DINO Pre-training for Vision-based End-to-end Autonomous Driving

0
Sign in to get full access
Overview
- The paper presents a pre-training approach called DINO (DIscovery via Noise-augmented Objects) for vision-based end-to-end autonomous driving.
- DINO leverages self-supervised learning to train a vision transformer model to recognize and detect objects in driving scenes without explicit labeling.
- The model is then fine-tuned for downstream tasks like predicting steering angles and other driving actions.
Plain English Explanation
The researchers have developed a new way to teach self-driving car AI systems how to understand what they "see" on the road. Traditionally, these systems are trained on huge datasets of driving scenes that have been manually labeled by humans. This is a time-consuming and expensive process.
The key innovation in this paper is a pre-training approach called DINO that allows the AI to learn to recognize objects and other important elements of driving scenes without any human-provided labels. The system is trained on a large dataset of unlabeled driving footage, and through a process of "self-discovery", it learns to identify things like cars, pedestrians, road signs, and other relevant objects.
Once the DINO model has been pre-trained in this self-supervised way, it can then be fine-tuned for specific driving tasks, like predicting the appropriate steering angle or other control actions. This pre-training step helps the model develop a more robust and generalizable understanding of driving scenes, which can improve its performance on these downstream tasks.
The advantage of this approach is that it reduces the need for expensive and time-consuming manual labeling of driving data. By allowing the AI to learn autonomously, the researchers can potentially scale up the training process and create more capable self-driving systems.
Technical Explanation
The DINO pre-training approach leverages self-supervised learning to train a vision transformer model to recognize and detect objects in driving scenes without explicit labeling. The model is trained on a large dataset of unlabeled driving footage, and through a process of self-discovery, it learns to identify relevant elements of the driving environment.
The key innovation is the use of noise augmentation during pre-training, which encourages the model to focus on the most salient objects and features in the scene. This helps the model develop a more robust and generalizable understanding of driving scenes, which can then be leveraged for downstream tasks like predicting steering angles and other control actions.
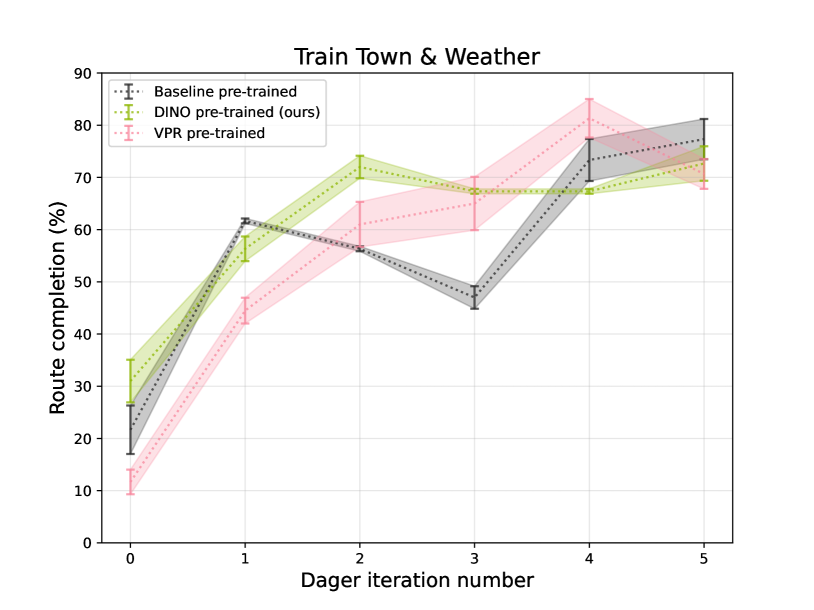
The paper demonstrates that the DINO pre-trained model outperforms other self-supervised and fully-supervised baselines on these downstream tasks, highlighting the benefits of this approach for end-to-end autonomous driving applications.
Critical Analysis
The paper presents a promising approach for reducing the need for expensive and time-consuming manual labeling of driving data for self-driving car development. By leveraging self-supervised learning, the DINO model is able to develop a more comprehensive understanding of driving scenes without relying on human-provided annotations.
However, the paper does not address the potential limitations of this approach, such as the impact of biases in the unlabeled training data or the ability of the model to generalize to novel driving scenarios. Additionally, the paper focuses on relatively simple driving tasks like predicting steering angles, and it remains to be seen how well the DINO model would perform on more complex driving scenarios or in real-world deployment.
Further research is needed to explore the generalizability and robustness of the DINO approach, as well as to investigate its potential limitations and edge cases. Nonetheless, this work represents an important step forward in developing more scalable and efficient methods for training vision-based autonomous driving systems.
Conclusion
The DINO pre-training approach presented in this paper offers a promising solution for reducing the cost and complexity of training vision-based autonomous driving systems. By leveraging self-supervised learning, the model is able to develop a more comprehensive understanding of driving scenes without the need for expensive manual labeling.
