Grasp, See and Place: Efficient Unknown Object Rearrangement with Policy Structure Prior

0

Sign in to get full access
Overview
- This paper presents a novel policy structure and learning framework for efficient unknown object rearrangement.
- The proposed approach, called "Grasp, See and Place", leverages a learned policy structure prior to guide the robot's actions.
- The system can perform complex rearrangement tasks in multi-room environments without prior knowledge of the objects.
Plain English Explanation
The paper describes a robotic system that can rearrange unknown objects in a cluttered, multi-room environment. Unlike previous approaches, this system does not require any prior knowledge about the specific objects it will encounter. Instead, it uses a specialized policy structure that guides the robot's actions.
The key idea is to break down the rearrangement task into three main steps: Grasp, See, and Place. The robot first tries to grasp an unknown object, then uses its sensors to perceive the object and its surroundings, and finally decides where to place the object to complete the rearrangement.
This policy structure prior helps the robot operate efficiently, even in complex, multi-room environments where the objects are initially unknown. By breaking down the task in this way, the system can plan and execute the rearrangement process more effectively than approaches that try to plan the entire task all at once.
Technical Explanation
The paper introduces a new policy structure and learning framework called "Grasp, See and Place" for efficient unknown object rearrangement. The key components are:
-
Grasp Module: This module uses a pre-trained grasping policy to pick up unknown objects. The grasping policy is trained on a large dataset of object geometries to enable robust grasping of novel objects.
-
See Module: After grasping an object, the robot uses its sensors to perceive the object and its surroundings. This module builds a 3D map of the environment and identifies potential placement locations for the object.
-
Place Module: Based on the perceived information, this module decides the best location to place the grasped object to complete the rearrangement task.
The authors train these three modules using a combination of imitation learning, reinforcement learning, and self-supervised learning techniques. The modular policy structure and specialized training process enable the system to efficiently plan and execute complex rearrangement tasks in multi-room environments, even with no prior knowledge of the objects.
Critical Analysis
The paper presents a promising approach for unknown object rearrangement, but there are a few potential limitations and areas for further research:
-
The system's performance may be sensitive to the quality and coverage of the training data used for the grasping policy. Ensuring robust grasping of a wide variety of novel objects remains an open challenge.
-
The paper does not provide a thorough analysis of the system's scalability to larger, more cluttered environments with many rooms and objects. Its performance in such complex settings would be an important area for further evaluation.
-
The authors mention that the system currently assumes a static environment during task execution. Extending the approach to handle dynamic environments with moving obstacles or objects would be an interesting direction for future work.
-
While the modular policy structure is a key innovation, the training process is still quite involved, requiring multiple learning stages. Simplifying the training procedure, perhaps through more end-to-end learning, could make the system more practical and accessible.
Overall, the "Grasp, See and Place" framework represents an important step forward in enabling robots to efficiently rearrange unknown objects in complex, multi-room environments. Further research to address the identified limitations could lead to even more capable and versatile robotic rearrangement systems.
Conclusion
This paper introduces a novel policy structure and learning framework called "Grasp, See and Place" for efficient unknown object rearrangement. By breaking down the task into specialized modules for grasping, perceiving, and placing objects, the system can plan and execute complex rearrangement tasks in multi-room environments without requiring any prior knowledge about the objects.
The modular policy structure and specialized training process are key innovations that enable the robot to operate effectively, even in cluttered scenes with unknown objects. While the approach has some limitations, it represents an important step forward in developing versatile and capable robotic systems for object rearrangement and manipulation tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Grasp, See and Place: Efficient Unknown Object Rearrangement with Policy Structure Prior
Kechun Xu, Zhongxiang Zhou, Jun Wu, Haojian Lu, Rong Xiong, Yue Wang
We focus on the task of unknown object rearrangement, where a robot is supposed to re-configure the objects into a desired goal configuration specified by an RGB-D image. Recent works explore unknown object rearrangement systems by incorporating learning-based perception modules. However, they are sensitive to perception error, and pay less attention to task-level performance. In this paper, we aim to develop an effective system for unknown object rearrangement amidst perception noise. We theoretically reveal the noisy perception impacts grasp and place in a decoupled way, and show such a decoupled structure is valuable to improve task optimality. We propose GSP, a dual-loop system with the decoupled structure as prior. For the inner loop, we learn a see policy for self-confident in-hand object matching. For the outer loop, we learn a grasp policy aware of object matching and grasp capability guided by task-level rewards. We leverage the foundation model CLIP for object matching, policy learning and self-termination. A series of experiments indicate that GSP can conduct unknown object rearrangement with higher completion rates and fewer steps.
Read more8/2/2024

