GraphFM: A Scalable Framework for Multi-Graph Pretraining

0

Sign in to get full access
Overview
- Introduces a scalable framework called GraphFM for pretraining on multiple graph datasets
- Demonstrates strong performance on diverse graph tasks compared to existing methods
- Leverages a pure transformer architecture to handle different graph types and sizes
Plain English Explanation
GraphFM: A Scalable Framework for Multi-Graph Pretraining describes a new approach for training machine learning models on graph-structured data. The key idea is to create a "foundation model" that can be pretrained on a variety of graph datasets, and then fine-tuned for different graph-related tasks.
This is similar to how large language models like BERT have been pretrained on massive text corpora and then adapted to various natural language processing tasks. The researchers hypothesized that a similar approach could work well for graph data, which occurs in many domains like social networks, molecular structures, and knowledge graphs.
The GraphFM framework uses a pure transformer architecture to handle different types and sizes of graphs, without relying on specialized graph neural network layers. This makes the approach more scalable and flexible than previous methods.
Technical Explanation
The key elements of the GraphFM framework include:
-
Multi-graph pretraining: The model is trained on a diverse set of graph datasets, including social networks, molecular structures, and knowledge graphs. This allows the model to learn general patterns and representations that can be transferred to a variety of downstream tasks.
-
Pure transformer architecture: GraphFM uses a standard transformer encoder-decoder architecture, without specialized graph neural network layers. This makes the model more scalable and easier to implement than previous graph-specific approaches.
-
Scalable training: The researchers developed efficient training techniques, such as gradient checkpointing and mixed precision training, to enable pretraining on large-scale graph datasets.
-
Comprehensive evaluation: The paper evaluates GraphFM on a wide range of graph tasks, including node classification, link prediction, and graph classification. The results demonstrate that the pretrained model can outperform specialized models on many benchmarks.
Critical Analysis
The GraphFM paper makes a compelling case for the potential of graph foundation models, but there are a few caveats to consider:
-
The paper focuses on relatively small and well-structured graph datasets, so it's unclear how well the approach would scale to truly massive and diverse real-world graph data.
-
The authors note that GraphFM's performance can be sensitive to the choice of pretraining datasets and tasks, so careful curation of the pretraining data may be required.
-
The pure transformer architecture may not be optimal for all graph-related tasks, and specialized graph neural network layers could still provide benefits in certain domains.
Overall, the GraphFM research is a promising step towards more scalable and flexible graph representation learning, but further investigation is needed to fully understand the strengths and limitations of this approach.
Conclusion
The GraphFM paper introduces a novel framework for pretraining on multiple graph datasets and demonstrates its effectiveness on a wide range of graph-related tasks. This work represents an important step towards more robust and generalizable graph representation learning, which could have significant implications for applications in social networks, drug discovery, knowledge management, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GraphFM: A Scalable Framework for Multi-Graph Pretraining
Divyansha Lachi, Mehdi Azabou, Vinam Arora, Eva Dyer
Graph neural networks are typically trained on individual datasets, often requiring highly specialized models and extensive hyperparameter tuning. This dataset-specific approach arises because each graph dataset often has unique node features and diverse connectivity structures, making it difficult to build a generalist model. To address these challenges, we introduce a scalable multi-graph multi-task pretraining approach specifically tailored for node classification tasks across diverse graph datasets from different domains. Our method, Graph Foundation Model (GraphFM), leverages a Perceiver-based encoder that employs learned latent tokens to compress domain-specific features into a common latent space. This approach enhances the model's ability to generalize across different graphs and allows for scaling across diverse data. We demonstrate the efficacy of our approach by training a model on 152 different graph datasets comprising over 7.4 million nodes and 189 million edges, establishing the first set of scaling laws for multi-graph pretraining on datasets spanning many domains (e.g., molecules, citation and product graphs). Our results show that pretraining on a diverse array of real and synthetic graphs improves the model's adaptability and stability, while performing competitively with state-of-the-art specialist models. This work illustrates that multi-graph pretraining can significantly reduce the burden imposed by the current graph training paradigm, unlocking new capabilities for the field of graph neural networks by creating a single generalist model that performs competitively across a wide range of datasets and tasks.
Read more7/17/2024
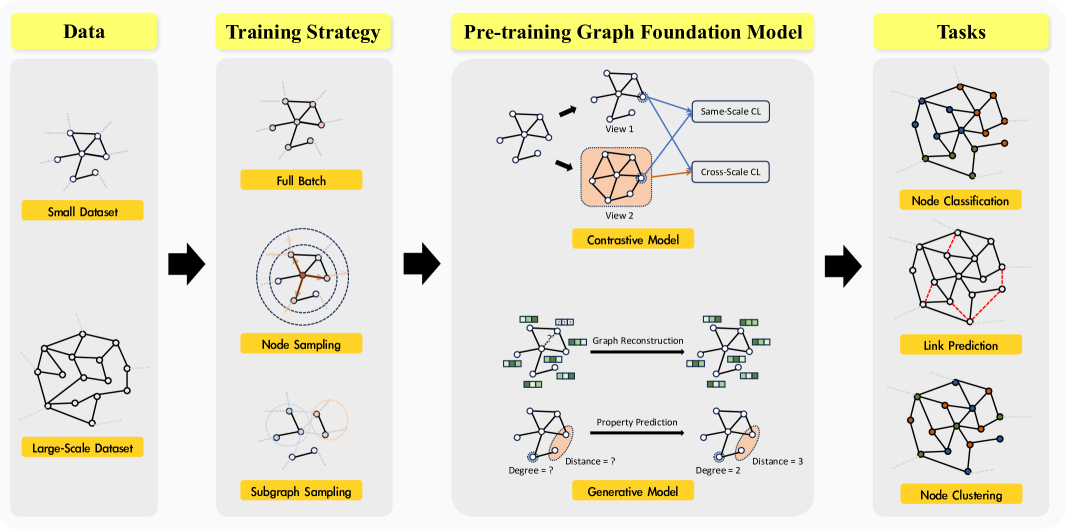
0
GraphFM: A Comprehensive Benchmark for Graph Foundation Model
Yuhao Xu, Xinqi Liu, Keyu Duan, Yi Fang, Yu-Neng Chuang, Daochen Zha, Qiaoyu Tan
Foundation Models (FMs) serve as a general class for the development of artificial intelligence systems, offering broad potential for generalization across a spectrum of downstream tasks. Despite extensive research into self-supervised learning as the cornerstone of FMs, several outstanding issues persist in Graph Foundation Models that rely on graph self-supervised learning, namely: 1) Homogenization. The extent of generalization capability on downstream tasks remains unclear. 2) Scalability. It is unknown how effectively these models can scale to large datasets. 3) Efficiency. The training time and memory usage of these models require evaluation. 4) Training Stop Criteria. Determining the optimal stopping strategy for pre-training across multiple tasks to maximize performance on downstream tasks. To address these questions, we have constructed a rigorous benchmark that thoroughly analyzes and studies the generalization and scalability of self-supervised Graph Neural Network (GNN) models. Regarding generalization, we have implemented and compared the performance of various self-supervised GNN models, trained to generate node representations, across tasks such as node classification, link prediction, and node clustering. For scalability, we have compared the performance of various models after training using full-batch and mini-batch strategies. Additionally, we have assessed the training efficiency of these models by conducting experiments to test their GPU memory usage and throughput. Through these experiments, we aim to provide insights to motivate future research. The code for this benchmark is publicly available at https://github.com/NYUSHCS/GraphFM.
Read more6/17/2024

