SU-SAM: A Simple Unified Framework for Adapting Segment Anything Model in Underperformed Scenes

0
📈
Sign in to get full access
Overview
- The Segment Anything Model (SAM) has demonstrated excellent performance in common vision scenarios, but struggles with specialized data.
- Recent methods have combined parameter-efficient techniques with task-specific designs to fine-tune SAM, but these rely heavily on complicated, task-specific approaches that limit generalizability.
- To address this issue, the researchers present a simple and unified framework called SU-SAM that can efficiently fine-tune SAM while maintaining excellent generalizability across various downstream tasks.
Plain English Explanation
The Segment Anything Model (SAM) is a powerful computer vision model that can segment objects in images. However, it has struggled to perform well on specialized or unusual types of data, such as medical images or images with camouflaged objects.
To improve SAM's performance on these more specialized tasks, researchers have tried combining it with other techniques that are tailored to the specific task. For example, they might add extra processing steps or custom-designed components to help SAM understand the unique characteristics of the data.
While these approaches can boost SAM's performance on the targeted task, they come with a major downside - they make the model much more complex and less flexible. The custom components and processing steps are closely tied to the specific task, so the model has a hard time generalizing to other types of data or tasks.
To address this issue, the researchers developed a new framework called SU-SAM. SU-SAM provides a simple and unified way to fine-tune SAM using parameter-efficient techniques that don't require any task-specific designs. This allows SU-SAM to maintain SAM's excellent generalizability while still improving its performance on a wide range of specialized tasks, including medical image segmentation, object detection, and more.
The key innovation of SU-SAM is that it abstracts the various parameter-efficient techniques into a set of basic building blocks. This makes it easy to experiment with different combinations of these building blocks to find the best approach for a given task, without having to start from scratch each time.
Technical Explanation
The researchers present a simple and unified framework called SU-SAM that can efficiently fine-tune the Segment Anything Model (SAM) while maintaining excellent generalizability across various downstream tasks.
SU-SAM abstracts the parameter-efficient modules used in different fine-tuning methods into basic design elements. This allows the researchers to explore various combinations of these building blocks, including series, parallel, mixed, and LoRA structures, to find the most effective approach for a given task.
The researchers conduct comprehensive experiments on nine datasets and six downstream tasks, including medical image segmentation, camouflage object detection, salient object segmentation, surface defect segmentation, complex object shapes, and shadow masking. They demonstrate that SU-SAM achieves competitive or superior accuracy compared to state-of-the-art methods.
Furthermore, the researchers provide in-depth analyses highlighting the effectiveness of the different parameter-efficient designs within SU-SAM. They also propose a generalized model and benchmark, showcasing SU-SAM's strong generalizability across all the diverse datasets simultaneously.
Critical Analysis
The researchers have done a commendable job in addressing the limitations of existing fine-tuning methods for the Segment Anything Model (SAM). By developing a simple and unified framework in SU-SAM, they have successfully maintained SAM's excellent generalizability while improving its performance on a wide range of specialized tasks.
One potential area for further research could be exploring the integration of SU-SAM with other advanced techniques, such as unsupervised semantic segmentation or adversarial tuning, to further enhance its capabilities and robustness across an even broader range of scenarios.
Additionally, the researchers could investigate the tradeoffs between the different parameter-efficient structures within SU-SAM, such as the impact on inference speed, memory footprint, and training efficiency. This could help users make more informed choices when deploying SU-SAM in their specific applications.
Conclusion
The researchers have presented a simple and unified framework called SU-SAM that can efficiently fine-tune the Segment Anything Model (SAM) while maintaining its excellent generalizability across various downstream tasks. By abstracting parameter-efficient techniques into basic design elements, SU-SAM provides a flexible and adaptable approach to improving SAM's performance on specialized data without sacrificing its core strengths.
The comprehensive experimental results demonstrate the effectiveness of SU-SAM, showcasing its ability to achieve competitive or superior accuracy compared to state-of-the-art methods across a diverse range of tasks and datasets. This work represents an important step forward in enhancing the versatility and applicability of powerful vision models like SAM, paving the way for their wider adoption in real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
SU-SAM: A Simple Unified Framework for Adapting Segment Anything Model in Underperformed Scenes
Yiran Song, Qianyu Zhou, Xuequan Lu, Zhiwen Shao, Lizhuang Ma
Segment anything model (SAM) has demonstrated excellent generalizability in common vision scenarios, yet falling short of the ability to understand specialized data. Recently, several methods have combined parameter-efficient techniques with task-specific designs to fine-tune SAM on particular tasks. However, these methods heavily rely on handcraft, complicated, and task-specific designs, and pre/post-processing to achieve acceptable performances on downstream tasks. As a result, this severely restricts generalizability to other downstream tasks. To address this issue, we present a simple and unified framework, namely SU-SAM, that can easily and efficiently fine-tune the SAM model with parameter-efficient techniques while maintaining excellent generalizability toward various downstream tasks. SU-SAM does not require any task-specific designs and aims to improve the adaptability of SAM-like models significantly toward underperformed scenes. Concretely, we abstract parameter-efficient modules of different methods into basic design elements in our framework. Besides, we propose four variants of SU-SAM, i.e., series, parallel, mixed, and LoRA structures. Comprehensive experiments on nine datasets and six downstream tasks to verify the effectiveness of SU-SAM, including medical image segmentation, camouflage object detection, salient object segmentation, surface defect segmentation, complex object shapes, and shadow masking. Our experimental results demonstrate that SU-SAM achieves competitive or superior accuracy compared to state-of-the-art methods. Furthermore, we provide in-depth analyses highlighting the effectiveness of different parameter-efficient designs within SU-SAM. In addition, we propose a generalized model and benchmark, showcasing SU-SAM's generalizability across all diverse datasets simultaneously.