0
Task Planning for Object Rearrangement in Multi-room Environments
Karan Mirakhor, Sourav Ghosh, Dipanjan Das, Brojeshwar Bhowmick
Object rearrangement in a multi-room setup should produce a reasonable plan that reduces the agent's overall travel and the number of steps. Recent state-of-the-art methods fail to produce such plans because they rely on explicit exploration for discovering unseen objects due to partial observability and a heuristic planner to sequence the actions for rearrangement. This paper proposes a novel hierarchical task planner to efficiently plan a sequence of actions to discover unseen objects and rearrange misplaced objects within an untidy house to achieve a desired tidy state. The proposed method introduces several novel techniques, including (i) a method for discovering unseen objects using commonsense knowledge from large language models, (ii) a collision resolution and buffer prediction method based on Cross-Entropy Method to handle blocked goal and swap cases, (iii) a directed spatial graph-based state space for scalability, and (iv) deep reinforcement learning (RL) for producing an efficient planner. The planner interleaves the discovery of unseen objects and rearrangement to minimize the number of steps taken and overall traversal of the agent. The paper also presents new metrics and a benchmark dataset called MoPOR to evaluate the effectiveness of the rearrangement planning in a multi-room setting. The experimental results demonstrate that the proposed method effectively addresses the multi-room rearrangement problem.
Read more6/4/2024
🤿
0
Unknown Object Grasping for Assistive Robotics
Elle Miller, Maximilian Durner, Matthias Humt, Gabriel Quere, Wout Boerdijk, Ashok M. Sundaram, Freek Stulp, Jorn Vogel
We propose a novel pipeline for unknown object grasping in shared robotic autonomy scenarios. State-of-the-art methods for fully autonomous scenarios are typically learning-based approaches optimised for a specific end-effector, that generate grasp poses directly from sensor input. In the domain of assistive robotics, we seek instead to utilise the user's cognitive abilities for enhanced satisfaction, grasping performance, and alignment with their high level task-specific goals. Given a pair of stereo images, we perform unknown object instance segmentation and generate a 3D reconstruction of the object of interest. In shared control, the user then guides the robot end-effector across a virtual hemisphere centered around the object to their desired approach direction. A physics-based grasp planner finds the most stable local grasp on the reconstruction, and finally the user is guided by shared control to this grasp. In experiments on the DLR EDAN platform, we report a grasp success rate of 87% for 10 unknown objects, and demonstrate the method's capability to grasp objects in structured clutter and from shelves.
Read more5/7/2024
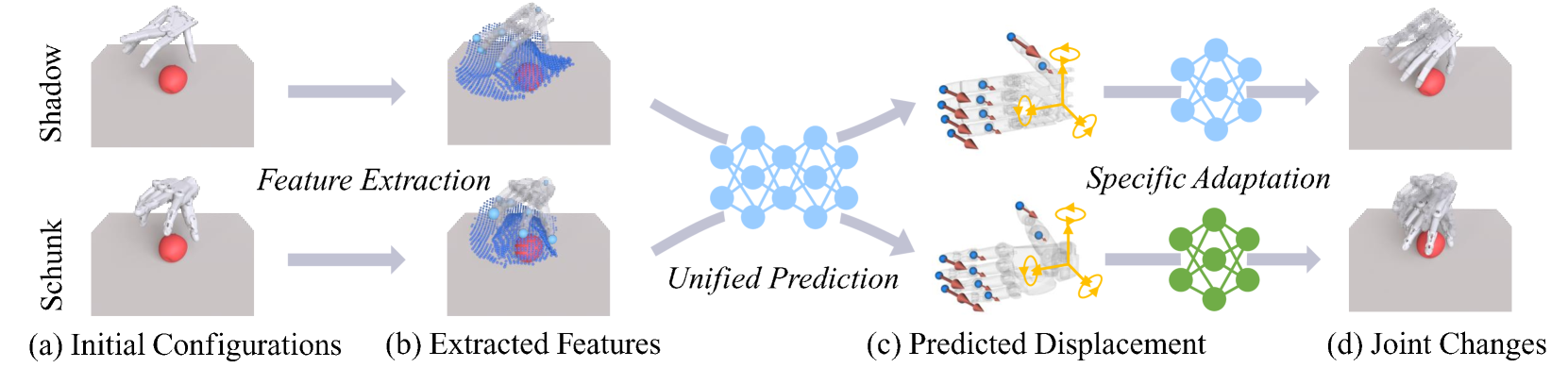
0
Learning Cross-hand Policies for High-DOF Reaching and Grasping
Qijin She, Shishun Zhang, Yunfan Ye, Ruizhen Hu, Kai Xu
Reaching-and-grasping is a fundamental skill for robotic manipulation, but existing methods usually train models on a specific gripper and cannot be reused on another gripper. In this paper, we propose a novel method that can learn a unified policy model that can be easily transferred to different dexterous grippers. Our method consists of two stages: a gripper-agnostic policy model that predicts the displacements of pre-defined key points on the gripper, and a gripper-specific adaptation model that translates these displacements into adjustments for controlling the grippers' joints. The gripper state and interactions with objects are captured at the finger level using robust geometric representations, integrated with a transformer-based network to address variations in gripper morphology and geometry. In the experiments, we evaluate our method on several dexterous grippers and diverse objects, and the result shows that our method significantly outperforms the baseline methods. Pioneering the transfer of grasp policies across dexterous grippers, our method effectively demonstrates its potential for learning generalizable and transferable manipulation skills for various robotic hands.
Read more7/16/2024