Ground-based Image Deconvolution with Swin Transformer UNet

0
🖼️
Sign in to get full access
Overview
- Ground-based astronomical surveys will soon collect millions of images
- There is a need for fast deconvolution algorithms to improve the spatial resolution of these images
- Accurate photometric measurements from high-resolution images can help deepen our understanding of galaxy formation and evolution
- The paper introduces a two-step deconvolution framework using a Swin Transformer architecture
- The deep learning-based solution introduces a bias, so a novel third step using sparsity wavelet framework is proposed to address this limitation
- The method is compared to a classical deconvolution algorithm, demonstrating advantages in resolution recovery, generalization to noise, and computational efficiency
- Analyzing a cluster sample enables quantifying the number of clumps in galaxies related to their disc color
- This robust technique holds promise for identifying structures in distant galaxies from ground-based images
Plain English Explanation
Astronomers are about to collect a huge number of images from ground-based telescopes. To make the most of this data, they need ways to improve the quality and resolution of the images. By recovering cleaner, higher-resolution versions of these images, researchers can make more accurate measurements of galaxies and better understand how they form and evolve over time.
The paper introduces a new two-step process that uses a type of deep learning model called a Swin Transformer to deconvolve the images and improve their resolution. However, the researchers found that this deep learning approach introduced some bias, limiting its usefulness for scientific analysis.
To address this, the team added a third step to their process that relies on a mathematical technique called the sparsity wavelet framework. This helps remove the bias introduced by the deep learning model.
The researchers compared their new three-step method to a classical deconvolution algorithm called Firedec. They found that their approach had advantages in terms of recovering higher resolutions, handling different types of noise in the images, and being computationally efficient.
To test the method, the researchers analyzed a sample of galaxy cluster data. This allowed them to quantify the number of clumps or structures within the galaxies and relate that to the color of the galaxy discs. The researchers believe this robust deconvolution technique could be very useful for studying the detailed structure of distant galaxies observed from ground-based telescopes.
Technical Explanation
The paper introduces a two-step deconvolution framework using a Swin Transformer architecture to efficiently improve the spatial resolution of ground-based astronomical survey images. The first step employs a deep learning-based approach to deconvolve the input images. However, the researchers found that this deep learning solution introduces a bias, which constrains the scope of scientific analysis.
To address this limitation, the authors propose a novel third step that relies on the active coefficients in the sparsity wavelet framework. This additional step helps remove the bias introduced by the deep learning model.
The team conducts a performance comparison between their deep learning-based method and Firedec, a classical deconvolution algorithm. They analyze a subset of the EDisCS cluster samples and demonstrate the advantages of their method in terms of resolution recovery, generalization to different noise properties, and computational efficiency.
Analyzing this cluster sample not only assesses the efficiency of the proposed method, but also enables the researchers to quantify the number of clumps within the galaxies in relation to their disc color. This insight into the detailed structure of distant galaxies is a valuable contribution to the field of galaxy formation and evolution.
Critical Analysis
The paper presents a promising approach for improving the spatial resolution of ground-based astronomical survey images, which is a critical requirement as these surveys collect ever-increasing amounts of data. The authors' decision to incorporate a third step using the sparsity wavelet framework to address the bias introduced by the deep learning model is a thoughtful solution to a key limitation.
However, the paper does not provide much detail on the specific architecture of the Swin Transformer used in the first step, nor does it discuss the training process and hyperparameters. Additionally, the comparison to the Firedec algorithm, while helpful, could be strengthened by including more quantitative metrics and a larger set of test cases.
It would also be interesting to see how the method performs on a wider range of astronomical data, beyond just the EDisCS cluster sample, to better understand its generalizability. Further exploration of the relationship between galaxy disc color and clump structure could yield additional insights into galaxy formation and evolution.
Overall, the paper presents a valuable contribution to the field of astronomical image deconvolution, but there are opportunities to expand the technical details, analysis, and broader applicability of the proposed approach.
Conclusion
This paper introduces a novel three-step deconvolution framework that leverages deep learning and sparsity wavelet techniques to efficiently improve the spatial resolution of ground-based astronomical survey images. By successfully recovering high-resolution images, the researchers aim to deepen our understanding of galaxy formation and evolution through accurate photometric measurements.
The key innovation is the addition of a third step using the sparsity wavelet framework to address the bias introduced by the deep learning-based solution in the initial two-step process. This novel approach demonstrates advantages in resolution recovery, generalization to different noise properties, and computational efficiency compared to a classical deconvolution algorithm.
