Learning Generalized Medical Image Representations through Image-Graph Contrastive Pretraining
2405.09594
0
0

Abstract
Medical image interpretation using deep learning has shown promise but often requires extensive expert-annotated datasets. To reduce this annotation burden, we develop an Image-Graph Contrastive Learning framework that pairs chest X-rays with structured report knowledge graphs automatically extracted from radiology notes. Our approach uniquely encodes the disconnected graph components via a relational graph convolution network and transformer attention. In experiments on the CheXpert dataset, this novel graph encoding strategy enabled the framework to outperform existing methods that use image-text contrastive learning in 1% linear evaluation and few-shot settings, while achieving comparable performance to radiologists. By exploiting unlabeled paired images and text, our framework demonstrates the potential of structured clinical insights to enhance contrastive learning for medical images. This work points toward reducing demands on medical experts for annotations, improving diagnostic precision, and advancing patient care through robust medical image understanding.
Create account to get full access
Overview
- This research paper presents a novel approach for learning generalized medical image representations through image-graph contrastive pretraining.
- The proposed method leverages the structural and semantic information encoded in medical knowledge graphs to learn more robust and transferable image representations compared to existing self-supervised and supervised learning approaches.
- The authors demonstrate the effectiveness of their method on various medical image analysis tasks, including classification, segmentation, and retrieval, across different modalities such as chest X-rays, chest CT scans, and whole-slide histopathology images.
Plain English Explanation
The paper introduces a new way to train AI models to better understand medical images, such as X-rays, CT scans, and microscope slides. The key idea is to use the knowledge encoded in medical databases, which contain information about the relationships between different medical concepts, to help the AI model learn more meaningful and transferable representations of the images.
Typically, AI models for medical image analysis are trained on large datasets of labeled images, where the labels correspond to medical conditions or other relevant information. However, this approach has limitations, as the models may struggle to generalize to new tasks or datasets.
The proposed method, called image-graph contrastive pretraining, aims to address this by training the AI model to not only recognize the contents of the images, but also to understand the relationships between different medical concepts that are relevant to the images. This is done by presenting the model with pairs of related images and medical knowledge graphs, and training it to recognize when the images and graphs are matched correctly.
By learning these more nuanced and generalized representations, the model can then be more effectively applied to a variety of medical image analysis tasks, such as diagnosing conditions from chest X-rays, segmenting anatomical structures in CT scans, or classifying tissue samples from histopathology slides.
Technical Explanation
The key technical innovation of this work is the use of image-graph contrastive pretraining to learn generalized medical image representations. The authors first construct a large-scale medical knowledge graph by integrating various biomedical ontologies and databases. They then develop a contrastive learning framework that jointly encodes the visual and semantic information from medical images and their corresponding knowledge graph representations.
Specifically, the model is trained to maximize the similarity between the representations of an image and its associated knowledge graph, while minimizing the similarity between the image and unrelated knowledge graphs. This encourages the model to learn image representations that capture the underlying medical concepts and their relationships, rather than just recognizing low-level visual patterns.
The authors evaluate their method on a range of medical image analysis tasks, including classification, segmentation, and retrieval, across different modalities such as chest X-rays, chest CT scans, and whole-slide histopathology images. The results demonstrate that the proposed pretraining approach leads to significant performance improvements compared to existing self-supervised and supervised learning methods.
Critical Analysis
One potential limitation of the proposed approach is the reliance on the availability and quality of the medical knowledge graph. The authors acknowledge that constructing a comprehensive and accurate knowledge graph can be challenging, and the performance of their method may be affected by the completeness and accuracy of the underlying knowledge base.
Additionally, the authors do not extensively explore the interpretability of the learned image representations or the specific medical concepts that are being captured by the model. Further analysis in this direction could provide valuable insights into the inner workings of the model and help build trust in its decisions.
Finally, while the authors demonstrate the effectiveness of their method on a range of medical image analysis tasks, it would be interesting to see how it performs on more challenging and diverse datasets, especially those that may have significant domain shift from the pretraining data.
Conclusion
This research paper presents a novel approach for learning generalized medical image representations through image-graph contrastive pretraining. By leveraging the structural and semantic information encoded in medical knowledge graphs, the proposed method can learn more robust and transferable image representations, leading to improved performance on a variety of medical image analysis tasks.
