization performance. Experiments confirm our findings on both synthetic and real-world sequence classification tasks. Finally, our theory explicitly relates the kernel combination mechanism to properties of the learned weights, allowing for a qualitative transfer of its insights to models trained via gradient descent. As an illustration, we demonstrate an efficient size reduction of the network, by pruning those attention heads that are deemed less relevant by our theory.
5/28/2024