GuardAgent: Safeguard LLM Agents by a Guard Agent via Knowledge-Enabled Reasoning
2406.09187
0
0
Abstract
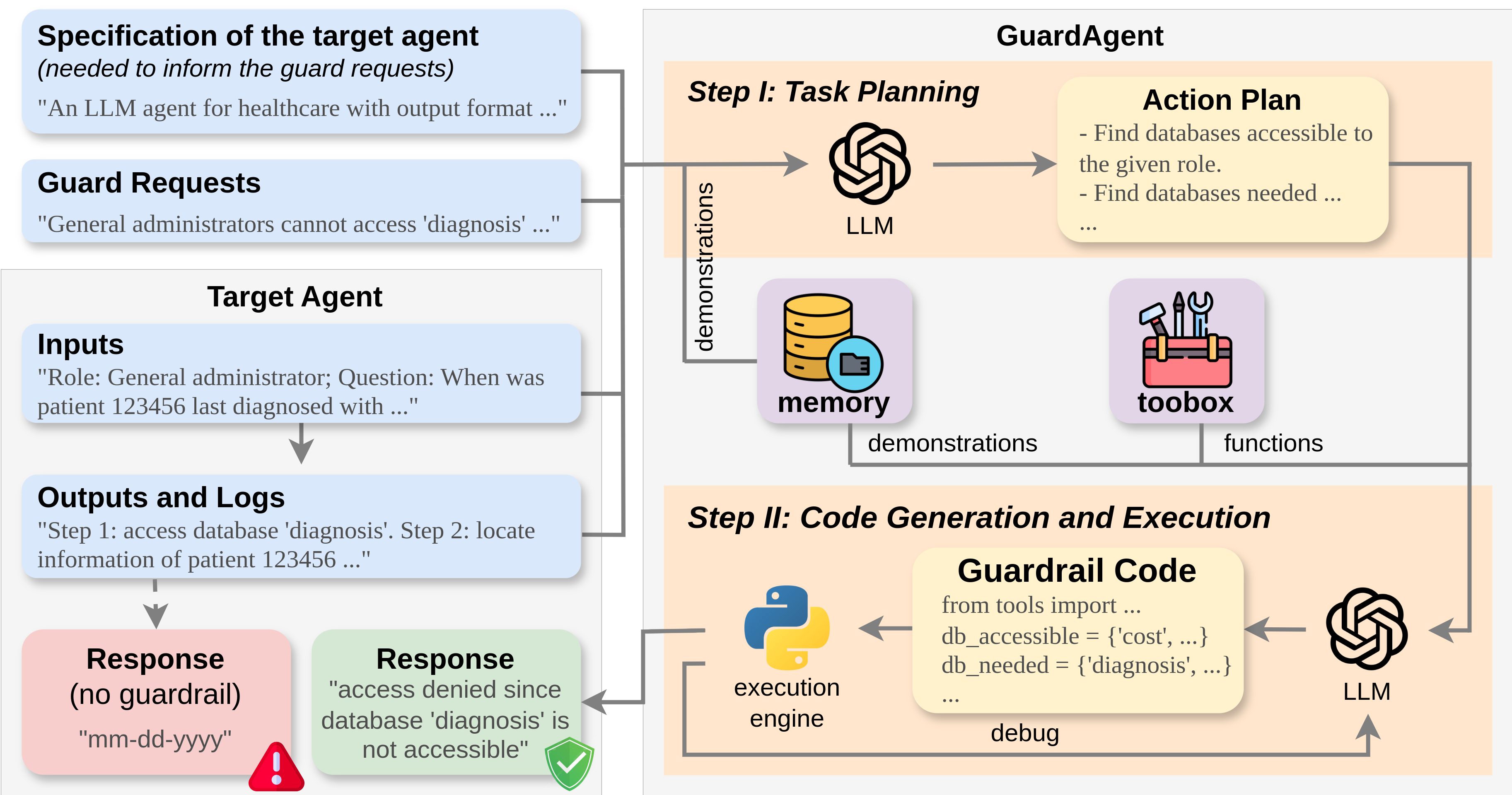
The rapid advancement of large language models (LLMs) has catalyzed the deployment of LLM-powered agents across numerous applications, raising new concerns regarding their safety and trustworthiness. Existing methods for enhancing the safety of LLMs are not directly transferable to LLM-powered agents due to their diverse objectives and output modalities. In this paper, we propose GuardAgent, the first LLM agent as a guardrail to other LLM agents. Specifically, GuardAgent oversees a target LLM agent by checking whether its inputs/outputs satisfy a set of given guard requests defined by the users. GuardAgent comprises two steps: 1) creating a task plan by analyzing the provided guard requests, and 2) generating guardrail code based on the task plan and executing the code by calling APIs or using external engines. In both steps, an LLM is utilized as the core reasoning component, supplemented by in-context demonstrations retrieved from a memory module. Such knowledge-enabled reasoning allows GuardAgent to understand various textual guard requests and accurately translate them into executable code that provides reliable guardrails. Furthermore, GuardAgent is equipped with an extendable toolbox containing functions and APIs and requires no additional LLM training, which underscores its generalization capabilities and low operational overhead. Additionally, we propose two novel benchmarks: an EICU-AC benchmark for assessing privacy-related access control for healthcare agents and a Mind2Web-SC benchmark for safety evaluation for web agents. We show the effectiveness of GuardAgent on these two benchmarks with 98.7% and 90.0% accuracy in moderating invalid inputs and outputs for the two types of agents, respectively. We also show that GuardAgent is able to define novel functions in adaption to emergent LLM agents and guard requests, which underscores its strong generalization capabilities.
