Prioritizing Safeguarding Over Autonomy: Risks of LLM Agents for Science
2402.04247
0
0
🤷
Abstract
Intelligent agents powered by large language models (LLMs) have demonstrated substantial promise in autonomously conducting experiments and facilitating scientific discoveries across various disciplines. While their capabilities are promising, these agents, called scientific LLM agents, also introduce novel vulnerabilities that demand careful consideration for safety. However, there exists a notable gap in the literature, as there has been no comprehensive exploration of these vulnerabilities. This perspective paper fills this gap by conducting a thorough examination of vulnerabilities in LLM-based agents within scientific domains, shedding light on potential risks associated with their misuse and emphasizing the need for safety measures. We begin by providing a comprehensive overview of the potential risks inherent to scientific LLM agents, taking into account user intent, the specific scientific domain, and their potential impact on the external environment. Then, we delve into the origins of these vulnerabilities and provide a scoping review of the limited existing works. Based on our analysis, we propose a triadic framework involving human regulation, agent alignment, and an understanding of environmental feedback (agent regulation) to mitigate these identified risks. Furthermore, we highlight the limitations and challenges associated with safeguarding scientific agents and advocate for the development of improved models, robust benchmarks, and comprehensive regulations to address these issues effectively.
Create account to get full access
Overview
- Large language models (LLMs) have shown great potential in autonomously conducting experiments and making scientific discoveries across various fields.
- However, these scientific LLM agents also introduce new vulnerabilities that require careful consideration for safety.
- The literature has lacked a comprehensive exploration of these vulnerabilities, which this perspective paper aims to address.
Plain English Explanation
This paper examines the potential risks and vulnerabilities associated with using large language models (LLMs) as autonomous agents in scientific research. LLMs are powerful machine learning models that can generate human-like text and perform a variety of tasks. When used as "scientific LLM agents," these models have shown promise in autonomously conducting experiments and making discoveries across different scientific disciplines.
However, the use of these agents also introduces new vulnerabilities that need to be addressed. For example, if an LLM agent is not properly aligned with human values and goals, it could misuse its capabilities in ways that are harmful or unintended. The paper aims to fill the gap in the existing literature by providing a thorough examination of these vulnerabilities and proposing a framework to mitigate the associated risks.
Technical Explanation
The paper begins by providing a comprehensive overview of the potential risks inherent to scientific LLM agents. These risks can arise from various factors, such as the user's intent, the specific scientific domain, and the potential impact on the external environment. The authors then delve into the origins of these vulnerabilities and provide a review of the limited existing works in this area.
Based on their analysis, the authors propose a triadic framework to mitigate the identified risks. This framework involves three key elements:
-
Human regulation: Ensuring that human operators and stakeholders have appropriate oversight and control over the deployment and use of scientific LLM agents.
-
Agent alignment: Designing the LLM agents to be aligned with human values and goals, reducing the risk of unintended or harmful behavior.
-
Environmental feedback: Developing a comprehensive understanding of how the LLM agents interact with and impact the external environment, allowing for real-time monitoring and adjustment of their behavior.
The paper also highlights the limitations and challenges associated with safeguarding scientific agents, and advocates for the development of improved models, robust benchmarks, and comprehensive regulations to address these issues effectively.
Critical Analysis
The paper provides a valuable contribution to the ongoing discussion around the safety and responsible development of LLM-based autonomous agents in scientific domains. By identifying and examining the potential vulnerabilities of these agents, the authors have laid the groundwork for a more proactive and rigorous approach to AI safety in this context.
However, the paper also acknowledges the inherent complexity and challenges involved in addressing these vulnerabilities. Developing effective human regulation, agent alignment, and environmental feedback mechanisms will require significant research, technological advancements, and cross-disciplinary collaboration. The authors rightly highlight the need for improved models, robust benchmarks, and comprehensive regulations to tackle these issues effectively.
Additionally, the paper could have delved deeper into specific use cases or scenarios where the vulnerabilities of scientific LLM agents could manifest, providing more concrete examples to illustrate the potential risks and the necessity of the proposed framework.
Conclusion
This perspective paper offers a comprehensive examination of the vulnerabilities associated with the use of large language models as autonomous agents in scientific research. By proposing a triadic framework to mitigate these risks, the authors have made a significant contribution to the ongoing efforts to ensure the safe and responsible development of AI-powered scientific discovery.
