Position: Graph Foundation Models are Already Here

0
🌐
Sign in to get full access
Overview
- Graph Foundation Models (GFMs) are a new research area in graph learning, aiming to develop graph models that can be applied to a wide range of tasks and domains.
- GFMs present unique challenges compared to traditional Graph Neural Networks (GNNs), which are typically trained from scratch for specific tasks.
- The key challenge in building GFMs is effectively leveraging large and diverse graph datasets to achieve positive transfer.
- The paper proposes a "graph vocabulary" perspective, where the basic transferable units underlying graphs encode the invariance on graphs, to guide future GFM development.
Plain English Explanation
Graph Foundation Models (GFMs) are a new and exciting development in the field of graph learning. Unlike traditional Graph Neural Networks (GNNs), which are typically trained from scratch for specific tasks, GFMs are designed to be more broadly applicable across a wide range of tasks and domains.
The idea behind GFMs is to leverage large and diverse graph datasets to train models that can capture the fundamental building blocks or "vocabulary" of graphs. This "graph vocabulary" would encode the essential features and patterns that are common across different graph-based applications, allowing the models to be more effectively transferred and adapted to new tasks.
To illustrate with an analogy, think of how language models in natural language processing (NLP), such as GPT-3, have been trained on massive amounts of text data to develop a deep understanding of language, which can then be applied to a variety of NLP tasks. Similarly, the goal of GFMs is to develop a foundational understanding of graph structures that can be leveraged across a wide range of graph-based applications, from social network analysis to autonomous vehicle planning.
By focusing on this "graph vocabulary" perspective, the researchers hope to guide the future development of GFMs in line with the scaling laws that have driven the success of large language models in NLP. This could lead to significant advancements in the field of graph-based AI and machine learning.
Technical Explanation
The paper proposes a novel perspective for the development of Graph Foundation Models (GFMs) by advocating for the concept of a "graph vocabulary". The core idea is that the basic transferable units underlying graphs should encode the invariance on graphs, similar to how the vocabulary in natural language models captures the fundamental building blocks of language.
To ground the construction of this graph vocabulary, the authors discuss three essential aspects: network analysis, expressiveness, and stability. Network analysis focuses on understanding the structural properties and patterns within graphs, which can serve as the building blocks for the graph vocabulary. Expressiveness considers the ability of the vocabulary to capture the rich and diverse information contained in graphs, while stability addresses the need for the vocabulary to be robust to variations in graph structure.
By framing GFM development through the lens of this "graph vocabulary", the researchers aim to align the future design of GFMs with the scaling laws that have driven the success of large language models in the natural language processing (NLP) domain, as seen in models like GPT-3.
The paper also discusses the unique challenges in constructing GFMs compared to traditional Graph Neural Networks (GNNs). While GNNs are typically trained from scratch for specific tasks on particular datasets, GFMs must effectively leverage vast and diverse graph data to achieve positive transfer across a wide range of applications, including knowledge graph reasoning and 3D computer vision.
Critical Analysis
The paper presents a compelling perspective on the development of Graph Foundation Models (GFMs) by introducing the concept of a "graph vocabulary". This approach aligns with the success of large language models in the natural language processing domain and holds promise for advancing the field of graph-based AI and machine learning.
However, the paper also acknowledges the significant challenges in constructing GFMs, particularly in effectively leveraging large and diverse graph datasets to achieve positive transfer across various tasks and domains. Ensuring the expressiveness and stability of the graph vocabulary to capture the rich and diverse information in graphs is a non-trivial task that requires further research and experimentation.
Additionally, the paper does not provide a detailed implementation or evaluation of the proposed "graph vocabulary" approach. While the conceptual framework is well-articulated, more empirical evidence and practical insights would be valuable to assess the viability and potential impact of this perspective on the development of GFMs.
Moreover, the paper does not address potential ethical or societal implications of GFMs, such as the risks of bias, fairness, or privacy concerns that may arise from the large-scale deployment of such models. As the field of graph-based AI continues to evolve, it will be crucial to consider these important considerations alongside the technical advancements.
