GraspSAM: When Segment Anything Model Meets Grasp Detection

0

Sign in to get full access
Overview
- GraspSAM aims to combine the Segment Anything Model (SAM) with grasp detection for improved object grasping capabilities
- This paper proposes a novel approach to leverage SAM's segmentation abilities for grasp detection
- Experiments show the proposed GraspSAM model outperforms existing grasp detection methods
Plain English Explanation
The Segment Anything Model (SAM) is a powerful AI system that can segment and identify objects in images with high accuracy. In this paper, the researchers wanted to see if they could use SAM's segmentation abilities to also improve the task of grasp detection - determining where and how an robotic gripper should grab an object.
The key idea is to combine SAM's segmentation with traditional grasp detection methods. First, SAM is used to identify the objects in an image. Then, the grasp detection model focuses in on the segmented objects to determine the best grasping points. This allows the system to better understand the shape and orientation of the objects, leading to more accurate grasp predictions.
The researchers evaluated their GraspSAM approach on standard grasp detection benchmarks and found that it outperformed existing methods. This suggests that leveraging powerful segmentation models like SAM can be a promising direction for improving robotic grasping capabilities.
Technical Explanation
The paper proposes a novel "GraspSAM" model that integrates the Segment Anything Model (SAM) with a grasp detection network.
First, the SAM model is used to segment the objects in an input image. Then, the grasp detection network focuses only on the segmented regions, using the object boundaries to better understand the shape and orientation of the objects. This allows the network to make more accurate predictions about where and how the gripper should grasp each object.
The researchers evaluate their GraspSAM approach on standard grasp detection benchmarks like Cornell Grasp Dataset and Jacquard Dataset. They show that GraspSAM outperforms existing state-of-the-art grasp detection methods, demonstrating the value of integrating SAM's segmentation capabilities.
Critical Analysis
The paper provides a strong technical contribution by successfully combining SAM's advanced segmentation with traditional grasp detection. This highlights the potential for leveraging powerful vision models like SAM to enhance downstream robotic manipulation tasks.
However, the paper does not explore the limitations or edge cases of the GraspSAM approach. For example, it's unclear how the system would perform on highly cluttered scenes or novel object types not seen during training. Additional analysis and robustness testing would help validate the broader applicability of this technique.
Furthermore, the paper focuses solely on grasp detection and does not consider the full robotic grasping pipeline, which would also involve motion planning, execution, and feedback. Integrating GraspSAM into a complete robotic system is an important next step to assess its real-world impact.
Conclusion
This paper presents an innovative approach called GraspSAM that combines the Segment Anything Model (SAM) with grasp detection. By leveraging SAM's powerful segmentation capabilities, the GraspSAM model is able to make more accurate predictions about where and how to grasp objects.
The experimental results demonstrate that GraspSAM outperforms existing state-of-the-art grasp detection methods, suggesting that integrating advanced vision models can be a promising direction for improving robotic grasping and manipulation skills. As robotic systems become more capable of understanding and interacting with the world around them, techniques like GraspSAM may play an increasingly important role in enabling more reliable and versatile robotic applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GraspSAM: When Segment Anything Model Meets Grasp Detection
Sangjun Noh, Jongwon Kim, Dongwoo Nam, Seunghyeok Back, Raeyoung Kang, Kyoobin Lee
Grasp detection requires flexibility to handle objects of various shapes without relying on prior knowledge of the object, while also offering intuitive, user-guided control. This paper introduces GraspSAM, an innovative extension of the Segment Anything Model (SAM), designed for prompt-driven and category-agnostic grasp detection. Unlike previous methods, which are often limited by small-scale training data, GraspSAM leverages the large-scale training and prompt-based segmentation capabilities of SAM to efficiently support both target-object and category-agnostic grasping. By utilizing adapters, learnable token embeddings, and a lightweight modified decoder, GraspSAM requires minimal fine-tuning to integrate object segmentation and grasp prediction into a unified framework. The model achieves state-of-the-art (SOTA) performance across multiple datasets, including Jacquard, Grasp-Anything, and Grasp-Anything++. Extensive experiments demonstrate the flexibility of GraspSAM in handling different types of prompts (such as points, boxes, and language), highlighting its robustness and effectiveness in real-world robotic applications.
