Grasp as You Say: Language-guided Dexterous Grasp Generation

0

Sign in to get full access
Overview
- This paper presents a novel approach for generating dexterous grasps for objects using language guidance.
- The proposed method, called "Grasp as You Say", leverages large language models to transform natural language descriptions into high-quality, diverse grasps.
- The system is trained on a large dataset of human-annotated grasps and can generalize to new objects and language prompts.
- Experiments show the approach outperforms previous state-of-the-art methods for language-guided grasp generation.
Plain English Explanation
The Grasp as You Say paper describes a way to have robots grasp and pick up objects by following verbal instructions. Rather than relying solely on visual information, this system uses a large language model to translate natural language descriptions into detailed grasp plans.
For example, if you tell the robot "Grasp the mug by the handle", the system can generate a specific hand pose and finger configuration to securely pick up the mug in the way you described. This allows for more flexible and dexterous grasping compared to traditional vision-based methods.
The key innovation is using language as an additional input to guide the robot's grasping behavior. By learning from a dataset of human-annotated grasps paired with textual descriptions, the system can generalize to new objects and novel language prompts. This makes the robot's grasping more intuitive and aligned with how humans naturally think about manipulating objects.
Technical Explanation
The Grasp as You Say method uses a Transformer-based neural network architecture to integrate language and visual information for dexterous grasp generation.
The model takes as input an object point cloud and a natural language description of the desired grasp. It then outputs a set of diverse grasp candidates, each represented as a 6D pose (position and orientation) and a hand configuration (joint angles).
The key technical components are:
- A language encoder that maps the input text into a compact semantic representation
- A point cloud encoder that extracts visual features from the object geometry
- A grasp proposal module that combines the language and visual features to generate grasp candidates
- A grasp ranking module that scores and selects the most promising grasps
The model is trained end-to-end on a large dataset of human-demonstrated grasps annotated with textual descriptions. During inference, the system can take novel language prompts and object point clouds to synthesize appropriate grasps.
Critical Analysis
The Grasp as You Say approach represents an exciting advancement in language-guided robotic manipulation. By incorporating natural language as an additional modality, the system can achieve more flexible and intuitive grasping behavior compared to vision-only methods.
However, the paper also acknowledges several limitations and areas for future work. The dataset used for training, while large, may not capture the full range of real-world grasping scenarios and language variation. Additionally, the system is currently limited to single-object grasping and does not consider more complex manipulation tasks involving multiple objects or sequential actions.
Further research is needed to scale the approach to more challenging environments and robotic platforms. Integrating the language-guided grasping with higher-level task planning and reasoning could also unlock new capabilities for language-driven robot control.
Overall, the Grasp as You Say method represents an important step towards more natural and intuitive robot manipulation. By bridging the gap between human language and robotic action, it opens up new possibilities for human-robot collaboration and assistive technologies.
Conclusion
The Grasp as You Say paper introduces a novel approach for generating dexterous grasps using language guidance. By combining large language models with visual perception, the system can translate natural language descriptions into high-quality grasp plans, enabling more flexible and intuitive robot manipulation.
The key innovation is the ability to leverage textual information as an additional input for guiding robotic grasping, alongside traditional vision-based approaches. This allows the system to generalize beyond pre-defined grasping strategies and adapt to a wide range of object and language scenarios.
While the current system has some limitations, the Grasp as You Say method represents an important step forward in language-driven robot control. As this line of research continues to evolve, we may see increasingly natural and human-like robot manipulators that can seamlessly collaborate with people to accomplish complex tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Grasp as You Say: Language-guided Dexterous Grasp Generation
Yi-Lin Wei, Jian-Jian Jiang, Chengyi Xing, Xiantuo Tan, Xiao-Ming Wu, Hao Li, Mark Cutkosky, Wei-Shi Zheng
This paper explores a novel task Dexterous Grasp as You Say (DexGYS), enabling robots to perform dexterous grasping based on human commands expressed in natural language. However, the development of this field is hindered by the lack of datasets with natural human guidance; thus, we propose a language-guided dexterous grasp dataset, named DexGYSNet, offering high-quality dexterous grasp annotations along with flexible and fine-grained human language guidance. Our dataset construction is cost-efficient, with the carefully-design hand-object interaction retargeting strategy, and the LLM-assisted language guidance annotation system. Equipped with this dataset, we introduce the DexGYSGrasp framework for generating dexterous grasps based on human language instructions, with the capability of producing grasps that are intent-aligned, high quality and diversity. To achieve this capability, our framework decomposes the complex learning process into two manageable progressive objectives and introduce two components to realize them. The first component learns the grasp distribution focusing on intention alignment and generation diversity. And the second component refines the grasp quality while maintaining intention consistency. Extensive experiments are conducted on DexGYSNet and real world environment for validation.