As the capabilities of LLMs continue to evolve, it is crucial that the research community and policymakers work together to address the challenges identified in this paper, ultimately enabling the beneficial deployment of these powerful tools while safeguarding against potential misuse or unintended consequences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
Current state of LLM Risks and AI Guardrails
Suriya Ganesh Ayyamperumal, Limin Ge
0
0
Large language models (LLMs) have become increasingly sophisticated, leading to widespread deployment in sensitive applications where safety and reliability are paramount. However, LLMs have inherent risks accompanying them, including bias, potential for unsafe actions, dataset poisoning, lack of explainability, hallucinations, and non-reproducibility. These risks necessitate the development of guardrails to align LLMs with desired behaviors and mitigate potential harm. This work explores the risks associated with deploying LLMs and evaluates current approaches to implementing guardrails and model alignment techniques. We examine intrinsic and extrinsic bias evaluation methods and discuss the importance of fairness metrics for responsible AI development. The safety and reliability of agentic LLMs (those capable of real-world actions) are explored, emphasizing the need for testability, fail-safes, and situational awareness. Technical strategies for securing LLMs are presented, including a layered protection model operating at external, secondary, and internal levels. System prompts, Retrieval-Augmented Generation (RAG) architectures, and techniques to minimize bias and protect privacy are highlighted. Effective guardrail design requires a deep understanding of the LLM's intended use case, relevant regulations, and ethical considerations. Striking a balance between competing requirements, such as accuracy and privacy, remains an ongoing challenge. This work underscores the importance of continuous research and development to ensure the safe and responsible use of LLMs in real-world applications.
6/21/2024
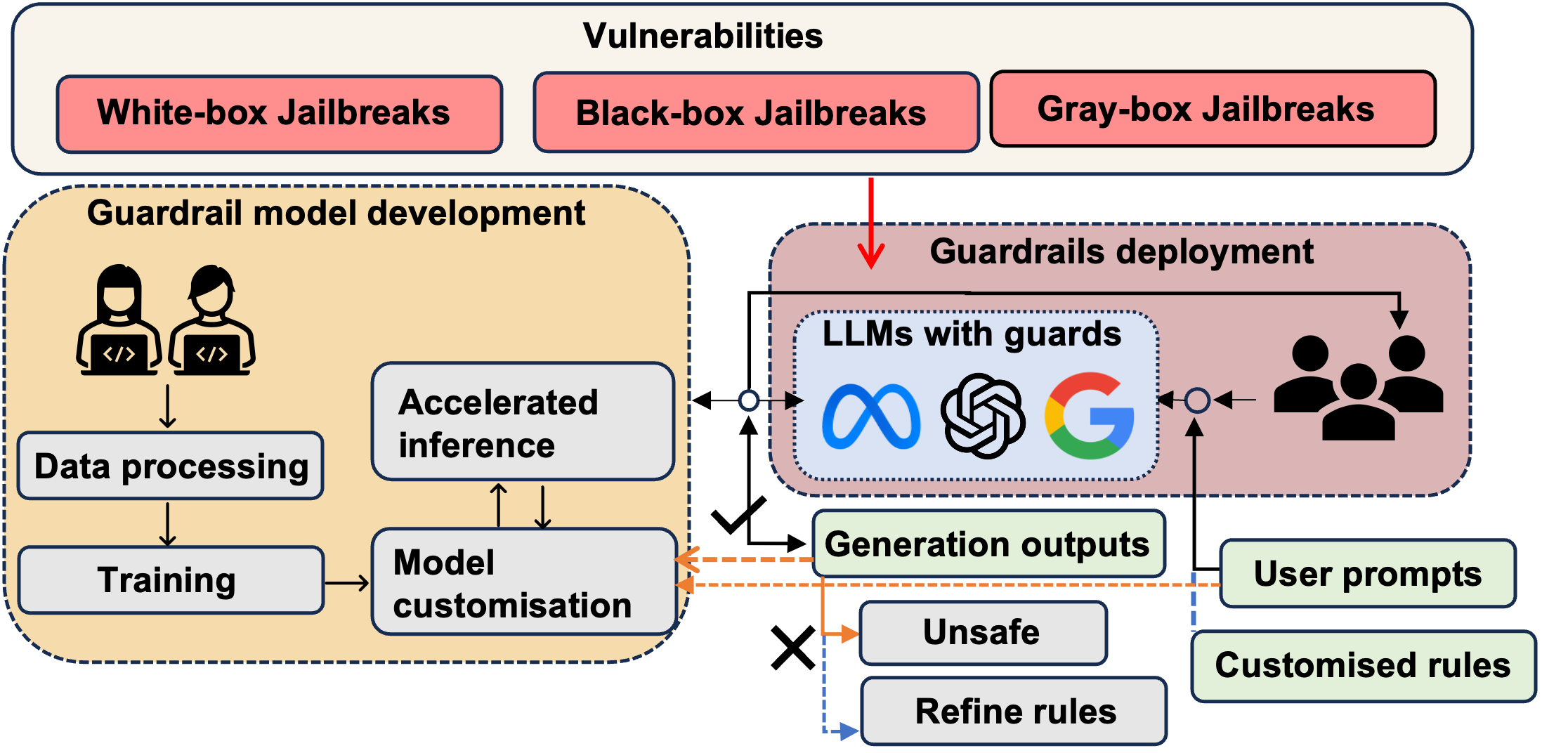
Safeguarding Large Language Models: A Survey
Yi Dong, Ronghui Mu, Yanghao Zhang, Siqi Sun, Tianle Zhang, Changshun Wu, Gaojie Jin, Yi Qi, Jinwei Hu, Jie Meng, Saddek Bensalem, Xiaowei Huang