Read more9/24/2024
📈
0
Segment Anything Model is a Good Teacher for Local Feature Learning
Jingqian Wu, Rongtao Xu, Zach Wood-Doughty, Changwei Wang, Shibiao Xu, Edmund Y. Lam
Local feature detection and description play an important role in many computer vision tasks, which are designed to detect and describe keypoints in any scene and any downstream task. Data-driven local feature learning methods need to rely on pixel-level correspondence for training, which is challenging to acquire at scale, thus hindering further improvements in performance. In this paper, we propose SAMFeat to introduce SAM (segment anything model), a fundamental model trained on 11 million images, as a teacher to guide local feature learning and thus inspire higher performance on limited datasets. To do so, first, we construct an auxiliary task of Attention-weighted Semantic Relation Distillation (ASRD), which distillates feature relations with category-agnostic semantic information learned by the SAM encoder into a local feature learning network, to improve local feature description using semantic discrimination. Second, we develop a technique called Weakly Supervised Contrastive Learning Based on Semantic Grouping (WSC), which utilizes semantic groupings derived from SAM as weakly supervised signals, to optimize the metric space of local descriptors. Third, we design an Edge Attention Guidance (EAG) to further improve the accuracy of local feature detection and description by prompting the network to pay more attention to the edge region guided by SAM. SAMFeat's performance on various tasks such as image matching on HPatches, and long-term visual localization on Aachen Day-Night showcases its superiority over previous local features. The release code is available at https://github.com/vignywang/SAMFeat.
Read more6/19/2024
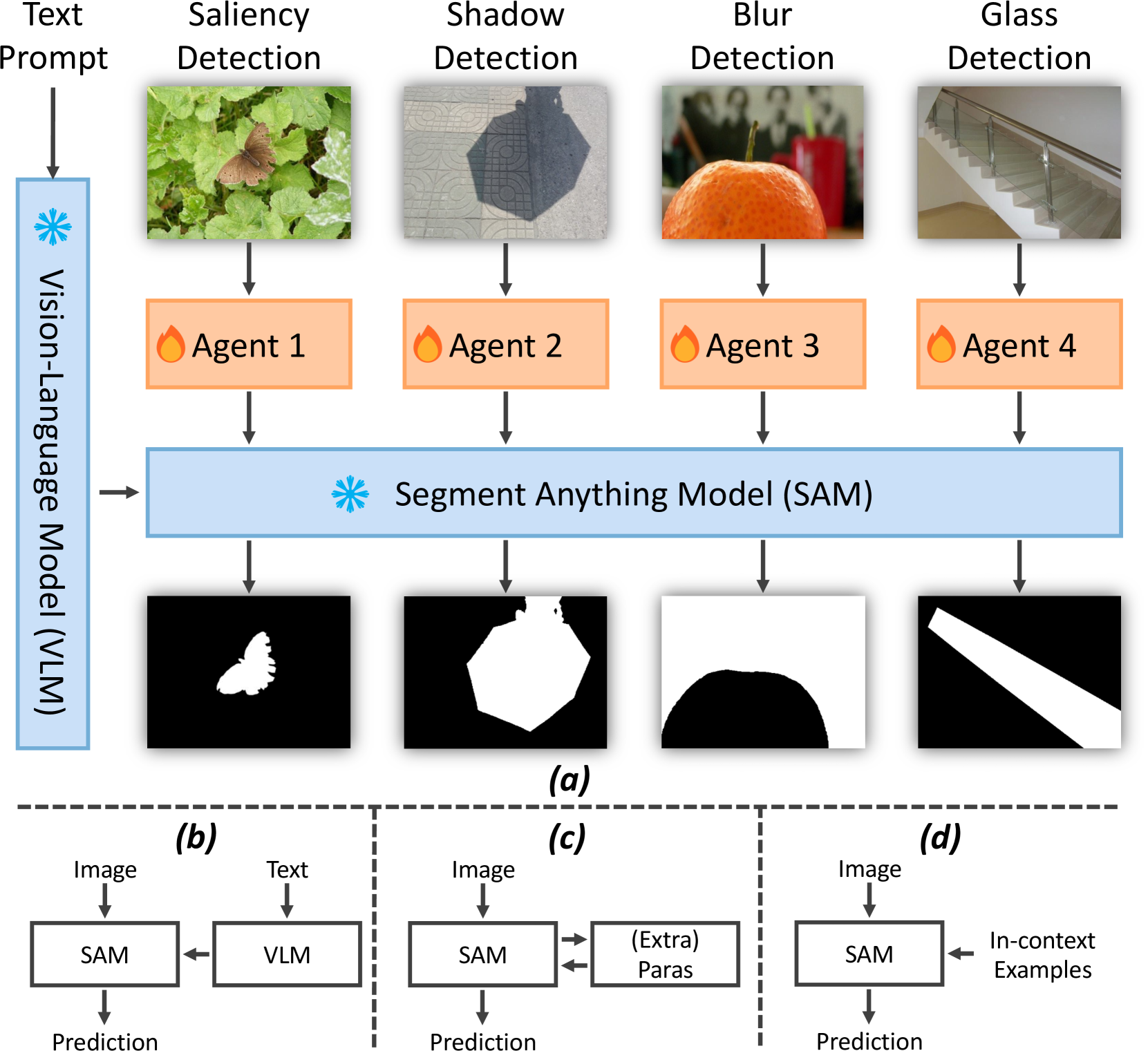
0
AlignSAM: Aligning Segment Anything Model to Open Context via Reinforcement Learning
Duojun Huang, Xinyu Xiong, Jie Ma, Jichang Li, Zequn Jie, Lin Ma, Guanbin Li
Powered by massive curated training data, Segment Anything Model (SAM) has demonstrated its impressive generalization capabilities in open-world scenarios with the guidance of prompts. However, the vanilla SAM is class agnostic and heavily relies on user-provided prompts to segment objects of interest. Adapting this method to diverse tasks is crucial for accurate target identification and to avoid suboptimal segmentation results. In this paper, we propose a novel framework, termed AlignSAM, designed for automatic prompting for aligning SAM to an open context through reinforcement learning. Anchored by an agent, AlignSAM enables the generality of the SAM model across diverse downstream tasks while keeping its parameters