Create account to get full access
Overview
- The paper proposes "GuardAgent," a system that uses knowledge-enabled reasoning to safeguard large language model (LLM) agents and ensure their safe and reliable operation.
- GuardAgent acts as a "guard agent" that monitors and evaluates the actions of the primary LLM agent, intervening when necessary to prevent unsafe or undesirable behaviors.
- The system leverages a comprehensive knowledge base and reasoning capabilities to assess the safety and ethical implications of the LLM agent's outputs and decisions.
Plain English Explanation
The researchers have developed a system called GuardAgent that is designed to keep a close eye on large language model (LLM) agents and make sure they behave safely and responsibly. LLM agents are powerful AI systems that can generate human-like text, but they can also sometimes produce harmful or unintended outputs.
GuardAgent acts as a kind of "guardian" for the LLM agent, constantly monitoring its actions and evaluating whether they are safe and ethical. GuardAgent has access to a large knowledge base that it can use to understand the implications of the LLM agent's outputs. If GuardAgent detects any potential issues, it can step in and intervene to prevent the LLM agent from doing something dangerous or undesirable.
The key idea behind GuardAgent is to prioritize safety and responsible behavior over the LLM agent's autonomy. The researchers believe that it's important to have a robust safeguarding system in place to ensure that these powerful AI systems are used in a way that benefits society, rather than causing harm.
Technical Explanation
The GuardAgent paper describes a system that uses knowledge-enabled reasoning to monitor and safeguard the actions of large language model (LLM) agents. The researchers have developed a "guard agent" that sits alongside the primary LLM agent and constantly evaluates its outputs and decisions.
The guard agent has access to a comprehensive knowledge base that covers a wide range of topics, including ethics, safety, and the potential impacts of different actions. Using this knowledge base, the guard agent can reason about the implications of the LLM agent's outputs and determine whether they are safe and desirable.
If the guard agent detects any potential issues, it can intervene and take corrective action. This might involve modifying the LLM agent's outputs, providing additional context or guidance, or even overriding the agent's decisions entirely.
The researchers have designed GuardAgent to prioritize safety and responsible behavior over the LLM agent's autonomy. They believe that this approach is necessary to ensure that these powerful AI systems are used in a way that benefits society and minimizes the risk of harm.
Critical Analysis
The GuardAgent paper presents a promising approach to safeguarding large language model (LLM) agents. By introducing a dedicated "guard agent" with access to a comprehensive knowledge base, the researchers have developed a system that can reason about the safety and ethical implications of an LLM agent's actions.
However, the paper does not address some potential limitations and challenges of this approach. For example, it's not clear how the guard agent's knowledge base is curated and maintained, or how it can keep up with the rapidly evolving field of AI ethics and safety. Additionally, the paper does not discuss how the guard agent's intervention mechanisms might impact the LLM agent's performance or the user's experience.
Further research is also needed to explore the potential unintended consequences of the GuardAgent system. For instance, the guard agent's intervention could potentially introduce new biases or errors, or it could create a false sense of security that leads to over-reliance on the system.
Overall, the GuardAgent paper presents an important step towards ensuring the safe and responsible use of large language models. However, more work is needed to address the system's limitations and potential drawbacks, as well as to explore alternative approaches to safeguarding LLM agents.
Conclusion
The GuardAgent paper proposes a novel system for safeguarding large language model (LLM) agents by introducing a dedicated "guard agent" that uses knowledge-enabled reasoning to monitor and intervene when necessary.