Read more7/30/2024
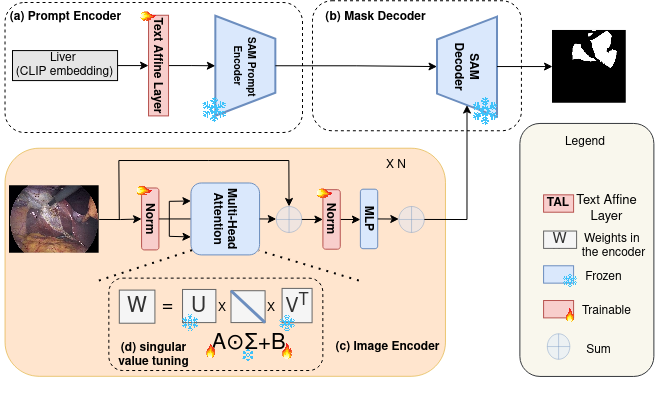
0
S-SAM: SVD-based Fine-Tuning of Segment Anything Model for Medical Image Segmentation
Jay N. Paranjape, Shameema Sikder, S. Swaroop Vedula, Vishal M. Patel
Medical image segmentation has been traditionally approached by training or fine-tuning the entire model to cater to any new modality or dataset. However, this approach often requires tuning a large number of parameters during training. With the introduction of the Segment Anything Model (SAM) for prompted segmentation of natural images, many efforts have been made towards adapting it efficiently for medical imaging, thus reducing the training time and resources. However, these methods still require expert annotations for every image in the form of point prompts or bounding box prompts during training and inference, making it tedious to employ them in practice. In this paper, we propose an adaptation technique, called S-SAM, that only trains parameters equal to 0.4% of SAM's parameters and at the same time uses simply the label names as prompts for producing precise masks. This not only makes tuning SAM more efficient than the existing adaptation methods but also removes the burden of providing expert prompts. We call this modified version S-SAM and evaluate it on five different modalities including endoscopic images, x-ray, ultrasound, CT, and histology images. Our experiments show that S-SAM outperforms state-of-the-art methods as well as existing SAM adaptation methods while tuning a significantly less number of parameters. We release the code for S-SAM at https://github.com/JayParanjape/SVDSAM.
Read more8/14/2024

0
SAM2-Adapter: Evaluating & Adapting Segment Anything 2 in Downstream Tasks: Camouflage, Shadow, Medical Image Segmentation, and More
Tianrun Chen, Ankang Lu, Lanyun Zhu, Chaotao Ding, Chunan Yu, Deyi Ji, Zejian Li, Lingyun Sun, Papa Mao, Ying Zang
The advent of large models, also known as foundation models, has significantly transformed the AI research landscape, with models like Segment Anything (SAM) achieving notable success in diverse image segmentation scenarios. Despite its advancements, SAM encountered limitations in handling some complex low-level segmentation tasks like camouflaged object and medical imaging. In response, in 2023, we introduced SAM-Adapter, which demonstrated improved performance on these challenging tasks. Now, with the release of Segment Anything 2 (SAM2), a successor with enhanced architecture and a larger training corpus, we reassess these challenges. This paper introduces SAM2-Adapter, the first adapter designed to overcome the persistent limitations observed in SAM2 and achieve new state-of-the-art (SOTA) results in specific downstream tasks including medical image segmentation, camouflaged (concealed) object detection, and shadow detection. SAM2-Adapter builds on the SAM-Adapter's strengths, offering enhanced generalizability and composability for diverse applications. We present extensive experimental results demonstrating SAM2-Adapter's effectiveness. We show the potential and encourage the research community to leverage the SAM2 model with our SAM2-Adapter for achieving superior segmentation outcomes. Code, pre-trained models, and data processing protocols are available at http://tianrun-chen.github.io/SAM-Adaptor/
Read more8/13/2024
📈
0
nnSAM: Plug-and-play Segment Anything Model Improves nnUNet Performance
Yunxiang Li, Bowen Jing, Zihan Li, Jing Wang, You Zhang
Automatic segmentation of medical images is crucial in modern clinical workflows. The Segment Anything Model (SAM) has emerged as a versatile tool for image segmentation without specific domain training, but it requires human prompts and may have limitations in specific domains. Traditional models like nnUNet perform automatic segmentation during inference and are effective in specific domains but need extensive domain-specific training. To combine the strengths of foundational and domain-specific models, we propose nnSAM, integrating SAM's robust feature extraction with nnUNet's automatic configuration to enhance segmentation accuracy on small datasets. Our nnSAM model optimizes two main approaches: leveraging SAM's feature extraction and nnUNet's domain-specific adaptation, and incorporating a boundary shape supervision loss function based on level set functions and curvature calculations to learn anatomical shape priors from limited data. We evaluated nnSAM on four segmentation tasks: brain white matter, liver, lung, and heart segmentation. Our method outperformed others, achieving the highest DICE score of 82.77% and the lowest ASD of 1.14 mm in brain white matter segmentation with 20 training samples, compared to nnUNet's DICE score of 79.25% and ASD of 1.36 mm. A sample size study highlighted nnSAM's advantage with fewer training samples. Our results demonstrate significant improvements in segmentation performance with nnSAM, showcasing its potential for small-sample learning in medical image segmentation.
Read more5/16/2024