GRLinQ: An Intelligent Spectrum Sharing Mechanism for Device-to-Device Communications with Graph Reinforcement Learning

0

Sign in to get full access
Overview
- This paper presents GRLinQ, an intelligent spectrum sharing mechanism for device-to-device (D2D) communications using graph reinforcement learning.
- The goal is to efficiently allocate spectrum resources and manage interference in D2D networks.
- GRLinQ uses a graph neural network to model the network topology and a reinforcement learning agent to make adaptive spectrum sharing decisions.
Plain English Explanation
In modern wireless networks, devices often need to communicate directly with each other in a device-to-device (D2D) fashion, rather than always going through a central base station. This allows for more efficient use of spectrum resources and can improve performance. However, managing the interference between these D2D links can be challenging.
The researchers developed a system called GRLinQ that uses [object Object] to intelligently allocate spectrum resources and control interference in D2D networks. The key idea is to model the network as a graph, where each device is a node and the connections between them represent potential interference. A reinforcement learning agent then learns how to make good spectrum sharing decisions by interacting with this graph-based representation of the network.
By using this graph-based approach, GRLinQ can capture the complex relationships and interdependencies between different D2D links, allowing it to make more informed and adaptive spectrum allocation choices. This helps improve the overall efficiency and performance of the D2D network.
Technical Explanation
The researchers formulate the spectrum sharing problem in D2D networks as a Markov decision process, where the goal is to maximize the sum rate of all D2D links while controlling interference. They propose the GRLinQ framework to solve this problem:
-
Graph Neural Network (GNN) Model: GRLinQ models the D2D network as a graph, where each device is a node and the potential interference between devices is represented by edges. A GNN is used to learn a representation of this graph, capturing the complex relationships between devices.
-
Reinforcement Learning (RL) Agent: GRLinQ uses a reinforcement learning agent to make spectrum sharing decisions. The agent observes the state of the network (represented by the GNN) and learns to take actions (spectrum allocation decisions) that maximize the overall sum rate.
-
Spectrum Sharing Algorithm: The RL agent uses a [object Object] to learn the optimal spectrum sharing policy. The agent takes the current state of the network (from the GNN) as input and outputs the spectrum allocation decisions for each D2D link.
The researchers evaluate GRLinQ through simulations and compare it to other spectrum sharing approaches. The results show that GRLinQ can achieve significantly higher sum rates and better interference control compared to traditional methods, demonstrating the effectiveness of the graph-based reinforcement learning approach.
Critical Analysis
The paper presents a novel and promising approach to spectrum sharing in D2D networks using graph reinforcement learning. The key strengths of the GRLinQ framework are:
-
Capturing Network Dynamics: By modeling the D2D network as a graph, GRLinQ can effectively capture the complex relationships and interdependencies between different devices and links, which is crucial for making informed spectrum allocation decisions.
-
Adaptive and Intelligent Spectrum Sharing: The reinforcement learning agent in GRLinQ learns to make adaptive spectrum sharing decisions, adjusting to changes in the network conditions and interference patterns over time.
-
Improved Performance: The simulation results show that GRLinQ can achieve significant improvements in terms of sum rate and interference control compared to traditional spectrum sharing methods.
However, the paper also has a few limitations that could be addressed in future research:
-
Real-world Validation: The evaluation of GRLinQ is based on simulations, and it would be important to validate the approach in real-world D2D network deployments to understand its practical performance and feasibility.
-
Scalability and Computational Complexity: As the size of the D2D network grows, the computational complexity of the GNN and reinforcement learning components may increase, potentially affecting the scalability of the GRLinQ framework. Techniques to improve the scalability could be explored.
-
Fairness and User Experience: The current objective function of GRLinQ focuses on maximizing the sum rate, which may not directly translate to a good user experience or fair resource allocation. Incorporating fairness and user experience metrics into the optimization problem could be a valuable extension.
Overall, the GRLinQ framework presented in this paper is a promising approach to intelligent spectrum sharing in D2D networks, and the authors have demonstrated its potential through simulations. Further research and real-world validation could help address the identified limitations and unlock the full potential of this graph reinforcement learning-based solution.