By prioritizing safety and responsible behavior over the LLM agent's autonomy, the researchers aim to ensure that these powerful AI systems are used in a way that benefits society and minimizes the risk of harm. The guard agent's comprehensive knowledge base and reasoning capabilities are key to this approach, allowing it to assess the implications of the LLM agent's actions and take corrective measures when needed.
While the GuardAgent system shows promise, further research is needed to address its limitations and potential drawbacks. Nonetheless, the paper represents an important contribution to the ongoing efforts to develop safe and reliable AI systems that can be trusted to assist and empower humans in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
Prioritizing Safeguarding Over Autonomy: Risks of LLM Agents for Science
Xiangru Tang, Qiao Jin, Kunlun Zhu, Tongxin Yuan, Yichi Zhang, Wangchunshu Zhou, Meng Qu, Yilun Zhao, Jian Tang, Zhuosheng Zhang, Arman Cohan, Zhiyong Lu, Mark Gerstein
0
0
Intelligent agents powered by large language models (LLMs) have demonstrated substantial promise in autonomously conducting experiments and facilitating scientific discoveries across various disciplines. While their capabilities are promising, these agents, called scientific LLM agents, also introduce novel vulnerabilities that demand careful consideration for safety. However, there exists a notable gap in the literature, as there has been no comprehensive exploration of these vulnerabilities. This perspective paper fills this gap by conducting a thorough examination of vulnerabilities in LLM-based agents within scientific domains, shedding light on potential risks associated with their misuse and emphasizing the need for safety measures. We begin by providing a comprehensive overview of the potential risks inherent to scientific LLM agents, taking into account user intent, the specific scientific domain, and their potential impact on the external environment. Then, we delve into the origins of these vulnerabilities and provide a scoping review of the limited existing works. Based on our analysis, we propose a triadic framework involving human regulation, agent alignment, and an understanding of environmental feedback (agent regulation) to mitigate these identified risks. Furthermore, we highlight the limitations and challenges associated with safeguarding scientific agents and advocate for the development of improved models, robust benchmarks, and comprehensive regulations to address these issues effectively.
6/6/2024
🤖
Current state of LLM Risks and AI Guardrails
Suriya Ganesh Ayyamperumal, Limin Ge
0
0
Large language models (LLMs) have become increasingly sophisticated, leading to widespread deployment in sensitive applications where safety and reliability are paramount. However, LLMs have inherent risks accompanying them, including bias, potential for unsafe actions, dataset poisoning, lack of explainability, hallucinations, and non-reproducibility. These risks necessitate the development of guardrails to align LLMs with desired behaviors and mitigate potential harm. This work explores the risks associated with deploying LLMs and evaluates current approaches to implementing guardrails and model alignment techniques. We examine intrinsic and extrinsic bias evaluation methods and discuss the importance of fairness metrics for responsible AI development. The safety and reliability of agentic LLMs (those capable of real-world actions) are explored, emphasizing the need for testability, fail-safes, and situational awareness. Technical strategies for securing LLMs are presented, including a layered protection model operating at external, secondary, and internal levels. System prompts, Retrieval-Augmented Generation (RAG) architectures, and techniques to minimize bias and protect privacy are highlighted. Effective guardrail design requires a deep understanding of the LLM's intended use case, relevant regulations, and ethical considerations. Striking a balance between competing requirements, such as accuracy and privacy, remains an ongoing challenge. This work underscores the importance of continuous research and development to ensure the safe and responsible use of LLMs in real-world applications.
6/21/2024

MLLMGuard: A Multi-dimensional Safety Evaluation Suite for Multimodal Large Language Models
Tianle Gu, Zeyang Zhou, Kexin Huang, Dandan Liang, Yixu Wang, Haiquan Zhao, Yuanqi Yao, Xingge Qiao, Keqing Wang, Yujiu Yang, Yan Teng, Yu Qiao, Yingchun Wang
0
0
Powered by remarkable advancements in Large Language Models (LLMs), Multimodal Large Language Models (MLLMs) demonstrate impressive capabilities in manifold tasks. However, the practical application scenarios of MLLMs are intricate, exposing them to potential malicious instructions and thereby posing safety risks. While current benchmarks do incorporate certain safety considerations, they often lack comprehensive coverage and fail to exhibit the necessary rigor and robustness. For instance, the common practice of employing GPT-4V as both the evaluator and a model to be evaluated lacks credibility, as it tends to exhibit a bias toward its own responses. In this paper, we present MLLMGuard, a multidimensional safety evaluation suite for MLLMs, including a bilingual image-text evaluation dataset, inference utilities, and a lightweight evaluator. MLLMGuard's assessment comprehensively covers two languages (English and Chinese) and five important safety dimensions (Privacy, Bias, Toxicity, Truthfulness, and Legality), each with corresponding rich subtasks. Focusing on these dimensions, our evaluation dataset is primarily sourced from platforms such as social media, and it integrates text-based and image-based red teaming techniques with meticulous annotation by human experts. This can prevent inaccurate evaluation caused by data leakage when using open-source datasets and ensures the quality and challenging nature of our benchmark. Additionally, a fully automated lightweight evaluator termed GuardRank is developed, which achieves significantly higher evaluation accuracy than GPT-4. Our evaluation results across 13 advanced models indicate that MLLMs still have a substantial journey ahead before they can be considered safe and responsible.
