GTPT: Group-based Token Pruning Transformer for Efficient Human Pose Estimation

0
Sign in to get full access
Overview
- This research paper presents a novel approach called GTPT (Group-based Token Pruning Transformer) for efficient human pose estimation.
- GTPT aims to improve the efficiency of Transformer-based models for human pose estimation by selectively pruning tokens during inference.
- The paper introduces a group-based token pruning mechanism that identifies and removes redundant tokens, reducing computational costs without significantly impacting performance.
Plain English Explanation
Human pose estimation is an important task in computer vision, where the goal is to accurately determine the positions of different body parts (e.g., joints) in an image or video. This information can be useful for a variety of applications, such as human-computer interaction, motion capture, and sports analytics.
GTPT: Group-based Token Pruning Transformer for Efficient Human Pose Estimation tackles the challenge of making human pose estimation more efficient, particularly for Transformer-based models. Transformers have recently shown impressive performance in various computer vision tasks, including pose estimation, but they can be computationally expensive during inference.
The key idea behind GTPT is to selectively prune, or remove, certain tokens (the basic units of information in a Transformer model) during inference, without significantly compromising the model's accuracy. This is achieved through a "group-based token pruning" mechanism, which identifies and removes redundant tokens that do not contribute much to the final pose estimation.
By reducing the number of tokens that need to be processed, GTPT can significantly improve the efficiency of the Transformer-based pose estimation model, making it more suitable for real-world applications with limited computational resources, such as mobile devices or embedded systems.
Technical Explanation
The GTPT approach builds upon the success of Transformer-based models for human pose estimation, such as TokenHMR: Advancing Human Mesh Recovery with Tokenized Pose and Graph-Skipped Transformer: Exploiting Spatial-Temporal Modeling.
The core innovation of GTPT is the group-based token pruning mechanism, which operates during the inference stage of the Transformer-based pose estimation model. The method first groups the tokens based on their spatial and semantic similarities, and then selectively prunes the less important tokens within each group.
This selective pruning is achieved by computing a "group importance score" for each group of tokens, which reflects the group's contribution to the final pose estimation. Tokens with lower importance scores are then removed, reducing the overall computational cost of the model without significantly impacting its accuracy.
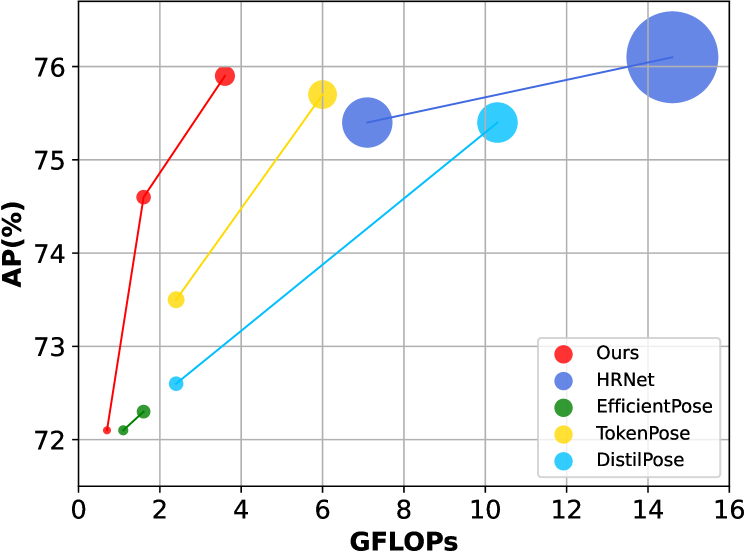
The GTPT approach is evaluated on various human pose estimation benchmarks, such as COCO and MPII, and demonstrates improved efficiency while maintaining comparable or better performance compared to state-of-the-art Transformer-based models, such as Efficient Point Transformer: Dynamic Token Aggregating Point and PhysPT: Physics-aware Pretrained Transformer for Estimating Human.
Critical Analysis
The GTPT paper presents a promising approach for improving the efficiency of Transformer-based human pose estimation models. The group-based token pruning mechanism is a novel and intuitive solution to the challenge of reducing computational costs without sacrificing model performance.
One potential limitation of the GTPT approach is that the group importance score computation and token pruning strategies may not be universally optimal for all types of pose estimation tasks or datasets. The paper does not explore the sensitivity of the method to different task-specific or dataset-specific characteristics.
Additionally, the paper does not provide a comprehensive analysis of the trade-offs between the degree of token pruning and the resulting model accuracy. A deeper understanding of this relationship could help researchers and practitioners better balance the efficiency and performance of GTPT-based models.
Further research could also explore the integration of GTPT with other efficiency-enhancing techniques, such as STGFormer: Spatio-Temporal Graphformer for 3D Human Pose, to achieve even greater computational savings without sacrificing too much accuracy.
Conclusion
The GTPT paper presents a novel and promising approach to improving the efficiency of Transformer-based human pose estimation models. By introducing a group-based token pruning mechanism, the researchers were able to selectively remove redundant tokens during inference, leading to significant computational savings without a substantial impact on model performance.
This work contributes to the ongoing efforts to develop more efficient and practical pose estimation solutions, which is crucial for real-world applications with limited computational resources. The GTPT approach demonstrates the potential of leveraging the strengths of Transformers while addressing their efficiency challenges, and it opens up new avenues for further research and development in this important field of computer vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GTPT: Group-based Token Pruning Transformer for Efficient Human Pose Estimation
Haonan Wang, Jie Liu, Jie Tang, Gangshan Wu, Bo Xu, Yanbing Chou, Yong Wang
In recent years, 2D human pose estimation has made significant progress on public benchmarks. However, many of these approaches face challenges of less applicability in the industrial community due to the large number of parametric quantities and computational overhead. Efficient human pose estimation remains a hurdle, especially for whole-body pose estimation with numerous keypoints. While most current methods for efficient human pose estimation primarily rely on CNNs, we propose the Group-based Token Pruning Transformer (GTPT) that fully harnesses the advantages of the Transformer. GTPT alleviates the computational burden by gradually introducing keypoints in a coarse-to-fine manner. It minimizes the computation overhead while ensuring high performance. Besides, GTPT groups keypoint tokens and prunes visual tokens to improve model performance while reducing redundancy. We propose the Multi-Head Group Attention (MHGA) between different groups to achieve global interaction with little computational overhead. We conducted experiments on COCO and COCO-WholeBody. Compared to other methods, the experimental results show that GTPT can achieve higher performance with less computation, especially in whole-body with numerous keypoints.
Read more7/17/2024