Conclusion
This paper introduces GRLinQ, an intelligent spectrum sharing mechanism for device-to-device (D2D) communications that leverages graph reinforcement learning. By modeling the D2D network as a graph and using a reinforcement learning agent to make adaptive spectrum allocation decisions, GRLinQ can effectively manage interference and improve the overall performance of the network.
The key contributions of this work include the graph-based network representation, the reinforcement learning-based spectrum sharing algorithm, and the demonstration of significant performance improvements over traditional approaches through simulations. While further research and real-world validation are needed, the GRLinQ framework represents an exciting step forward in the field of intelligent spectrum management for next-generation wireless networks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GRLinQ: An Intelligent Spectrum Sharing Mechanism for Device-to-Device Communications with Graph Reinforcement Learning
Zhiwei Shan, Xinping Yi, Le Liang, Chung-Shou Liao, Shi Jin
Device-to-device (D2D) spectrum sharing in wireless communications is a challenging non-convex combinatorial optimization problem, involving entangled link scheduling and power control in a large-scale network. The state-of-the-art methods, either from a model-based or a data-driven perspective, exhibit certain limitations such as the critical need for channel state information (CSI) and/or a large number of (solved) instances (e.g., network layouts) as training samples. To advance this line of research, we propose a novel hybrid model/datadriven spectrum sharing mechanism with graph reinforcement learning for link scheduling (GRLinQ), injecting information theoretical insights into machine learning models, in such a way that link scheduling and power control can be solved in an intelligent yet explainable manner. Through an extensive set of experiments, GRLinQ demonstrates superior performance to the existing model-based and data-driven link scheduling and/or power control methods, with a relaxed requirement for CSI, a substantially reduced number of unsolved instances as training samples, a possible distributed deployment, reduced online/offline computational complexity, and more remarkably excellent scalability and generalizability over different network scenarios and system configurations.
Read more8/20/2024
🤿
0
Deep Reinforcement Learning for Wireless Scheduling in Distributed Networked Control
Gaoyang Pang, Kang Huang, Daniel E. Quevedo, Branka Vucetic, Yonghui Li, Wanchun Liu
We consider a joint uplink and downlink scheduling problem of a fully distributed wireless networked control system (WNCS) with a limited number of frequency channels. Using elements of stochastic systems theory, we derive a sufficient stability condition of the WNCS, which is stated in terms of both the control and communication system parameters. Once the condition is satisfied, there exists a stationary and deterministic scheduling policy that can stabilize all plants of the WNCS. By analyzing and representing the per-step cost function of the WNCS in terms of a finite-length countable vector state, we formulate the optimal transmission scheduling problem into a Markov decision process and develop a deep reinforcement learning (DRL) based framework for solving it. To tackle the challenges of a large action space in DRL, we propose novel action space reduction and action embedding methods for the DRL framework that can be applied to various algorithms, including Deep Q-Network (DQN), Deep Deterministic Policy Gradient (DDPG), and Twin Delayed Deep Deterministic Policy Gradient (TD3). Numerical results show that the proposed algorithm significantly outperforms benchmark policies.