Overall, the paper presents a novel and thought-provoking perspective on the development of Graph Foundation Models, and the "graph vocabulary" concept offers a promising direction for future research in this rapidly evolving field of graph machine learning.
Conclusion
Graph Foundation Models (GFMs) are an emerging research area that holds significant potential for advancing the field of graph-based AI and machine learning. By proposing the concept of a "graph vocabulary" to guide the development of GFMs, the paper introduces a new perspective that aligns with the scaling laws that have driven the success of large language models in natural language processing.
The "graph vocabulary" approach aims to capture the fundamental building blocks and patterns inherent in graph structures, enabling GFMs to be more effectively transferred and adapted to a wide range of tasks and domains. This could lead to significant advancements in areas such as social network analysis, knowledge graph reasoning, and autonomous vehicle planning.
While the paper highlights the unique challenges in constructing GFMs, the "graph vocabulary" perspective offers a promising direction for future research. As the field of graph machine learning continues to evolve, the insights and ideas presented in this paper could help shape the development of increasingly powerful and versatile graph-based AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
0
Position: Graph Foundation Models are Already Here
Haitao Mao, Zhikai Chen, Wenzhuo Tang, Jianan Zhao, Yao Ma, Tong Zhao, Neil Shah, Mikhail Galkin, Jiliang Tang
Graph Foundation Models (GFMs) are emerging as a significant research topic in the graph domain, aiming to develop graph models trained on extensive and diverse data to enhance their applicability across various tasks and domains. Developing GFMs presents unique challenges over traditional Graph Neural Networks (GNNs), which are typically trained from scratch for specific tasks on particular datasets. The primary challenge in constructing GFMs lies in effectively leveraging vast and diverse graph data to achieve positive transfer. Drawing inspiration from existing foundation models in the CV and NLP domains, we propose a novel perspective for the GFM development by advocating for a ``graph vocabulary'', in which the basic transferable units underlying graphs encode the invariance on graphs. We ground the graph vocabulary construction from essential aspects including network analysis, expressiveness, and stability. Such a vocabulary perspective can potentially advance the future GFM design in line with the neural scaling laws. All relevant resources with GFM design can be found here.
Read more6/3/2024

0
Towards Graph Foundation Models: A Survey and Beyond
Jiawei Liu, Cheng Yang, Zhiyuan Lu, Junze Chen, Yibo Li, Mengmei Zhang, Ting Bai, Yuan Fang, Lichao Sun, Philip S. Yu, Chuan Shi
Foundation models have emerged as critical components in a variety of artificial intelligence applications, and showcase significant success in natural language processing and several other domains. Meanwhile, the field of graph machine learning is witnessing a paradigm transition from shallow methods to more sophisticated deep learning approaches. The capabilities of foundation models to generalize and adapt motivate graph machine learning researchers to discuss the potential of developing a new graph learning paradigm. This paradigm envisions models that are pre-trained on extensive graph data and can be adapted for various graph tasks. Despite this burgeoning interest, there is a noticeable lack of clear definitions and systematic analyses pertaining to this new domain. To this end, this article introduces the concept of Graph Foundation Models (GFMs), and offers an exhaustive explanation of their key characteristics and underlying technologies. We proceed to classify the existing work related to GFMs into three distinct categories, based on their dependence on graph neural networks and large language models. In addition to providing a thorough review of the current state of GFMs, this article also outlooks potential avenues for future research in this rapidly evolving domain.
Read more7/2/2024

0
Text-space Graph Foundation Models: Comprehensive Benchmarks and New Insights
Zhikai Chen, Haitao Mao, Jingzhe Liu, Yu Song, Bingheng Li, Wei Jin, Bahare Fatemi, Anton Tsitsulin, Bryan Perozzi, Hui Liu, Jiliang Tang
Given the ubiquity of graph data and its applications in diverse domains, building a Graph Foundation Model (GFM) that can work well across different graphs and tasks with a unified backbone has recently garnered significant interests. A major obstacle to achieving this goal stems from the fact that graphs from different domains often exhibit diverse node features. Inspired by multi-modal models that align different modalities with natural language, the text has recently been adopted to provide a unified feature space for diverse graphs. Despite the great potential of these text-space GFMs, current research in this field is hampered by two problems. First, the absence of a comprehensive benchmark with unified problem settings hinders a clear understanding of the comparative effectiveness and practical value of different text-space GFMs. Second, there is a lack of sufficient datasets to thoroughly explore the methods' full potential and verify their effectiveness across diverse settings. To address these issues, we conduct a comprehensive benchmark providing novel text-space datasets and comprehensive evaluation under unified problem settings. Empirical results provide new insights and inspire future research directions. Our code and data are publicly available from url{https://github.com/CurryTang/TSGFM}.