The key contribution of this work is the integration of visual and semantic information, which allows the model to capture the underlying medical concepts and their relationships, rather than just recognizing low-level visual patterns. This approach has the potential to significantly advance the state-of-the-art in medical image understanding and enable more accurate and interpretable AI-powered clinical decision support systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔗
Grounded Knowledge-Enhanced Medical VLP for Chest X-Ray
Qiao Deng, Zhongzhen Huang, Yunqi Wang, Zhichuan Wang, Zhao Wang, Xiaofan Zhang, Qi Dou, Yeung Yu Hui, Edward S. Hui
0
0
Medical vision-language pre-training has emerged as a promising approach for learning domain-general representations of medical image and text. Current algorithms that exploit the global and local alignment between medical image and text could however be marred by the redundant information in medical data. To address this issue, we propose a grounded knowledge-enhanced medical vision-language pre-training (GK-MVLP) framework for chest X-ray. In this framework, medical knowledge is grounded to the appropriate anatomical regions by using a transformer-based grounded knowledge-enhanced module for fine-grained alignment between anatomical region-level visual features and the textural features of medical knowledge. The performance of GK-MVLP is competitive with or exceeds the state of the art on downstream chest X-ray disease classification, disease localization, report generation, and medical visual question-answering tasks. Our results show the advantage of incorporating grounding mechanism to remove biases and improve the alignment between chest X-ray image and radiology report.
4/24/2024
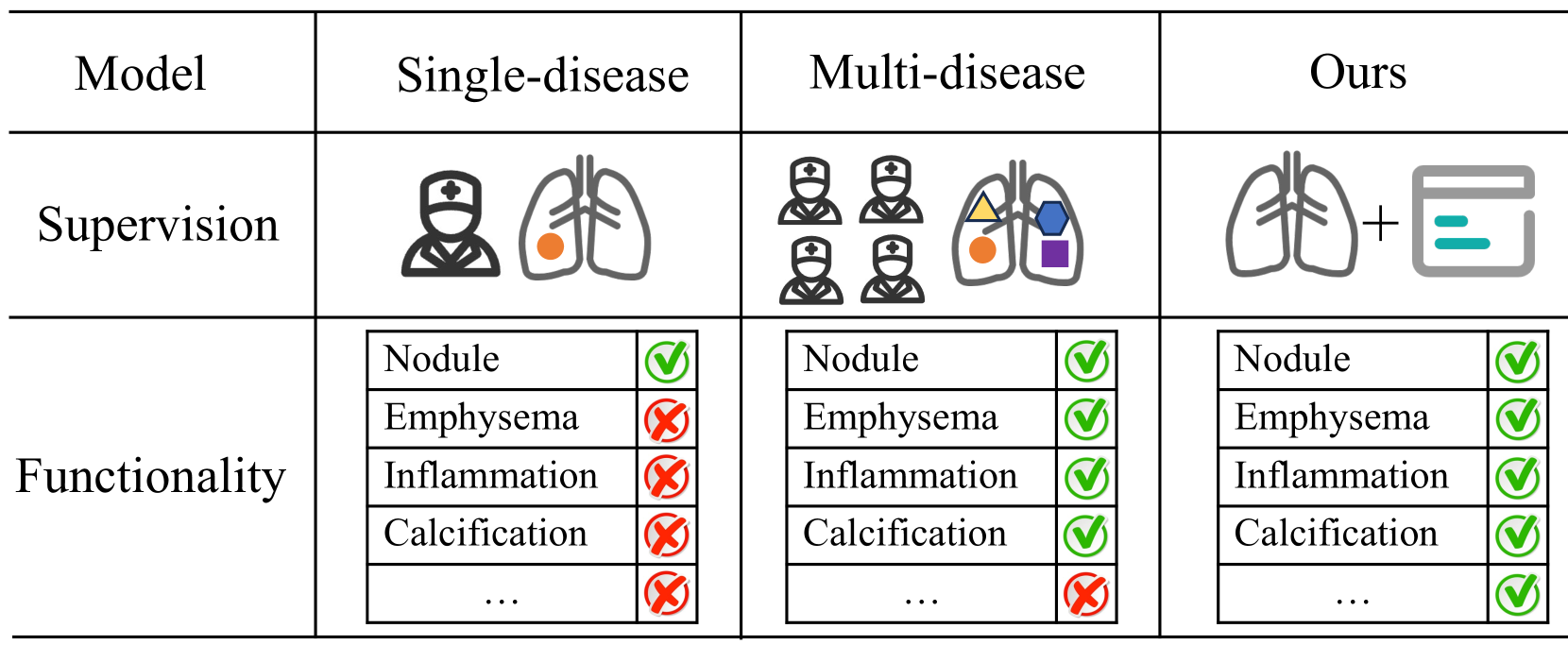
Bootstrapping Chest CT Image Understanding by Distilling Knowledge from X-ray Expert Models
Weiwei Cao, Jianpeng Zhang, Yingda Xia, Tony C. W. Mok, Zi Li, Xianghua Ye, Le Lu, Jian Zheng, Yuxing Tang, Ling Zhang
0
0
Radiologists highly desire fully automated versatile AI for medical imaging interpretation. However, the lack of extensively annotated large-scale multi-disease datasets has hindered the achievement of this goal. In this paper, we explore the feasibility of leveraging language as a naturally high-quality supervision for chest CT imaging. In light of the limited availability of image-report pairs, we bootstrap the understanding of 3D chest CT images by distilling chest-related diagnostic knowledge from an extensively pre-trained 2D X-ray expert model. Specifically, we propose a language-guided retrieval method to match each 3D CT image with its semantically closest 2D X-ray image, and perform pair-wise and semantic relation knowledge distillation. Subsequently, we use contrastive learning to align images and reports within the same patient while distinguishing them from the other patients. However, the challenge arises when patients have similar semantic diagnoses, such as healthy patients, potentially confusing if treated as negatives. We introduce a robust contrastive learning that identifies and corrects these false negatives. We train our model with over 12,000 pairs of chest CT images and radiology reports. Extensive experiments across multiple scenarios, including zero-shot learning, report generation, and fine-tuning processes, demonstrate the model's feasibility in interpreting chest CT images.
