Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection

0
🔎
Sign in to get full access
Overview
- Presents an open-set object detector called Grounding DINO
- Combines Transformer-based detector DINO with grounded pre-training
- Allows detection of arbitrary objects using human inputs like category names or referring expressions
- Key solution is introducing language to a closed-set detector for open-set concept generalization
Plain English Explanation
Grounding DINO is a new object detection system that can identify all kinds of objects, not just a fixed set. It works by combining two key technologies:
-
Transformer-based Detector: Grounding DINO builds on the DINO object detector, which uses a Transformer neural network to identify objects in images.
-
Grounded Pre-training: Grounding DINO also incorporates "grounded pre-training", which means the system is pre-trained on language data (like text descriptions of objects) to better understand how language and visual concepts are related.
This combination allows Grounding DINO to detect any object that can be described with language, rather than just a limited set of predefined object categories. For example, it could detect "the red umbrella on the table" or "the large dog running in the park", even if those specific objects were not in its training data.
The key innovation is finding a way to effectively fuse the language and vision aspects of the system. Grounding DINO does this by dividing the object detection process into three phases and tightly integrating language at each step.
Overall, Grounding DINO demonstrates strong performance on a variety of open-set object detection benchmarks, setting new records in some cases. This advances the state-of-the-art in computer vision by moving beyond rigid object categories towards more flexible and human-centric object detection.
Technical Explanation
Grounding DINO builds on the DINO object detection model, which uses a Transformer-based architecture to perform object detection. To enable open-set detection, the researchers marry DINO with "grounded pre-training", which involves pre-training the system on language data to learn the connections between language and visual concepts.
The key technical innovation is the way Grounding DINO fuses the language and vision modalities. The researchers divide the object detection process into three phases:
- Feature Enhancer: This module takes the visual features from the Transformer and enhances them using language information.
- Language-Guided Query Selection: The system selects which object proposals to focus on based on the language input.
- Cross-Modality Decoder: This final module performs the ultimate object detection by decoding the cross-modal features.
By tightly integrating language at each of these steps, Grounding DINO is able to effectively leverage both visual and linguistic information to detect a wide range of objects, not just a fixed set.
The researchers evaluate Grounding DINO on several benchmarks, including zero-shot transfer to the COCO dataset, the ODinW zero-shot benchmark, and referring expression comprehension tasks like RefCOCO/+/g. Grounding DINO achieves state-of-the-art results, setting new records in some cases.
Critical Analysis
The paper provides a thorough evaluation of Grounding DINO's performance on a variety of open-set object detection tasks. However, the authors do not delve deeply into the potential limitations or failure cases of the system.
One area that could use more discussion is the reliance on language data for the grounded pre-training. While this is a key aspect of the approach, the paper does not explore how the quality, coverage, or biases in the language data might impact the system's performance, especially for detecting more obscure or specialized objects.
Additionally, the paper does not address potential fairness or ethical concerns that could arise from an open-set object detector. For example, if the language data used for pre-training reflects societal biases, the system could perpetuate or amplify those biases in its detections.
Overall, the research represents a significant advance in open-set object detection, but further exploration of the method's limitations and potential issues would strengthen the critical analysis.
Conclusion
This paper presents Grounding DINO, an innovative open-set object detector that combines Transformer-based computer vision with grounded language pre-training. By tightly integrating language and vision, Grounding DINO can detect a wide range of objects, not just a fixed set, using natural language inputs like category names or referring expressions.
The technical approach of dividing the object detection process into three phases and fusing language at each step is a key contribution. Grounding DINO demonstrates state-of-the-art performance on several open-set detection benchmarks, setting new records in some cases.
This research represents an important step forward in making object detection more flexible and human-centric, moving beyond rigid object categories towards a more natural, language-grounded understanding of the visual world. Further exploration of the method's limitations and potential ethical considerations could strengthen the work, but overall, Grounding DINO is a significant advance in open-set object detection.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang
In this paper, we present an open-set object detector, called Grounding DINO, by marrying Transformer-based detector DINO with grounded pre-training, which can detect arbitrary objects with human inputs such as category names or referring expressions. The key solution of open-set object detection is introducing language to a closed-set detector for open-set concept generalization. To effectively fuse language and vision modalities, we conceptually divide a closed-set detector into three phases and propose a tight fusion solution, which includes a feature enhancer, a language-guided query selection, and a cross-modality decoder for cross-modality fusion. While previous works mainly evaluate open-set object detection on novel categories, we propose to also perform evaluations on referring expression comprehension for objects specified with attributes. Grounding DINO performs remarkably well on all three settings, including benchmarks on COCO, LVIS, ODinW, and RefCOCO/+/g. Grounding DINO achieves a $52.5$ AP on the COCO detection zero-shot transfer benchmark, i.e., without any training data from COCO. It sets a new record on the ODinW zero-shot benchmark with a mean $26.1$ AP. Code will be available at url{https://github.com/IDEA-Research/GroundingDINO}.
Read more7/22/2024