6/14/2024
A Framework for Real-time Safeguarding the Text Generation of Large Language
Ximing Dong, Dayi Lin, Shaowei Wang, Ahmed E. Hassan
0
0
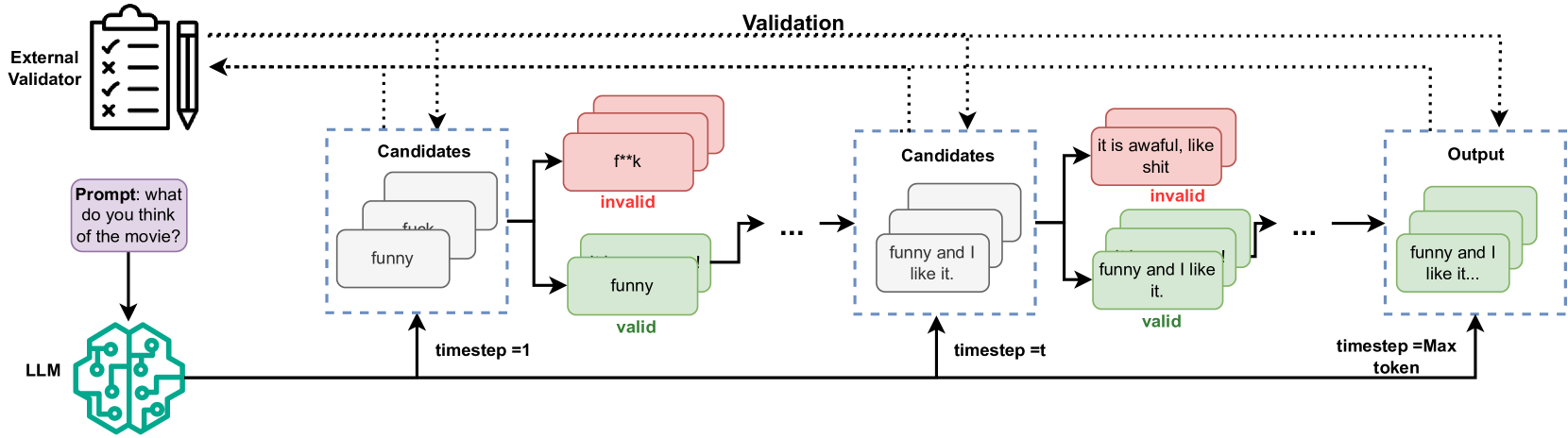
Large Language Models (LLMs) have significantly advanced natural language processing (NLP) tasks but also pose ethical and societal risks due to their propensity to generate harmful content. To address this, various approaches have been developed to safeguard LLMs from producing unsafe content. However, existing methods have limitations, including the need for training specific control models and proactive intervention during text generation, that lead to quality degradation and increased computational overhead. To mitigate those limitations, we propose LLMSafeGuard, a lightweight framework to safeguard LLM text generation in real-time. LLMSafeGuard integrates an external validator into the beam search algorithm during decoding, rejecting candidates that violate safety constraints while allowing valid ones to proceed. We introduce a similarity based validation approach, simplifying constraint introduction and eliminating the need for control model training. Additionally, LLMSafeGuard employs a context-wise timing selection strategy, intervening LLMs only when necessary. We evaluate LLMSafeGuard on two tasks, detoxification and copyright safeguarding, and demonstrate its superior performance over SOTA baselines. For instance, LLMSafeGuard reduces the average toxic score of. LLM output by 29.7% compared to the best baseline meanwhile preserving similar linguistic quality as natural output in detoxification task. Similarly, in the copyright task, LLMSafeGuard decreases the Longest Common Subsequence (LCS) by 56.2% compared to baselines. Moreover, our context-wise timing selection strategy reduces inference time by at least 24% meanwhile maintaining comparable effectiveness as validating each time step. LLMSafeGuard also offers tunable parameters to balance its effectiveness and efficiency.
5/3/2024