The demonstrated performance improvements on downstream tasks like steering angle prediction suggest that this approach could be valuable for a wide range of end-to-end autonomous driving applications. As the field of self-driving cars continues to evolve, methods like DINO that can scale training efficiently while maintaining robust performance will likely play an increasingly important role in the development of practical and reliable autonomous driving solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DINO Pre-training for Vision-based End-to-end Autonomous Driving
Shubham Juneja, Povilas Daniuv{s}is, Virginijus Marcinkeviv{c}ius
In this article, we focus on the pre-training of visual autonomous driving agents in the context of imitation learning. Current methods often rely on a classification-based pre-training, which we hypothesise to be holding back from extending capabilities of implicit image understanding. We propose pre-training the visual encoder of a driving agent using the self-distillation with no labels (DINO) method, which relies on a self-supervised learning paradigm.% and is trained on an unrelated task. Our experiments in CARLA environment in accordance with the Leaderboard benchmark reveal that the proposed pre-training is more efficient than classification-based pre-training, and is on par with the recently proposed pre-training based on visual place recognition (VPRPre).
Read more7/16/2024

0
Guiding Attention in End-to-End Driving Models
Diego Porres, Yi Xiao, Gabriel Villalonga, Alexandre Levy, Antonio M. L'opez
Vision-based end-to-end driving models trained by imitation learning can lead to affordable solutions for autonomous driving. However, training these well-performing models usually requires a huge amount of data, while still lacking explicit and intuitive activation maps to reveal the inner workings of these models while driving. In this paper, we study how to guide the attention of these models to improve their driving quality and obtain more intuitive activation maps by adding a loss term during training using salient semantic maps. In contrast to previous work, our method does not require these salient semantic maps to be available during testing time, as well as removing the need to modify the model's architecture to which it is applied. We perform tests using perfect and noisy salient semantic maps with encouraging results in both, the latter of which is inspired by possible errors encountered with real data. Using CIL++ as a representative state-of-the-art model and the CARLA simulator with its standard benchmarks, we conduct experiments that show the effectiveness of our method in training better autonomous driving models, especially when data and computational resources are scarce.
Read more5/2/2024
🔗
0
VANP: Learning Where to See for Navigation with Self-Supervised Vision-Action Pre-Training
Mohammad Nazeri, Junzhe Wang, Amirreza Payandeh, Xuesu Xiao
Humans excel at efficiently navigating through crowds without collision by focusing on specific visual regions relevant to navigation. However, most robotic visual navigation methods rely on deep learning models pre-trained on vision tasks, which prioritize salient objects -- not necessarily relevant to navigation and potentially misleading. Alternative approaches train specialized navigation models from scratch, requiring significant computation. On the other hand, self-supervised learning has revolutionized computer vision and natural language processing, but its application to robotic navigation remains underexplored due to the difficulty of defining effective self-supervision signals. Motivated by these observations, in this work, we propose a Self-Supervised Vision-Action Model for Visual Navigation Pre-Training (VANP). Instead of detecting salient objects that are beneficial for tasks such as classification or detection, VANP learns to focus only on specific visual regions that are relevant to the navigation task. To achieve this, VANP uses a history of visual observations, future actions, and a goal image for self-supervision, and embeds them using two small Transformer Encoders. Then, VANP maximizes the information between the embeddings by using a mutual information maximization objective function. We demonstrate that most VANP-extracted features match with human navigation intuition. VANP achieves comparable performance as models learned end-to-end with half the training time and models trained on a large-scale, fully supervised dataset, i.e., ImageNet, with only 0.08% data.
Read more9/6/2024
0
Exploring Self-Supervised Vision Transformers for Deepfake Detection: A Comparative Analysis
Huy H. Nguyen, Junichi Yamagishi, Isao Echizen
This paper investigates the effectiveness of self-supervised pre-trained vision transformers (ViTs) compared to supervised pre-trained ViTs and conventional neural networks (ConvNets) for detecting facial deepfake images and videos. It examines their potential for improved generalization and explainability, especially with limited training data. Despite the success of transformer architectures in various tasks, the deepfake detection community is hesitant to use large ViTs as feature extractors due to their perceived need for extensive data and suboptimal generalization with small datasets. This contrasts with ConvNets, which are already established as robust feature extractors. Additionally, training ViTs from scratch requires significant resources, limiting their use to large companies. Recent advancements in self-supervised learning (SSL) for ViTs, like masked autoencoders and DINOs, show adaptability across diverse tasks and semantic segmentation capabilities. By leveraging SSL ViTs for deepfake detection with modest data and partial fine-tuning, we find comparable adaptability to deepfake detection and explainability via the attention mechanism. Moreover, partial fine-tuning of ViTs is a resource-efficient option.
Read more8/12/2024