0
0
In the burgeoning field of Large Language Models (LLMs), developing a robust safety mechanism, colloquially known as safeguards or guardrails, has become imperative to ensure the ethical use of LLMs within prescribed boundaries. This article provides a systematic literature review on the current status of this critical mechanism. It discusses its major challenges and how it can be enhanced into a comprehensive mechanism dealing with ethical issues in various contexts. First, the paper elucidates the current landscape of safeguarding mechanisms that major LLM service providers and the open-source community employ. This is followed by the techniques to evaluate, analyze, and enhance some (un)desirable properties that a guardrail might want to enforce, such as hallucinations, fairness, privacy, and so on. Based on them, we review techniques to circumvent these controls (i.e., attacks), to defend the attacks, and to reinforce the guardrails. While the techniques mentioned above represent the current status and the active research trends, we also discuss several challenges that cannot be easily dealt with by the methods and present our vision on how to implement a comprehensive guardrail through the full consideration of multi-disciplinary approach, neural-symbolic method, and systems development lifecycle.
6/6/2024
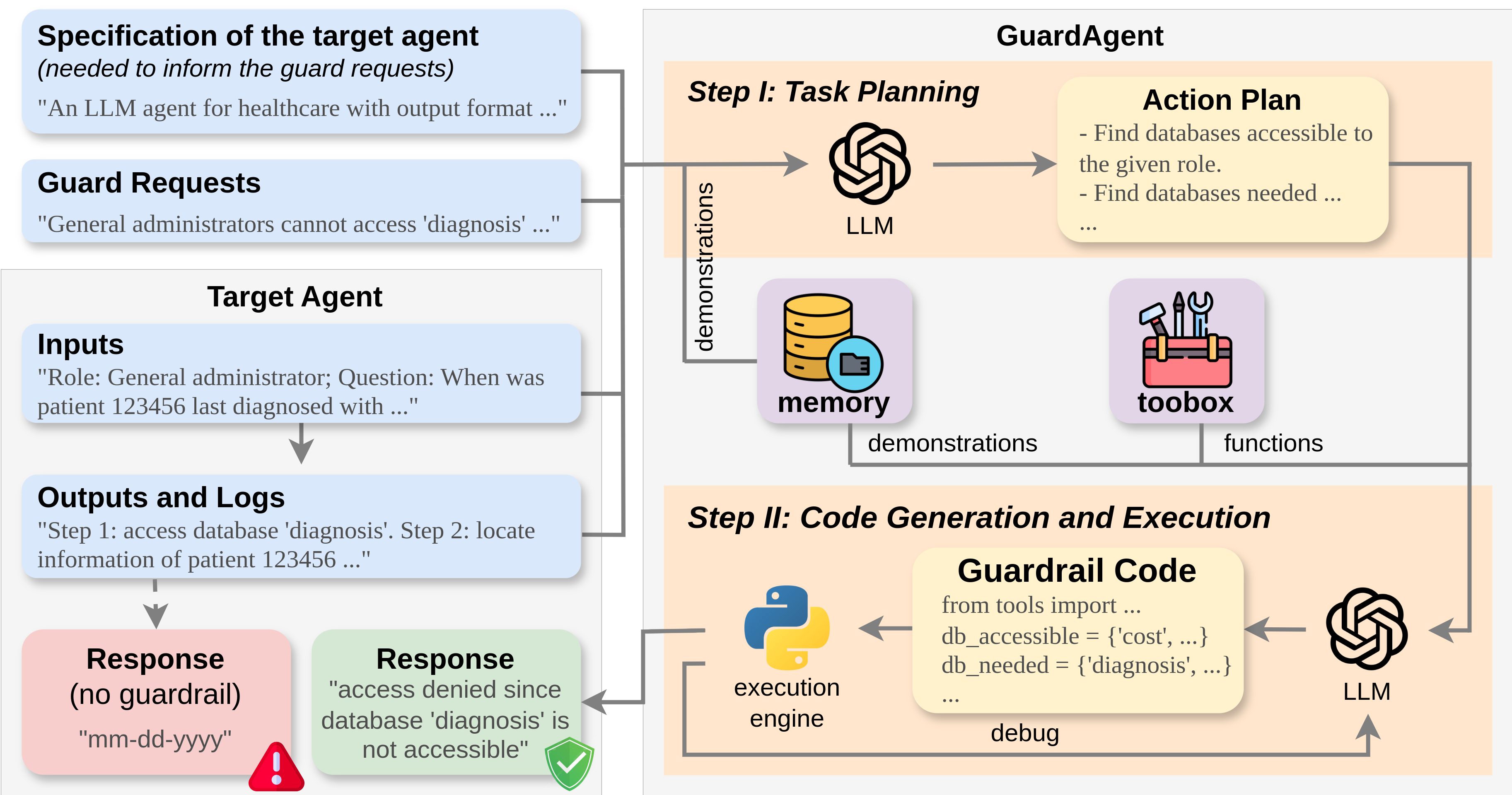
GuardAgent: Safeguard LLM Agents by a Guard Agent via Knowledge-Enabled Reasoning
Zhen Xiang, Linzhi Zheng, Yanjie Li, Junyuan Hong, Qinbin Li, Han Xie, Jiawei Zhang, Zidi Xiong, Chulin Xie, Carl Yang, Dawn Song, Bo Li
0
0
The rapid advancement of large language models (LLMs) has catalyzed the deployment of LLM-powered agents across numerous applications, raising new concerns regarding their safety and trustworthiness. Existing methods for enhancing the safety of LLMs are not directly transferable to LLM-powered agents due to their diverse objectives and output modalities. In this paper, we propose GuardAgent, the first LLM agent as a guardrail to other LLM agents. Specifically, GuardAgent oversees a target LLM agent by checking whether its inputs/outputs satisfy a set of given guard requests defined by the users. GuardAgent comprises two steps: 1) creating a task plan by analyzing the