0
Grounding DINO 1.5: Advance the Edge of Open-Set Object Detection
Tianhe Ren, Qing Jiang, Shilong Liu, Zhaoyang Zeng, Wenlong Liu, Han Gao, Hongjie Huang, Zhengyu Ma, Xiaoke Jiang, Yihao Chen, Yuda Xiong, Hao Zhang, Feng Li, Peijun Tang, Kent Yu, Lei Zhang
This paper introduces Grounding DINO 1.5, a suite of advanced open-set object detection models developed by IDEA Research, which aims to advance the Edge of open-set object detection. The suite encompasses two models: Grounding DINO 1.5 Pro, a high-performance model designed for stronger generalization capability across a wide range of scenarios, and Grounding DINO 1.5 Edge, an efficient model optimized for faster speed demanded in many applications requiring edge deployment. The Grounding DINO 1.5 Pro model advances its predecessor by scaling up the model architecture, integrating an enhanced vision backbone, and expanding the training dataset to over 20 million images with grounding annotations, thereby achieving a richer semantic understanding. The Grounding DINO 1.5 Edge model, while designed for efficiency with reduced feature scales, maintains robust detection capabilities by being trained on the same comprehensive dataset. Empirical results demonstrate the effectiveness of Grounding DINO 1.5, with the Grounding DINO 1.5 Pro model attaining a 54.3 AP on the COCO detection benchmark and a 55.7 AP on the LVIS-minival zero-shot transfer benchmark, setting new records for open-set object detection. Furthermore, the Grounding DINO 1.5 Edge model, when optimized with TensorRT, achieves a speed of 75.2 FPS while attaining a zero-shot performance of 36.2 AP on the LVIS-minival benchmark, making it more suitable for edge computing scenarios. Model examples and demos with API will be released at https://github.com/IDEA-Research/Grounding-DINO-1.5-API
Read more6/4/2024

0
OV-DINO: Unified Open-Vocabulary Detection with Language-Aware Selective Fusion
Hao Wang, Pengzhen Ren, Zequn Jie, Xiao Dong, Chengjian Feng, Yinlong Qian, Lin Ma, Dongmei Jiang, Yaowei Wang, Xiangyuan Lan, Xiaodan Liang
Open-vocabulary detection is a challenging task due to the requirement of detecting objects based on class names, including those not encountered during training. Existing methods have shown strong zero-shot detection capabilities through pre-training and pseudo-labeling on diverse large-scale datasets. However, these approaches encounter two main challenges: (i) how to effectively eliminate data noise from pseudo-labeling, and (ii) how to efficiently leverage the language-aware capability for region-level cross-modality fusion and alignment. To address these challenges, we propose a novel unified open-vocabulary detection method called OV-DINO, which is pre-trained on diverse large-scale datasets with language-aware selective fusion in a unified framework. Specifically, we introduce a Unified Data Integration (UniDI) pipeline to enable end-to-end training and eliminate noise from pseudo-label generation by unifying different data sources into detection-centric data format. In addition, we propose a Language-Aware Selective Fusion (LASF) module to enhance the cross-modality alignment through a language-aware query selection and fusion process. We evaluate the performance of the proposed OV-DINO on popular open-vocabulary detection benchmarks, achieving state-of-the-art results with an AP of 50.6% on the COCO benchmark and 40.1% on the LVIS benchmark in a zero-shot manner, demonstrating its strong generalization ability. Furthermore, the fine-tuned OV-DINO on COCO achieves 58.4% AP, outperforming many existing methods with the same backbone. The code for OV-DINO is available at https://github.com/wanghao9610/OV-DINO.
Read more7/23/2024
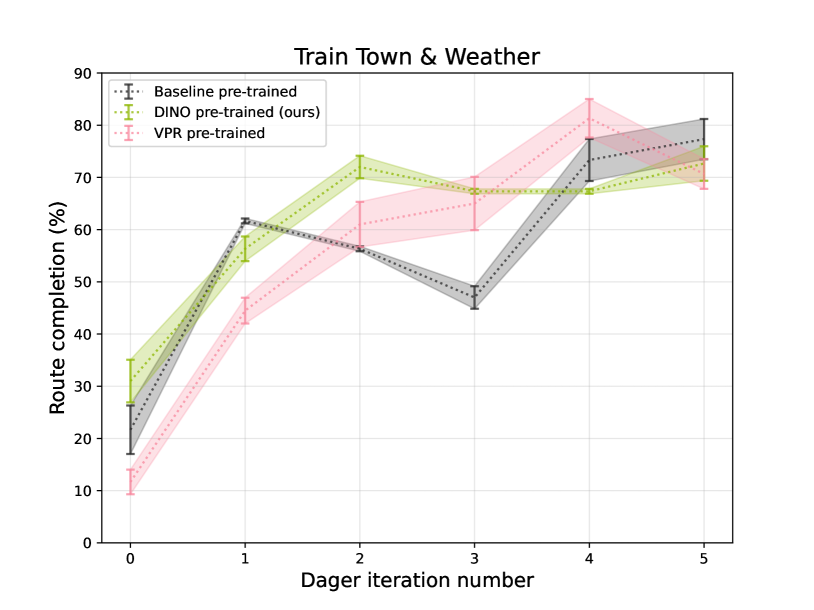
0
DINO Pre-training for Vision-based End-to-end Autonomous Driving
Shubham Juneja, Povilas Daniuv{s}is, Virginijus Marcinkeviv{c}ius
In this article, we focus on the pre-training of visual autonomous driving agents in the context of imitation learning. Current methods often rely on a classification-based pre-training, which we hypothesise to be holding back from extending capabilities of implicit image understanding. We propose pre-training the visual encoder of a driving agent using the self-distillation with no labels (DINO) method, which relies on a self-supervised learning paradigm.% and is trained on an unrelated task. Our experiments in CARLA environment in accordance with the Leaderboard benchmark reveal that the proposed pre-training is more efficient than classification-based pre-training, and is on par with the recently proposed pre-training based on visual place recognition (VPRPre).
Read more7/16/2024