Demystifying Oversmoothing in Attention-Based Graph Neural Networks
2305.16102
0
0
🧠
Abstract
Oversmoothing in Graph Neural Networks (GNNs) refers to the phenomenon where increasing network depth leads to homogeneous node representations. While previous work has established that Graph Convolutional Networks (GCNs) exponentially lose expressive power, it remains controversial whether the graph attention mechanism can mitigate oversmoothing. In this work, we provide a definitive answer to this question through a rigorous mathematical analysis, by viewing attention-based GNNs as nonlinear time-varying dynamical systems and incorporating tools and techniques from the theory of products of inhomogeneous matrices and the joint spectral radius. We establish that, contrary to popular belief, the graph attention mechanism cannot prevent oversmoothing and loses expressive power exponentially. The proposed framework extends the existing results on oversmoothing for symmetric GCNs to a significantly broader class of GNN models, including random walk GCNs, Graph Attention Networks (GATs) and (graph) transformers. In particular, our analysis accounts for asymmetric, state-dependent and time-varying aggregation operators and a wide range of common nonlinear activation functions, such as ReLU, LeakyReLU, GELU and SiLU.
Create account to get full access
Overview
- The paper investigates the phenomenon of oversmoothing in Graph Neural Networks (GNNs), where increasing network depth leads to homogeneous node representations.
- Previous research has shown that Graph Convolutional Networks (GCNs) exponentially lose expressive power, but it remains controversial whether the graph attention mechanism can mitigate this issue.
- The paper provides a rigorous mathematical analysis to definitively answer this question, viewing attention-based GNNs as nonlinear time-varying dynamical systems and incorporating tools from the theory of products of inhomogeneous matrices and the joint spectral radius.
Plain English Explanation
The paper focuses on a problem called "oversmoothing" that can occur in a type of artificial intelligence model called a Graph Neural Network (GNN). Oversmoothing happens when you make the GNN deeper (by adding more layers), and the representations of the nodes in the graph become more and more similar to each other, losing their unique characteristics.
Previous research had shown that a specific type of GNN called Graph Convolutional Networks (GCNs) exponentially lose their ability to express different features as the network gets deeper. However, it was unclear whether a different type of GNN called Graph Attention Networks (GATs), which use a "graph attention mechanism," could overcome this issue.
The researchers in this paper provide a detailed mathematical analysis to definitively show that, contrary to popular belief, the graph attention mechanism cannot prevent oversmoothing and also loses its expressive power exponentially as the network gets deeper. They do this by viewing the attention-based GNNs as a special type of dynamical system and using advanced mathematical tools to analyze their behavior.
Technical Explanation
The paper establishes that, despite the use of the graph attention mechanism, attention-based GNNs cannot prevent oversmoothing and lose expressive power exponentially. The researchers achieve this by viewing attention-based GNNs as nonlinear time-varying dynamical systems and incorporating tools from the theory of products of inhomogeneous matrices and the joint spectral radius.
This analysis extends the existing results on oversmoothing for symmetric GCNs to a significantly broader class of GNN models, including random walk GCNs, Graph Attention Networks (GATs), and (graph) transformers. Importantly, the proposed framework accounts for asymmetric, state-dependent, and time-varying aggregation operators, as well as a wide range of common nonlinear activation functions, such as ReLU, LeakyReLU, GELU, and SiLU.
The paper's findings contradict the popular belief that the graph attention mechanism can mitigate oversmoothing, and the researchers provide a rigorous mathematical explanation for this phenomenon.
Critical Analysis
The paper provides a comprehensive and rigorous analysis of the oversmoothing problem in attention-based GNNs, addressing a significant gap in the existing research. The authors' use of advanced mathematical tools, such as the theory of products of inhomogeneous matrices and the joint spectral radius, lends credibility to their findings.
One potential limitation of the research is that it focuses primarily on the theoretical analysis and does not include extensive experimental validation. While the mathematical framework is robust, it would be helpful to see how the insights from the analysis translate to real-world GNN performance and practical applications.