Read more6/18/2024
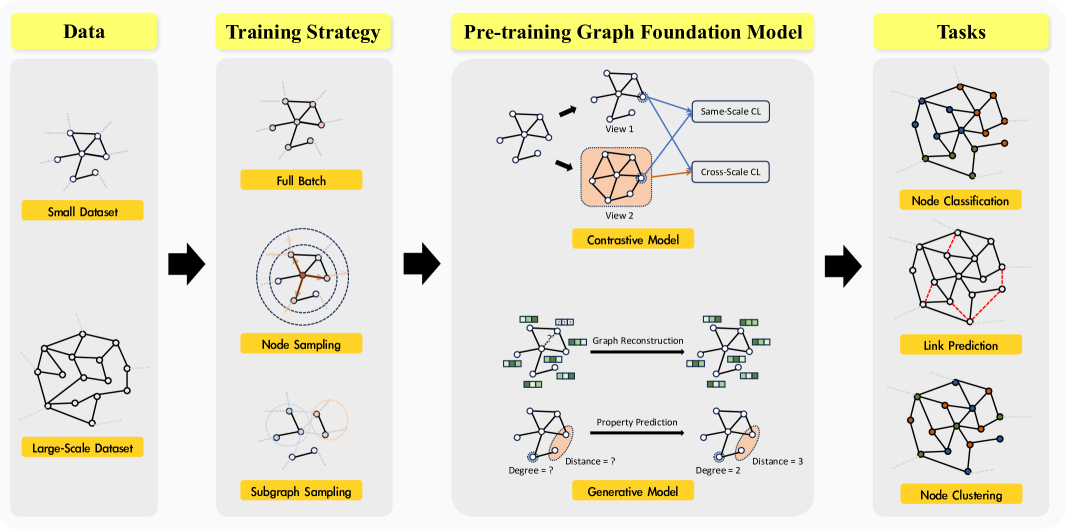
0
GraphFM: A Comprehensive Benchmark for Graph Foundation Model
Yuhao Xu, Xinqi Liu, Keyu Duan, Yi Fang, Yu-Neng Chuang, Daochen Zha, Qiaoyu Tan
Foundation Models (FMs) serve as a general class for the development of artificial intelligence systems, offering broad potential for generalization across a spectrum of downstream tasks. Despite extensive research into self-supervised learning as the cornerstone of FMs, several outstanding issues persist in Graph Foundation Models that rely on graph self-supervised learning, namely: 1) Homogenization. The extent of generalization capability on downstream tasks remains unclear. 2) Scalability. It is unknown how effectively these models can scale to large datasets. 3) Efficiency. The training time and memory usage of these models require evaluation. 4) Training Stop Criteria. Determining the optimal stopping strategy for pre-training across multiple tasks to maximize performance on downstream tasks. To address these questions, we have constructed a rigorous benchmark that thoroughly analyzes and studies the generalization and scalability of self-supervised Graph Neural Network (GNN) models. Regarding generalization, we have implemented and compared the performance of various self-supervised GNN models, trained to generate node representations, across tasks such as node classification, link prediction, and node clustering. For scalability, we have compared the performance of various models after training using full-batch and mini-batch strategies. Additionally, we have assessed the training efficiency of these models by conducting experiments to test their GPU memory usage and throughput. Through these experiments, we aim to provide insights to motivate future research. The code for this benchmark is publicly available at https://github.com/NYUSHCS/GraphFM.
Read more6/17/2024