Analyzing a sample of galaxy cluster data enables the researchers to quantify the number of clumps within the galaxies and relate this to their disc color. This robust deconvolution technique holds promise for identifying detailed structures in distant galaxies observed from ground-based telescopes, which could lead to important advancements in our understanding of the universe.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Ground-based Image Deconvolution with Swin Transformer UNet
Utsav Akhaury, Pascale Jablonka, Jean-Luc Starck, Fr'ed'eric Courbin
As ground-based all-sky astronomical surveys will gather millions of images in the coming years, a critical requirement emerges for the development of fast deconvolution algorithms capable of efficiently improving the spatial resolution of these images. By successfully recovering clean and high-resolution images from these surveys, the objective is to deepen the understanding of galaxy formation and evolution through accurate photometric measurements. We introduce a two-step deconvolution framework using a Swin Transformer architecture. Our study reveals that the deep learning-based solution introduces a bias, constraining the scope of scientific analysis. To address this limitation, we propose a novel third step relying on the active coefficients in the sparsity wavelet framework. We conducted a performance comparison between our deep learning-based method and Firedec, a classical deconvolution algorithm, based on an analysis of a subset of the EDisCS cluster samples. We demonstrate the advantage of our method in terms of resolution recovery, generalisation to different noise properties, and computational efficiency. The analysis of this cluster sample not only allowed us to assess the efficiency of our method, but it also enabled us to quantify the number of clumps within these galaxies in relation to their disc colour. This robust technique that we propose holds promise for identifying structures in the distant universe through ground-based images.
Read more6/5/2024

0
Solar multi-object multi-frame blind deconvolution with a spatially variant convolution neural emulator
A. Asensio Ramos (IAC+ULL)
The study of astronomical phenomena through ground-based observations is always challenged by the distorting effects of Earth's atmosphere. Traditional methods of post-facto image correction, essential for correcting these distortions, often rely on simplifying assumptions that limit their effectiveness, particularly in the presence of spatially variant atmospheric turbulence. Such cases are often solved by partitioning the field-of-view into small patches, deconvolving each patch independently, and merging all patches together. This approach is often inefficient and can produce artifacts. Recent advancements in computational techniques and the advent of deep learning offer new pathways to address these limitations. This paper introduces a novel framework leveraging a deep neural network to emulate spatially variant convolutions, offering a breakthrough in the efficiency and accuracy of astronomical image deconvolution. By training on a dataset of images convolved with spatially invariant point spread functions and validating its generalizability to spatially variant conditions, this approach presents a significant advancement over traditional methods. The convolution emulator is used as a forward model in a multi-object multi-frame blind deconvolution algorithm for solar images. The emulator enables the deconvolution of solar observations across large fields of view without resorting to patch-wise mosaicking, thus avoiding artifacts associated with such techniques. This method represents a significant computational advantage, reducing processing times by orders of magnitude.