Furthermore, the paper does not address potential strategies or architectural modifications that could help mitigate the oversmoothing issue in attention-based GNNs. Future research could explore alternative approaches or novel graph neural network architectures that could overcome the limitations identified in this work.
Overall, the paper makes a significant contribution to the understanding of oversmoothing in GNNs and provides a solid theoretical foundation for future research in this area.
Conclusion
The key takeaway from this paper is that the graph attention mechanism, contrary to popular belief, cannot prevent the oversmoothing problem in Graph Neural Networks. The researchers provide a rigorous mathematical analysis to demonstrate that attention-based GNNs, including various types of models like Graph Attention Networks and graph transformers, exponentially lose their expressive power as the network depth increases.
This finding is significant for the field of graph-based machine learning, as it challenges the widely held assumption that the attention mechanism can solve the oversmoothing issue. The paper's insights could inspire researchers to explore alternative architectural designs or techniques to address this problem and advance the capabilities of Graph Neural Networks in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Graph Neural Networks Do Not Always Oversmooth
Bastian Epping, Alexandre Ren'e, Moritz Helias, Michael T. Schaub
0
0
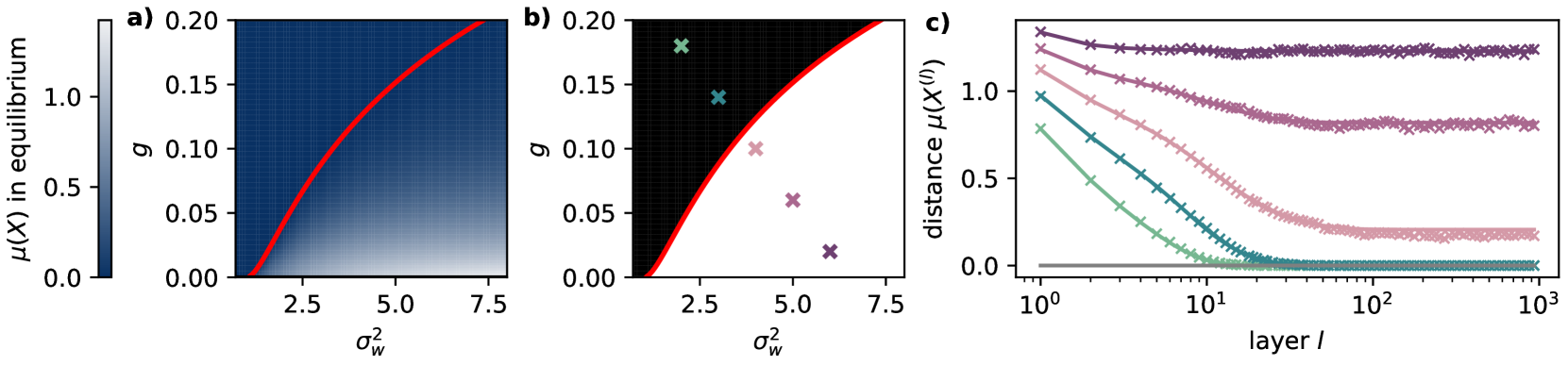
Graph neural networks (GNNs) have emerged as powerful tools for processing relational data in applications. However, GNNs suffer from the problem of oversmoothing, the property that the features of all nodes exponentially converge to the same vector over layers, prohibiting the design of deep GNNs. In this work we study oversmoothing in graph convolutional networks (GCNs) by using their Gaussian process (GP) equivalence in the limit of infinitely many hidden features. By generalizing methods from conventional deep neural networks (DNNs), we can describe the distribution of features at the output layer of deep GCNs in terms of a GP: as expected, we find that typical parameter choices from the literature lead to oversmoothing. The theory, however, allows us to identify a new, nonoversmoothing phase: if the initial weights of the network have sufficiently large variance, GCNs do not oversmooth, and node features remain informative even at large depth. We demonstrate the validity of this prediction in finite-size GCNs by training a linear classifier on their output. Moreover, using the linearization of the GCN GP, we generalize the concept of propagation depth of information from DNNs to GCNs. This propagation depth diverges at the transition between the oversmoothing and non-oversmoothing phase. We test the predictions of our approach and find good agreement with finite-size GCNs. Initializing GCNs near the transition to the non-oversmoothing phase, we obtain networks which are both deep and expressive.
