Graph Transformers: A Survey

0

Sign in to get full access
Overview
- This paper provides a comprehensive survey of graph transformers, a class of deep learning models that combine the power of graph neural networks and the attention mechanism of transformers.
- Graph transformers have shown promising results in various graph-based tasks, such as graph classification, semi-supervised node classification, and graph generation.
- The survey covers the key concepts, architectures, and applications of graph transformers, as well as their connection to the broader field of transformer-based time series synthesis and large language models.
Plain English Explanation
Graph transformers are a type of deep learning model that combine two powerful techniques: graph neural networks and transformers. Graph neural networks are good at analyzing and understanding data that can be represented as a graph, such as social networks, transportation networks, or molecular structures. Transformers, on the other hand, are a type of model that has revolutionized natural language processing by using an attention mechanism to focus on the most relevant parts of the input.
By combining these two approaches, graph transformers can take advantage of the strengths of both. They can learn rich representations of graph-structured data and use the attention mechanism to focus on the most important parts of the graph when solving tasks like graph classification, node classification, or graph generation.
The survey paper covered in this blog post provides an in-depth look at the different types of graph transformers, how they work, and the various applications they have been used for. The authors also discuss how graph transformers relate to other areas of deep learning, such as time series synthesis and large language models.
Technical Explanation
The paper begins by introducing the key concepts and notations related to graph data and graph neural networks. It then delves into the architecture of graph transformers, which typically consist of a graph encoder and a transformer-based decoder.
The graph encoder uses graph neural network layers to learn node and edge representations, capturing the structural information in the input graph. The transformer-based decoder then applies attention mechanisms to these learned representations, allowing the model to focus on the most relevant parts of the graph when generating outputs or making predictions.
The survey covers various graph transformer architectures, such as Attending to Graph Transformers, Hypergraph Transformer for Semi-Supervised Classification, and GRaNsformer: Transformer-Based Graph Generation. It also discusses how graph transformers relate to the broader fields of transformer-enabled time series synthesis and large language models.
Critical Analysis
The paper provides a comprehensive overview of graph transformers, but it also acknowledges several limitations and areas for future research. For example, the authors note that the computational complexity of graph transformers can be a challenge, particularly for large graphs, and that further work is needed to improve their scalability.
Additionally, the survey highlights the need for more interpretable and explainable graph transformer models, as the attention mechanism can sometimes be difficult to interpret, especially in complex graph-based tasks. The authors also suggest that incorporating domain-specific knowledge and incorporating other types of graph structures (e.g., hypergraphs) could be fruitful areas for future research.
Overall, the paper offers a thorough and well-researched survey of graph transformers, providing a valuable resource for researchers and practitioners in the field of graph representation learning and deep learning on graphs.
Conclusion
This survey paper on graph transformers highlights the exciting potential of combining graph neural networks and transformer-based attention mechanisms. By leveraging the strengths of both approaches, graph transformers have demonstrated impressive performance on a variety of graph-based tasks, from node classification to graph generation.
As the authors note, there is still much work to be done to address the limitations of graph transformers, such as their computational complexity and the interpretability of their attention mechanisms. However, the continued progress in this area could lead to significant advancements in our ability to understand and model complex graph-structured data, with applications in fields ranging from social network analysis to drug discovery.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Graph Transformers: A Survey
Ahsan Shehzad, Feng Xia, Shagufta Abid, Ciyuan Peng, Shuo Yu, Dongyu Zhang, Karin Verspoor
Graph transformers are a recent advancement in machine learning, offering a new class of neural network models for graph-structured data. The synergy between transformers and graph learning demonstrates strong performance and versatility across various graph-related tasks. This survey provides an in-depth review of recent progress and challenges in graph transformer research. We begin with foundational concepts of graphs and transformers. We then explore design perspectives of graph transformers, focusing on how they integrate graph inductive biases and graph attention mechanisms into the transformer architecture. Furthermore, we propose a taxonomy classifying graph transformers based on depth, scalability, and pre-training strategies, summarizing key principles for effective development of graph transformer models. Beyond technical analysis, we discuss the applications of graph transformer models for node-level, edge-level, and graph-level tasks, exploring their potential in other application scenarios as well. Finally, we identify remaining challenges in the field, such as scalability and efficiency, generalization and robustness, interpretability and explainability, dynamic and complex graphs, as well as data quality and diversity, charting future directions for graph transformer research.