provided guard requests, and 2) generating guardrail code based on the task plan and executing the code by calling APIs or using external engines. In both steps, an LLM is utilized as the core reasoning component, supplemented by in-context demonstrations retrieved from a memory module. Such knowledge-enabled reasoning allows GuardAgent to understand various textual guard requests and accurately translate them into executable code that provides reliable guardrails. Furthermore, GuardAgent is equipped with an extendable toolbox containing functions and APIs and requires no additional LLM training, which underscores its generalization capabilities and low operational overhead. Additionally, we propose two novel benchmarks: an EICU-AC benchmark for assessing privacy-related access control for healthcare agents and a Mind2Web-SC benchmark for safety evaluation for web agents. We show the effectiveness of GuardAgent on these two benchmarks with 98.7% and 90.0% accuracy in moderating invalid inputs and outputs for the two types of agents, respectively. We also show that GuardAgent is able to define novel functions in adaption to emergent LLM agents and guard requests, which underscores its strong generalization capabilities.
6/14/2024
Exploring Autonomous Agents through the Lens of Large Language Models: A Review
Saikat Barua
0
0
Large Language Models (LLMs) are transforming artificial intelligence, enabling autonomous agents to perform diverse tasks across various domains. These agents, proficient in human-like text comprehension and generation, have the potential to revolutionize sectors from customer service to healthcare. However, they face challenges such as multimodality, human value alignment, hallucinations, and evaluation. Techniques like prompting, reasoning, tool utilization, and in-context learning are being explored to enhance their capabilities. Evaluation platforms like AgentBench, WebArena, and ToolLLM provide robust methods for assessing these agents in complex scenarios. These advancements are leading to the development of more resilient and capable autonomous agents, anticipated to become integral in our digital lives, assisting in tasks from email responses to disease diagnosis. The future of AI, with LLMs at the forefront, is promising.
4/9/2024