Read more7/29/2024
0
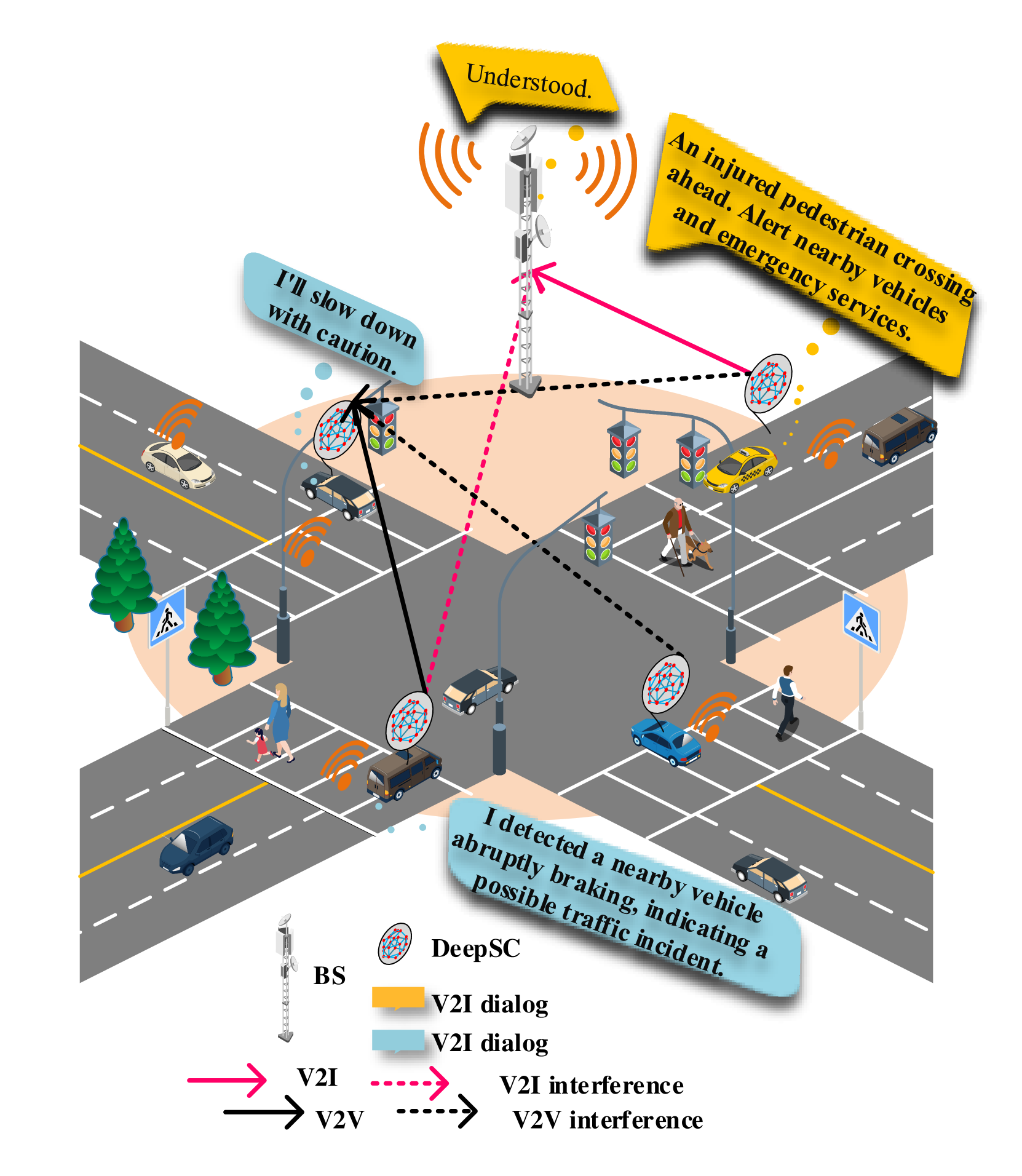
Semantic-Aware Spectrum Sharing in Internet of Vehicles Based on Deep Reinforcement Learning
Zhiyu Shao, Qiong Wu, Pingyi Fan, Nan Cheng, Wen Chen, Jiangzhou Wang, Khaled B. Letaief
This work aims to investigate semantic communication in high-speed mobile Internet of vehicles (IoV) environments, with a focus on the spectrum sharing between vehicle-to-vehicle (V2V) and vehicle-to-infrastructure (V2I) communications. We specifically address spectrum scarcity and network traffic and then propose a semantic-aware spectrum sharing algorithm (SSS) based on the deep reinforcement learning (DRL) soft actor-critic (SAC) approach. Firstly, we delve into the extraction of semantic information. Secondly, we redefine metrics for semantic information in V2V and V2I spectrum sharing in IoV environments, introducing high-speed semantic spectrum efficiency (HSSE) and semantic transmission rate (HSR). Finally, we employ the SAC algorithm for decision optimization in V2V and V2I spectrum sharing based on semantic information. This optimization encompasses the optimal link of V2V and V2I sharing strategies, the transmission power for vehicles sending semantic information and the length of transmitted semantic symbols, aiming at maximizing HSSE of V2I and enhancing success rate of effective semantic information transmission (SRS) of V2V. Experimental results demonstrate that the SSS algorithm outperforms other baseline algorithms, including other traditional-communication-based spectrum sharing algorithms and spectrum sharing algorithm using other reinforcement learning approaches. The SSS algorithm exhibits a 15% increase in HSSE and approximately a 7% increase in SRS.