Read more7/16/2024
💬
0
Attending to Graph Transformers
Luis Muller, Mikhail Galkin, Christopher Morris, Ladislav Ramp'av{s}ek
Recently, transformer architectures for graphs emerged as an alternative to established techniques for machine learning with graphs, such as (message-passing) graph neural networks. So far, they have shown promising empirical results, e.g., on molecular prediction datasets, often attributed to their ability to circumvent graph neural networks' shortcomings, such as over-smoothing and over-squashing. Here, we derive a taxonomy of graph transformer architectures, bringing some order to this emerging field. We overview their theoretical properties, survey structural and positional encodings, and discuss extensions for important graph classes, e.g., 3D molecular graphs. Empirically, we probe how well graph transformers can recover various graph properties, how well they can deal with heterophilic graphs, and to what extent they prevent over-squashing. Further, we outline open challenges and research direction to stimulate future work. Our code is available at https://github.com/luis-mueller/probing-graph-transformers.
Read more4/1/2024
🧠
0
A Survey on Graph Neural Networks and Graph Transformers in Computer Vision: A Task-Oriented Perspective
Chaoqi Chen, Yushuang Wu, Qiyuan Dai, Hong-Yu Zhou, Mutian Xu, Sibei Yang, Xiaoguang Han, Yizhou Yu
Graph Neural Networks (GNNs) have gained momentum in graph representation learning and boosted the state of the art in a variety of areas, such as data mining (emph{e.g.,} social network analysis and recommender systems), computer vision (emph{e.g.,} object detection and point cloud learning), and natural language processing (emph{e.g.,} relation extraction and sequence learning), to name a few. With the emergence of Transformers in natural language processing and computer vision, graph Transformers embed a graph structure into the Transformer architecture to overcome the limitations of local neighborhood aggregation while avoiding strict structural inductive biases. In this paper, we present a comprehensive review of GNNs and graph Transformers in computer vision from a task-oriented perspective. Specifically, we divide their applications in computer vision into five categories according to the modality of input data, emph{i.e.,} 2D natural images, videos, 3D data, vision + language, and medical images. In each category, we further divide the applications according to a set of vision tasks. Such a task-oriented taxonomy allows us to examine how each task is tackled by different GNN-based approaches and how well these approaches perform. Based on the necessary preliminaries, we provide the definitions and challenges of the tasks, in-depth coverage of the representative approaches, as well as discussions regarding insights, limitations, and future directions.