Read more5/30/2024
0
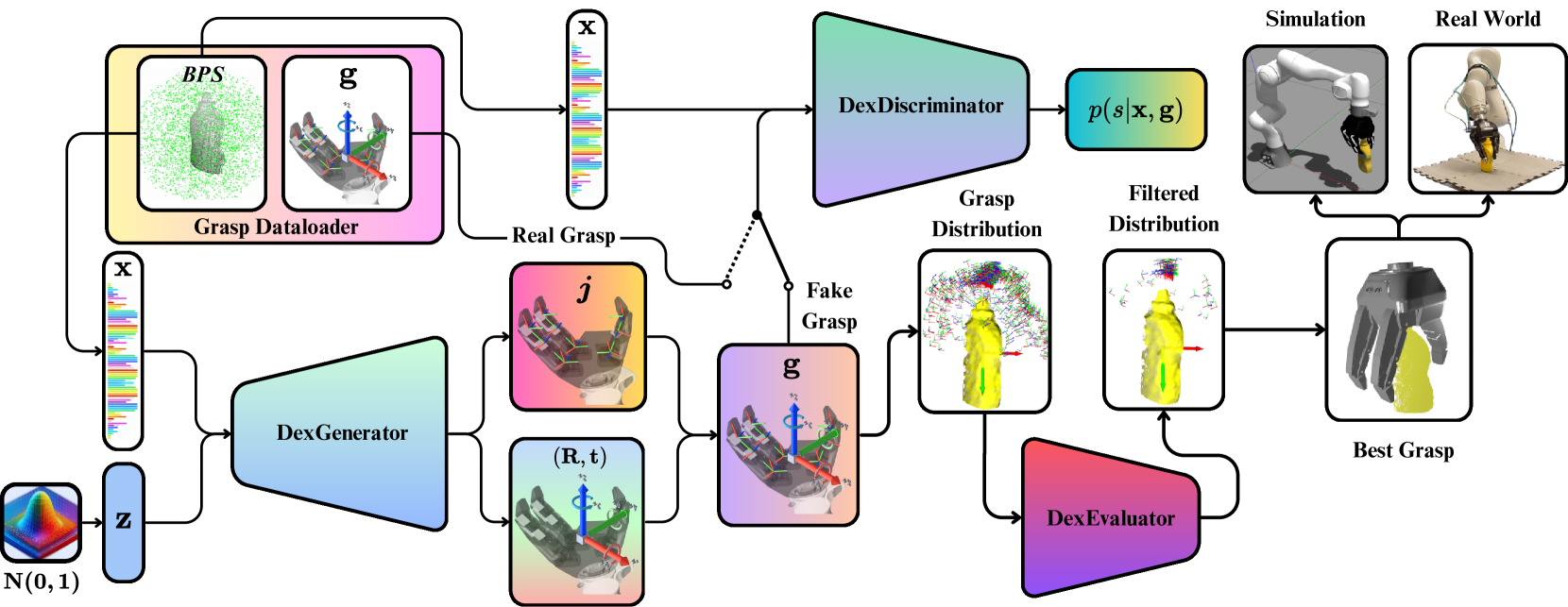
DexGANGrasp: Dexterous Generative Adversarial Grasping Synthesis for Task-Oriented Manipulation
Qian Feng, David S. Martinez Lema, Mohammadhossein Malmir, Hang Li, Jianxiang Feng, Zhaopeng Chen, Alois Knoll
We introduce DexGanGrasp, a dexterous grasping synthesis method that generates and evaluates grasps with single view in real time. DexGanGrasp comprises a Conditional Generative Adversarial Networks (cGANs)-based DexGenerator to generate dexterous grasps and a discriminator-like DexEvalautor to assess the stability of these grasps. Extensive simulation and real-world expriments showcases the effectiveness of our proposed method, outperforming the baseline FFHNet with an 18.57% higher success rate in real-world evaluation. We further extend DexGanGrasp to DexAfford-Prompt, an open-vocabulary affordance grounding pipeline for dexterous grasping leveraging Multimodal Large Language Models (MLLMs) and Vision Language Models (VLMs), to achieve task-oriented grasping with successful real-world deployments.
Read more7/25/2024
⛏️
0
Dexterous Grasp Transformer
Guo-Hao Xu, Yi-Lin Wei, Dian Zheng, Xiao-Ming Wu, Wei-Shi Zheng
In this work, we propose a novel discriminative framework for dexterous grasp generation, named Dexterous Grasp TRansformer (DGTR), capable of predicting a diverse set of feasible grasp poses by processing the object point cloud with only one forward pass. We formulate dexterous grasp generation as a set prediction task and design a transformer-based grasping model for it. However, we identify that this set prediction paradigm encounters several optimization challenges in the field of dexterous grasping and results in restricted performance. To address these issues, we propose progressive strategies for both the training and testing phases. First, the dynamic-static matching training (DSMT) strategy is presented to enhance the optimization stability during the training phase. Second, we introduce the adversarial-balanced test-time adaptation (AB-TTA) with a pair of adversarial losses to improve grasping quality during the testing phase. Experimental results on the DexGraspNet dataset demonstrate the capability of DGTR to predict dexterous grasp poses with both high quality and diversity. Notably, while keeping high quality, the diversity of grasp poses predicted by DGTR significantly outperforms previous works in multiple metrics without any data pre-processing. Codes are available at https://github.com/iSEE-Laboratory/DGTR .
Read more4/30/2024
0
GrainGrasp: Dexterous Grasp Generation with Fine-grained Contact Guidance
Fuqiang Zhao, Dzmitry Tsetserukou, Qian Liu
One goal of dexterous robotic grasping is to allow robots to handle objects with the same level of flexibility and adaptability as humans. However, it remains a challenging task to generate an optimal grasping strategy for dexterous hands, especially when it comes to delicate manipulation and accurate adjustment the desired grasping poses for objects of varying shapes and sizes. In this paper, we propose a novel dexterous grasp generation scheme called GrainGrasp that provides fine-grained contact guidance for each fingertip. In particular, we employ a generative model to predict separate contact maps for each fingertip on the object point cloud, effectively capturing the specifics of finger-object interactions. In addition, we develop a new dexterous grasping optimization algorithm that solely relies on the point cloud as input, eliminating the necessity for complete mesh information of the object. By leveraging the contact maps of different fingertips, the proposed optimization algorithm can generate precise and determinable strategies for human-like object grasping. Experimental results confirm the efficiency of the proposed scheme.
Read more5/17/2024