0
Generalizing Graph Transformers Across Diverse Graphs and Tasks via Pre-Training on Industrial-Scale Data
Yufei He, Zhenyu Hou, Yukuo Cen, Feng He, Xu Cheng, Bryan Hooi
Graph pre-training has been concentrated on graph-level on small graphs (e.g., molecular graphs) or learning node representations on a fixed graph. Extending graph pre-trained models to web-scale graphs with billions of nodes in industrial scenarios, while avoiding negative transfer across graphs or tasks, remains a challenge. We aim to develop a general graph pre-trained model with inductive ability that can make predictions for unseen new nodes and even new graphs. In this work, we introduce a scalable transformer-based graph pre-training framework called PGT (Pre-trained Graph Transformer). Specifically, we design a flexible and scalable graph transformer as the backbone network. Meanwhile, based on the masked autoencoder architecture, we design two pre-training tasks: one for reconstructing node features and the other one for reconstructing local structures. Unlike the original autoencoder architecture where the pre-trained decoder is discarded, we propose a novel strategy that utilizes the decoder for feature augmentation. We have deployed our framework on Tencent's online game data. Extensive experiments have demonstrated that our framework can perform pre-training on real-world web-scale graphs with over 540 million nodes and 12 billion edges and generalizes effectively to unseen new graphs with different downstream tasks. We further conduct experiments on the publicly available ogbn-papers100M dataset, which consists of 111 million nodes and 1.6 billion edges. Our framework achieves state-of-the-art performance on both industrial datasets and public datasets, while also enjoying scalability and efficiency.
Read more9/16/2024
👨🏫
0
Text-Free Multi-domain Graph Pre-training:Toward Graph Foundation Models
Xingtong Yu, Chang Zhou, Yuan Fang, Xinming Zhang
Given the ubiquity of graph data, it is intriguing to ask: Is it possible to train a graph foundation model on a broad range of graph data across diverse domains? A major hurdle toward this goal lies in the fact that graphs from different domains often exhibit profoundly divergent characteristics. Although there have been some initial efforts in integrating multi-domain graphs for pre-training, they primarily rely on textual descriptions to align the graphs, limiting their application to text-attributed graphs. Moreover, different source domains may conflict or interfere with each other, and their relevance to the target domain can vary significantly. To address these issues, we propose MDGPT, a text free Multi-Domain Graph Pre-Training and adaptation framework designed to exploit multi-domain knowledge for graph learning. First, we propose a set of domain tokens to to align features across source domains for synergistic pre-training. Second, we propose a dual prompts, consisting of a unifying prompt and a mixing prompt, to further adapt the target domain with unified multi-domain knowledge and a tailored mixture of domain-specific knowledge. Finally, we conduct extensive experiments involving six public datasets to evaluate and analyze MDGPT, which outperforms prior art by up to 37.9%.
Read more5/29/2024