0
TokenHMR: Advancing Human Mesh Recovery with a Tokenized Pose Representation
Sai Kumar Dwivedi, Yu Sun, Priyanka Patel, Yao Feng, Michael J. Black
We address the problem of regressing 3D human pose and shape from a single image, with a focus on 3D accuracy. The current best methods leverage large datasets of 3D pseudo-ground-truth (p-GT) and 2D keypoints, leading to robust performance. With such methods, we observe a paradoxical decline in 3D pose accuracy with increasing 2D accuracy. This is caused by biases in the p-GT and the use of an approximate camera projection model. We quantify the error induced by current camera models and show that fitting 2D keypoints and p-GT accurately causes incorrect 3D poses. Our analysis defines the invalid distances within which minimizing 2D and p-GT losses is detrimental. We use this to formulate a new loss Threshold-Adaptive Loss Scaling (TALS) that penalizes gross 2D and p-GT losses but not smaller ones. With such a loss, there are many 3D poses that could equally explain the 2D evidence. To reduce this ambiguity we need a prior over valid human poses but such priors can introduce unwanted bias. To address this, we exploit a tokenized representation of human pose and reformulate the problem as token prediction. This restricts the estimated poses to the space of valid poses, effectively providing a uniform prior. Extensive experiments on the EMDB and 3DPW datasets show that our reformulated keypoint loss and tokenization allows us to train on in-the-wild data while improving 3D accuracy over the state-of-the-art. Our models and code are available for research at https://tokenhmr.is.tue.mpg.de.
Read more4/26/2024

0
Graph and Skipped Transformer: Exploiting Spatial and Temporal Modeling Capacities for Efficient 3D Human Pose Estimation
Mengmeng Cui, Kunbo Zhang, Zhenan Sun
In recent years, 2D-to-3D pose uplifting in monocular 3D Human Pose Estimation (HPE) has attracted widespread research interest. GNN-based methods and Transformer-based methods have become mainstream architectures due to their advanced spatial and temporal feature learning capacities. However, existing approaches typically construct joint-wise and frame-wise attention alignments in spatial and temporal domains, resulting in dense connections that introduce considerable local redundancy and computational overhead. In this paper, we take a global approach to exploit spatio-temporal information and realise efficient 3D HPE with a concise Graph and Skipped Transformer architecture. Specifically, in Spatial Encoding stage, coarse-grained body parts are deployed to construct Spatial Graph Network with a fully data-driven adaptive topology, ensuring model flexibility and generalizability across various poses. In Temporal Encoding and Decoding stages, a simple yet effective Skipped Transformer is proposed to capture long-range temporal dependencies and implement hierarchical feature aggregation. A straightforward Data Rolling strategy is also developed to introduce dynamic information into 2D pose sequence. Extensive experiments are conducted on Human3.6M, MPI-INF-3DHP and Human-Eva benchmarks. G-SFormer series methods achieve superior performances compared with previous state-of-the-arts with only around ten percent of parameters and significantly reduced computational complexity. Additionally, G-SFormer also exhibits outstanding robustness to inaccuracies in detected 2D poses.
Read more7/4/2024

0
PhysPT: Physics-aware Pretrained Transformer for Estimating Human Dynamics from Monocular Videos
Yufei Zhang, Jeffrey O. Kephart, Zijun Cui, Qiang Ji
While current methods have shown promising progress on estimating 3D human motion from monocular videos, their motion estimates are often physically unrealistic because they mainly consider kinematics. In this paper, we introduce Physics-aware Pretrained Transformer (PhysPT), which improves kinematics-based motion estimates and infers motion forces. PhysPT exploits a Transformer encoder-decoder backbone to effectively learn human dynamics in a self-supervised manner. Moreover, it incorporates physics principles governing human motion. Specifically, we build a physics-based body representation and contact force model. We leverage them to impose novel physics-inspired training losses (i.e., force loss, contact loss, and Euler-Lagrange loss), enabling PhysPT to capture physical properties of the human body and the forces it experiences. Experiments demonstrate that, once trained, PhysPT can be directly applied to kinematics-based estimates to significantly enhance their physical plausibility and generate favourable motion forces. Furthermore, we show that these physically meaningful quantities translate into improved accuracy of an important downstream task: human action recognition.
Read more4/9/2024