Read more5/17/2024
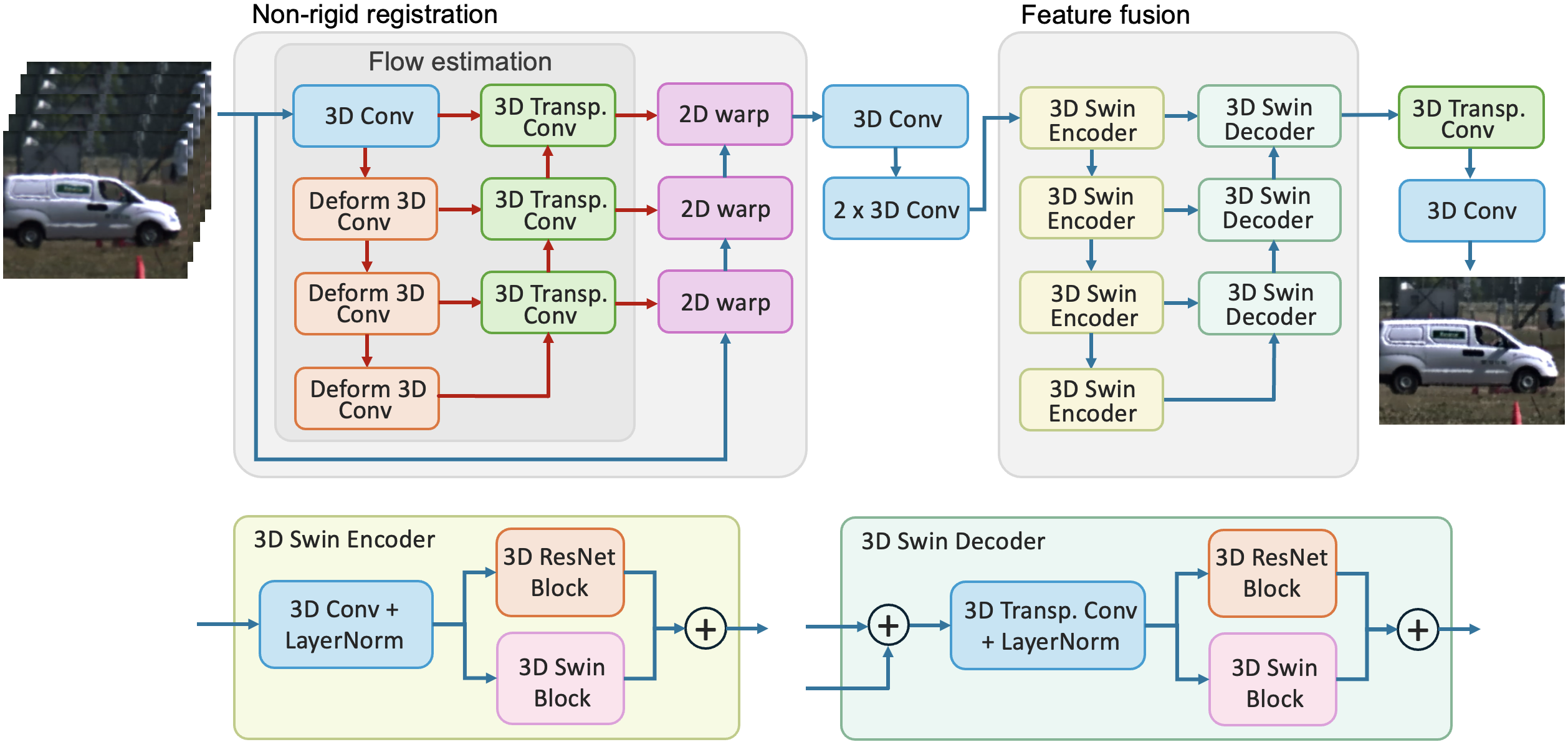
0
DeTurb: Atmospheric Turbulence Mitigation with Deformable 3D Convolutions and 3D Swin Transformers
Zhicheng Zou, Nantheera Anantrasirichai
Atmospheric turbulence in long-range imaging significantly degrades the quality and fidelity of captured scenes due to random variations in both spatial and temporal dimensions. These distortions present a formidable challenge across various applications, from surveillance to astronomy, necessitating robust mitigation strategies. While model-based approaches achieve good results, they are very slow. Deep learning approaches show promise in image and video restoration but have struggled to address these spatiotemporal variant distortions effectively. This paper proposes a new framework that combines geometric restoration with an enhancement module. Random perturbations and geometric distortion are removed using a pyramid architecture with deformable 3D convolutions, resulting in aligned frames. These frames are then used to reconstruct a sharp, clear image via a multi-scale architecture of 3D Swin Transformers. The proposed framework demonstrates superior performance over the state of the art for both synthetic and real atmospheric turbulence effects, with reasonable speed and model size.
Read more7/31/2024

0
DarSwin-Unet: Distortion Aware Encoder-Decoder Architecture
Akshaya Athwale, Ichrak Shili, 'Emile Bergeron, Ola Ahmad, Jean-Franc{c}ois Lalonde
Wide-angle fisheye images are becoming increasingly common for perception tasks in applications such as robotics, security, and mobility (e.g. drones, avionics). However, current models often either ignore the distortions in wide-angle images or are not suitable to perform pixel-level tasks. In this paper, we present an encoder-decoder model based on a radial transformer architecture that adapts to distortions in wide-angle lenses by leveraging the physical characteristics defined by the radial distortion profile. In contrast to the original model, which only performs classification tasks, we introduce a U-Net architecture, DarSwin-Unet, designed for pixel level tasks. Furthermore, we propose a novel strategy that minimizes sparsity when sampling the image for creating its input tokens. Our approach enhances the model capability to handle pixel-level tasks in wide-angle fisheye images, making it more effective for real-world applications. Compared to other baselines, DarSwin-Unet achieves the best results across different datasets, with significant gains when trained on bounded levels of distortions (very low, low, medium, and high) and tested on all, including out-of-distribution distortions. We demonstrate its performance on depth estimation and show through extensive experiments that DarSwin-Unet can perform zero-shot adaptation to unseen distortions of different wide-angle lenses.
Read more7/25/2024