frozen. Specifically, AlignSAM initiates a prompting agent to iteratively refine segmentation predictions by interacting with the foundational model. It integrates a reinforcement learning policy network to provide informative prompts to the foundational models. Additionally, a semantic recalibration module is introduced to provide fine-grained labels of prompts, enhancing the model's proficiency in handling tasks encompassing explicit and implicit semantics. Experiments conducted on various challenging segmentation tasks among existing foundation models demonstrate the superiority of the proposed AlignSAM over state-of-the-art approaches. Project page: url{https://github.com/Duojun-Huang/AlignSAM-CVPR2024}.
Read more6/4/2024
📈
0
SU-SAM: A Simple Unified Framework for Adapting Segment Anything Model in Underperformed Scenes
Yiran Song, Qianyu Zhou, Xuequan Lu, Zhiwen Shao, Lizhuang Ma
Segment anything model (SAM) has demonstrated excellent generalizability in common vision scenarios, yet falling short of the ability to understand specialized data. Recently, several methods have combined parameter-efficient techniques with task-specific designs to fine-tune SAM on particular tasks. However, these methods heavily rely on handcraft, complicated, and task-specific designs, and pre/post-processing to achieve acceptable performances on downstream tasks. As a result, this severely restricts generalizability to other downstream tasks. To address this issue, we present a simple and unified framework, namely SU-SAM, that can easily and efficiently fine-tune the SAM model with parameter-efficient techniques while maintaining excellent generalizability toward various downstream tasks. SU-SAM does not require any task-specific designs and aims to improve the adaptability of SAM-like models significantly toward underperformed scenes. Concretely, we abstract parameter-efficient modules of different methods into basic design elements in our framework. Besides, we propose four variants of SU-SAM, i.e., series, parallel, mixed, and LoRA structures. Comprehensive experiments on nine datasets and six downstream tasks to verify the effectiveness of SU-SAM, including medical image segmentation, camouflage object detection, salient object segmentation, surface defect segmentation, complex object shapes, and shadow masking. Our experimental results demonstrate that SU-SAM achieves competitive or superior accuracy compared to state-of-the-art methods. Furthermore, we provide in-depth analyses highlighting the effectiveness of different parameter-efficient designs within SU-SAM. In addition, we propose a generalized model and benchmark, showcasing SU-SAM's generalizability across all diverse datasets simultaneously.
Read more7/30/2024