TokenHMR: Advancing Human Mesh Recovery with a Tokenized Pose Representation

0

Sign in to get full access
Overview
- This paper presents a novel approach called TokenHMR for improving human mesh recovery, which is the process of estimating the 3D shape and pose of a person from an input image or video.
- The key innovation is the use of a tokenized pose representation, where the human body is divided into semantic tokens that are processed separately by the neural network.
- This allows the model to better capture the complex interdependencies between different body parts, leading to more accurate and robust 3D human mesh recovery.
Plain English Explanation
The paper introduces a new technique called TokenHMR for recovering the 3D shape and pose of a person from an image or video. The core idea is to break down the human body into a set of "tokens" - small, interpretable units that represent different body parts.
By processing these tokens separately, the model can better understand the complex relationships between the various limbs and joints. This allows it to more accurately estimate the 3D mesh of the person, which is a detailed 3D model of the human form.
The traditional approach treats the human body as a single, undifferentiated entity, making it harder for the model to capture the nuances of how the different parts move and interact. TokenHMR breaks this holistic view down into semantically meaningful components, leading to significant improvements in the quality and robustness of the 3D mesh recovery.
Technical Explanation
The key innovation in this paper is the use of a tokenized pose representation for 3D human mesh recovery. Rather than processing the entire human body as a single unit, the TokenHMR model divides the body into semantically meaningful tokens, such as the head, torso, arms, and legs.
Each of these tokens is then processed separately by the neural network, allowing the model to better capture the complex interdependencies between different body parts. This is in contrast to traditional approaches that treat the human body as a holistic entity, making it harder to model the nuanced relationships between the various joints and limbs.
The authors demonstrate that this tokenized representation leads to significant improvements in the accuracy and robustness of 3D human mesh recovery, outperforming state-of-the-art methods on standard benchmarks. They also show that the TokenHMR model is more resistant to common challenges, such as occlusions and viewpoint changes, thanks to its ability to reason about the body in a more modular and interpretable way.
Critical Analysis
The TokenHMR approach presents a compelling solution to the problem of 3D human mesh recovery, with the tokenized pose representation offering clear advantages over more holistic approaches.
However, the paper does not fully address the potential limitations of this technique. For example, it is unclear how the TokenHMR model would perform on highly dynamic or unconventional human poses that do not fit neatly into the predefined token structure. Additionally, the computational overhead of processing each token separately may limit the model's efficiency and real-time performance in certain applications.
Further research is needed to explore the generalizability of the TokenHMR approach and address these potential drawbacks. It would also be valuable to investigate how the tokenized representation could be leveraged for other related tasks, such as human motion prediction and action recognition.
Conclusion
The TokenHMR paper presents a novel and promising approach to 3D human mesh recovery, with the key innovation being the use of a tokenized pose representation. By breaking down the human body into semantically meaningful components, the model is able to better capture the complex interdependencies between different body parts, leading to significant improvements in accuracy and robustness.
While the paper demonstrates the effectiveness of this technique on standard benchmarks, further research is needed to fully understand its limitations and potential applications. Nonetheless, the TokenHMR work represents an important step forward in the field of 3D human pose estimation and could have far-reaching implications for a wide range of computer vision and robotics applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TokenHMR: Advancing Human Mesh Recovery with a Tokenized Pose Representation
Sai Kumar Dwivedi, Yu Sun, Priyanka Patel, Yao Feng, Michael J. Black
We address the problem of regressing 3D human pose and shape from a single image, with a focus on 3D accuracy. The current best methods leverage large datasets of 3D pseudo-ground-truth (p-GT) and 2D keypoints, leading to robust performance. With such methods, we observe a paradoxical decline in 3D pose accuracy with increasing 2D accuracy. This is caused by biases in the p-GT and the use of an approximate camera projection model. We quantify the error induced by current camera models and show that fitting 2D keypoints and p-GT accurately causes incorrect 3D poses. Our analysis defines the invalid distances within which minimizing 2D and p-GT losses is detrimental. We use this to formulate a new loss Threshold-Adaptive Loss Scaling (TALS) that penalizes gross 2D and p-GT losses but not smaller ones. With such a loss, there are many 3D poses that could equally explain the 2D evidence. To reduce this ambiguity we need a prior over valid human poses but such priors can introduce unwanted bias. To address this, we exploit a tokenized representation of human pose and reformulate the problem as token prediction. This restricts the estimated poses to the space of valid poses, effectively providing a uniform prior. Extensive experiments on the EMDB and 3DPW datasets show that our reformulated keypoint loss and tokenization allows us to train on in-the-wild data while improving 3D accuracy over the state-of-the-art. Our models and code are available for research at https://tokenhmr.is.tue.mpg.de.