4/9/2024

Benchmarking Vision-Language Contrastive Methods for Medical Representation Learning
Shuvendu Roy, Yasaman Parhizkar, Franklin Ogidi, Vahid Reza Khazaie, Michael Colacci, Ali Etemad, Elham Dolatabadi, Arash Afkanpour
0
0
We perform a comprehensive benchmarking of contrastive frameworks for learning multimodal representations in the medical domain. Through this study, we aim to answer the following research questions: (i) How transferable are general-domain representations to the medical domain? (ii) Is multimodal contrastive training sufficient, or does it benefit from unimodal training as well? (iii) What is the impact of feature granularity on the effectiveness of multimodal medical representation learning? To answer these questions, we investigate eight contrastive learning approaches under identical training setups, and train them on 2.8 million image-text pairs from four datasets, and evaluate them on 25 downstream tasks, including classification (zero-shot and linear probing), image-to-text and text-to-image retrieval, and visual question-answering. Our findings suggest a positive answer to the first question, a negative answer to the second question, and the benefit of learning fine-grained features. Finally, we make our code publicly available.
6/12/2024

A Clinical-oriented Multi-level Contrastive Learning Method for Disease Diagnosis in Low-quality Medical Images
Qingshan Hou, Shuai Cheng, Peng Cao, Jinzhu Yang, Xiaoli Liu, Osmar R. Zaiane, Yih Chung Tham
0
0
Representation learning offers a conduit to elucidate distinctive features within the latent space and interpret the deep models. However, the randomness of lesion distribution and the complexity of low-quality factors in medical images pose great challenges for models to extract key lesion features. Disease diagnosis methods guided by contrastive learning (CL) have shown significant advantages in lesion feature representation. Nevertheless, the effectiveness of CL is highly dependent on the quality of the positive and negative sample pairs. In this work, we propose a clinical-oriented multi-level CL framework that aims to enhance the model's capacity to extract lesion features and discriminate between lesion and low-quality factors, thereby enabling more accurate disease diagnosis from low-quality medical images. Specifically, we first construct multi-level positive and negative pairs to enhance the model's comprehensive recognition capability of lesion features by integrating information from different levels and qualities of medical images. Moreover, to improve the quality of the learned lesion embeddings, we introduce a dynamic hard sample mining method based on self-paced learning. The proposed CL framework is validated on two public medical image datasets, EyeQ and Chest X-ray, demonstrating superior performance compared to other state-of-the-art disease diagnostic methods.
4/9/2024