Read more6/18/2024
0
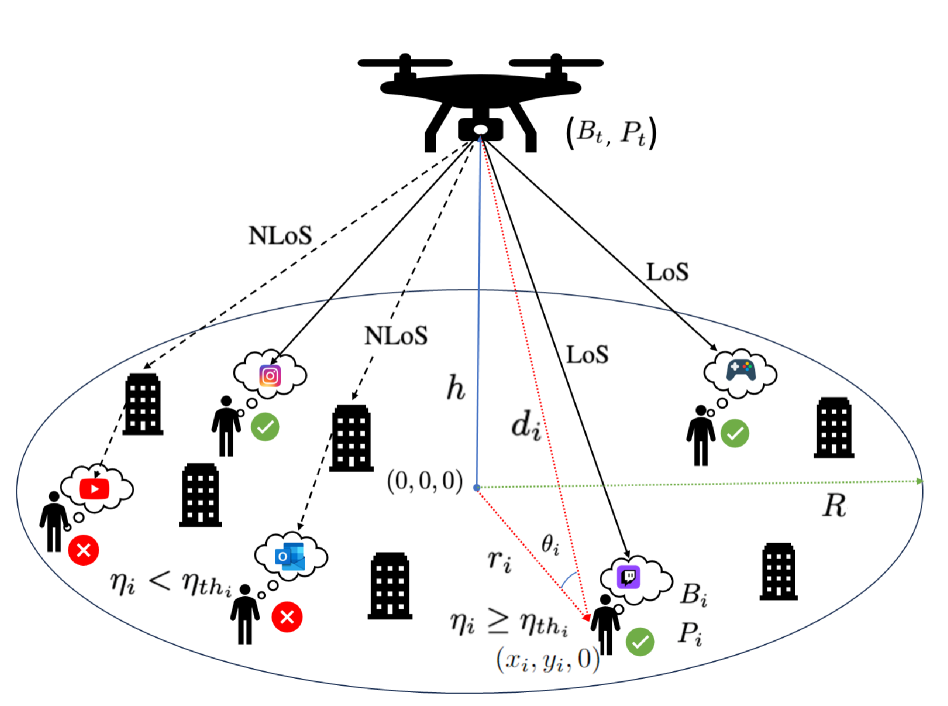
A Novel Joint DRL-Based Utility Optimization for UAV Data Services
Xuli Cai, Poonam Lohan, Burak Kantarci
In this paper, we propose a novel joint deep reinforcement learning (DRL)-based solution to optimize the utility of an uncrewed aerial vehicle (UAV)-assisted communication network. To maximize the number of users served within the constraints of the UAV's limited bandwidth and power resources, we employ deep Q-Networks (DQN) and deep deterministic policy gradient (DDPG) algorithms for optimal resource allocation to ground users with heterogeneous data rate demands. The DQN algorithm dynamically allocates multiple bandwidth resource blocks to different users based on current demand and available resource states. Simultaneously, the DDPG algorithm manages power allocation, continuously adjusting power levels to adapt to varying distances and fading conditions, including Rayleigh fading for non-line-of-sight (NLoS) links and Rician fading for line-of-sight (LoS) links. Our joint DRL-based solution demonstrates an increase of up to 41% in the number of users served compared to scenarios with equal bandwidth and power allocation.
Read more6/18/2024