Read more4/26/2024
0
GTPT: Group-based Token Pruning Transformer for Efficient Human Pose Estimation
Haonan Wang, Jie Liu, Jie Tang, Gangshan Wu, Bo Xu, Yanbing Chou, Yong Wang
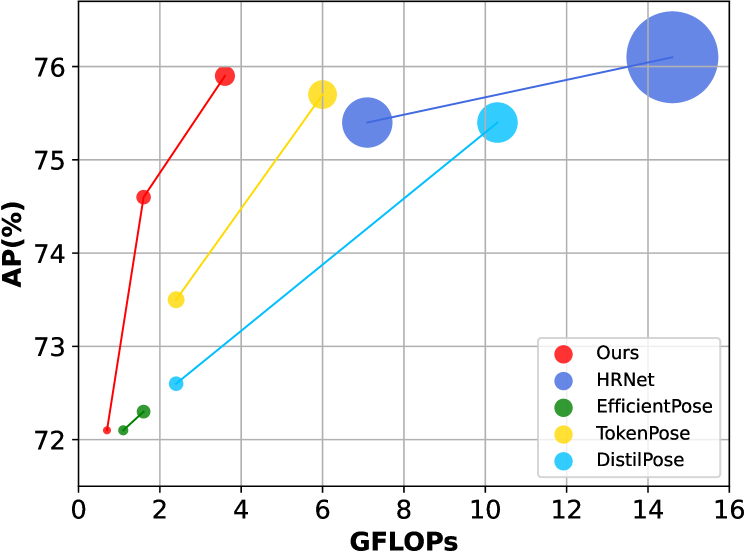
In recent years, 2D human pose estimation has made significant progress on public benchmarks. However, many of these approaches face challenges of less applicability in the industrial community due to the large number of parametric quantities and computational overhead. Efficient human pose estimation remains a hurdle, especially for whole-body pose estimation with numerous keypoints. While most current methods for efficient human pose estimation primarily rely on CNNs, we propose the Group-based Token Pruning Transformer (GTPT) that fully harnesses the advantages of the Transformer. GTPT alleviates the computational burden by gradually introducing keypoints in a coarse-to-fine manner. It minimizes the computation overhead while ensuring high performance. Besides, GTPT groups keypoint tokens and prunes visual tokens to improve model performance while reducing redundancy. We propose the Multi-Head Group Attention (MHGA) between different groups to achieve global interaction with little computational overhead. We conducted experiments on COCO and COCO-WholeBody. Compared to other methods, the experimental results show that GTPT can achieve higher performance with less computation, especially in whole-body with numerous keypoints.
Read more7/17/2024
0
MeshPose: Unifying DensePose and 3D Body Mesh reconstruction
Eric-Tuan L^e, Antonis Kakolyris, Petros Koutras, Himmy Tam, Efstratios Skordos, George Papandreou, R{i}za Alp Guler, Iasonas Kokkinos
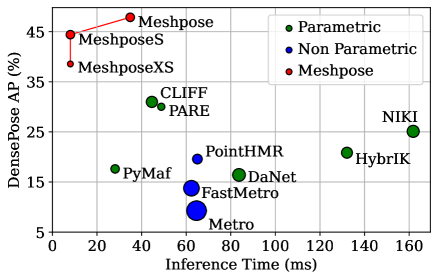
DensePose provides a pixel-accurate association of images with 3D mesh coordinates, but does not provide a 3D mesh, while Human Mesh Reconstruction (HMR) systems have high 2D reprojection error, as measured by DensePose localization metrics. In this work we introduce MeshPose to jointly tackle DensePose and HMR. For this we first introduce new losses that allow us to use weak DensePose supervision to accurately localize in 2D a subset of the mesh vertices ('VertexPose'). We then lift these vertices to 3D, yielding a low-poly body mesh ('MeshPose'). Our system is trained in an end-to-end manner and is the first HMR method to attain competitive DensePose accuracy, while also being lightweight and amenable to efficient inference, making it suitable for real-time AR applications.
Read more6/17/2024
📉
0
Multi-HMR: Multi-Person Whole-Body Human Mesh Recovery in a Single Shot
Fabien Baradel, Matthieu Armando, Salma Galaaoui, Romain Br'egier, Philippe Weinzaepfel, Gr'egory Rogez, Thomas Lucas
We present Multi-HMR, a strong sigle-shot model for multi-person 3D human mesh recovery from a single RGB image. Predictions encompass the whole body, i.e., including hands and facial expressions, using the SMPL-X parametric model and 3D location in the camera coordinate system. Our model detects people by predicting coarse 2D heatmaps of person locations, using features produced by a standard Vision Transformer (ViT) backbone. It then predicts their whole-body pose, shape and 3D location using a new cross-attention module called the Human Prediction Head (HPH), with one query attending to the entire set of features for each detected person. As direct prediction of fine-grained hands and facial poses in a single shot, i.e., without relying on explicit crops around body parts, is hard to learn from existing data, we introduce CUFFS, the Close-Up Frames of Full-Body Subjects dataset, containing humans close to the camera with diverse hand poses. We show that incorporating it into the training data further enhances predictions, particularly for hands. Multi-HMR also optionally accounts for camera intrinsics, if available, by encoding camera ray directions for each image token. This simple design achieves strong performance on whole-body and body-only benchmarks simultaneously: a ViT-S backbone on $448{times}448$ images already yields a fast and competitive model, while larger models and higher resolutions obtain state-of-the-art results.
Read more7/25/2024