Read more8/15/2024
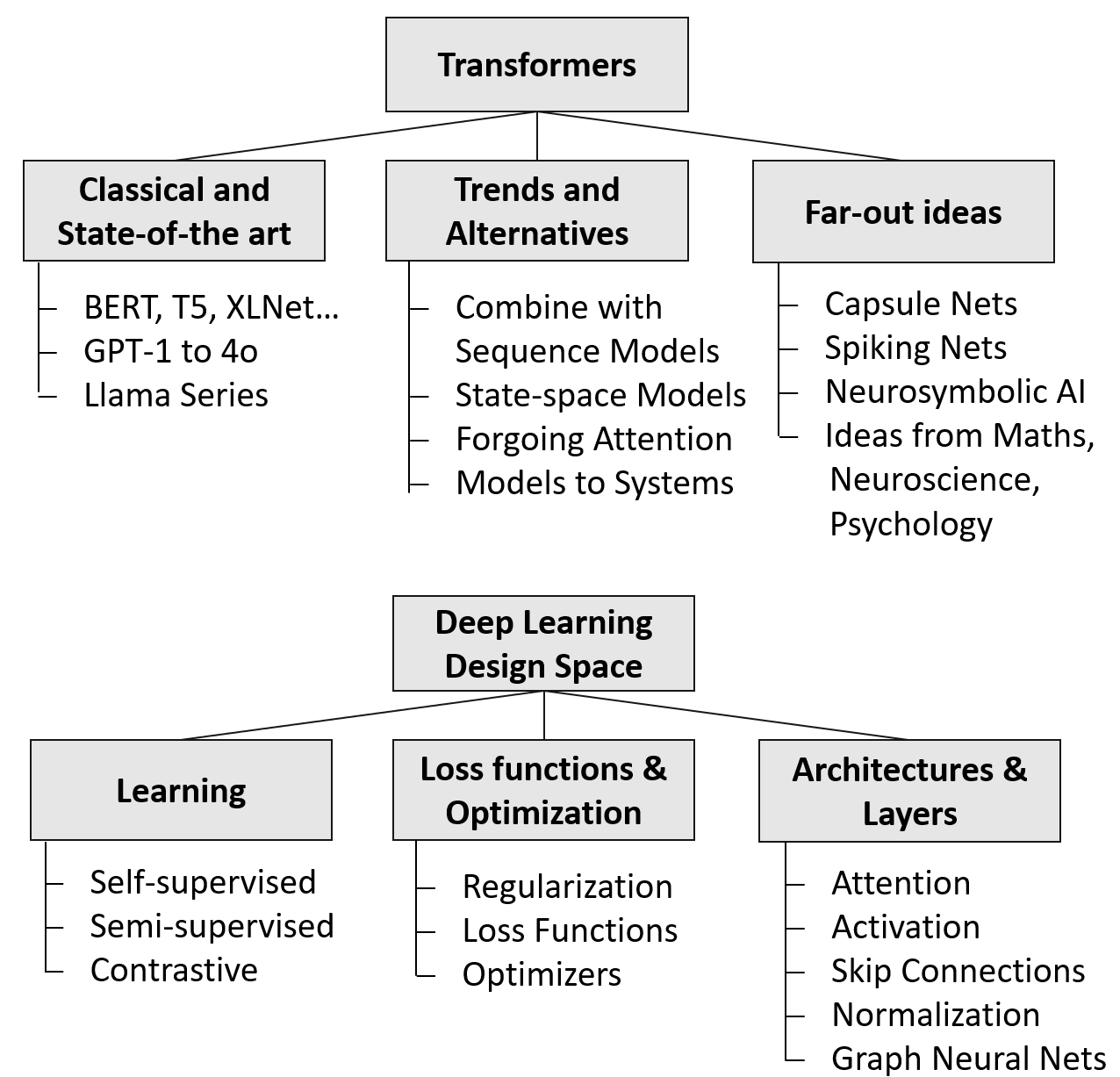
0
What comes after transformers? -- A selective survey connecting ideas in deep learning
Johannes Schneider
Transformers have become the de-facto standard model in artificial intelligence since 2017 despite numerous shortcomings ranging from energy inefficiency to hallucinations. Research has made a lot of progress in improving elements of transformers, and, more generally, deep learning manifesting in many proposals for architectures, layers, optimization objectives, and optimization techniques. For researchers it is difficult to keep track of such developments on a broader level. We provide a comprehensive overview of the many important, recent works in these areas to those who already have a basic understanding of deep learning. Our focus differs from other works, as we target specifically novel, alternative potentially disruptive approaches to transformers as well as successful ideas of recent deep learning. We hope that such a holistic and unified treatment of influential, recent works and novel ideas helps researchers to form new connections between diverse areas of deep learning. We identify and discuss multiple patterns that summarize the key strategies for successful innovations over the last decade as well as works that can be seen as rising stars. Especially, we discuss attempts on how to improve on transformers covering (partially) proven methods such as state space models but also including far-out ideas in deep learning that seem promising despite not achieving state-of-the-art results. We also cover a discussion on recent state-of-the-art models such as OpenAI's GPT series and Meta's LLama models and, Google's Gemini model family.
Read more8/2/2024