6/5/2024
🧠
ATNPA: A Unified View of Oversmoothing Alleviation in Graph Neural Networks
Yufei Jin, Xingquan Zhu
0
0
Oversmoothing is a commonly observed challenge in graph neural network (GNN) learning, where, as layers increase, embedding features learned from GNNs quickly become similar/indistinguishable, making them incapable of differentiating network proximity. A GNN with shallow layer architectures can only learn short-term relation or localized structure information, limiting its power of learning long-term connection, evidenced by their inferior learning performance on heterophilous graphs. Tackling oversmoothing is crucial to harness deep-layer architectures for GNNs. To date, many methods have been proposed to alleviate oversmoothing. The vast difference behind their design principles, combined with graph complications, make it difficult to understand and even compare their difference in tackling the oversmoothing. In this paper, we propose ATNPA, a unified view with five key steps: Augmentation, Transformation, Normalization, Propagation, and Aggregation, to summarize GNN oversmoothing alleviation approaches. We first outline three themes to tackle oversmoothing, and then separate all methods into six categories, followed by detailed reviews of representative methods, including their relation to the ATNPA, and discussion about their niche, strength, and weakness. The review not only draws in-depth understanding of existing methods in the field, but also shows a clear road map for future study.
5/6/2024

Residual Connections and Normalization Can Provably Prevent Oversmoothing in GNNs
Michael Scholkemper, Xinyi Wu, Ali Jadbabaie, Michael T. Schaub
0
0
Residual connections and normalization layers have become standard design choices for graph neural networks (GNNs), and were proposed as solutions to the mitigate the oversmoothing problem in GNNs. However, how exactly these methods help alleviate the oversmoothing problem from a theoretical perspective is not well understood. In this work, we provide a formal and precise characterization of (linearized) GNNs with residual connections and normalization layers. We establish that (a) for residual connections, the incorporation of the initial features at each layer can prevent the signal from becoming too smooth, and determines the subspace of possible node representations; (b) batch normalization prevents a complete collapse of the output embedding space to a one-dimensional subspace through the individual rescaling of each column of the feature matrix. This results in the convergence of node representations to the top-$k$ eigenspace of the message-passing operator; (c) moreover, we show that the centering step of a normalization layer -- which can be understood as a projection -- alters the graph signal in message-passing in such a way that relevant information can become harder to extract. We therefore introduce a novel, principled normalization layer called GraphNormv2 in which the centering step is learned such that it does not distort the original graph signal in an undesirable way. Experimental results confirm the effectiveness of our method.
6/13/2024
Transfer Entropy in Graph Convolutional Neural Networks
Adrian Moldovan, Angel Cac{t}aron, Ru{a}zvan Andonie
0
0
Graph Convolutional Networks (GCN) are Graph Neural Networks where the convolutions are applied over a graph. In contrast to Convolutional Neural Networks, GCN's are designed to perform inference on graphs, where the number of nodes can vary, and the nodes are unordered. In this study, we address two important challenges related to GCNs: i) oversmoothing; and ii) the utilization of node relational properties (i.e., heterophily and homophily). Oversmoothing is the degradation of the discriminative capacity of nodes as a result of repeated aggregations. Heterophily is the tendency for nodes of different classes to connect, whereas homophily is the tendency of similar nodes to connect. We propose a new strategy for addressing these challenges in GCNs based on Transfer Entropy (TE), which measures of the amount of directed transfer of information between two time varying nodes. Our findings indicate that using node heterophily and degree information as a node selection mechanism, along with feature-based TE calculations, enhances accuracy across various GCN models. Our model can be easily modified to improve classification accuracy of a GCN model. As a trade off, this performance boost comes with a significant computational overhead when the TE is computed for many graph nodes.
6/12/2024