Guidance-Based Prompt Data Augmentation in Specialized Domains for Named Entity Recognition

0
Sign in to get full access
Overview
- Explores a novel data augmentation technique for Named Entity Recognition (NER) in specialized domains
- Uses guidance-based prompts to generate synthetic training data that captures the nuances of the target domain
- Demonstrates improved NER performance compared to standard data augmentation methods
Plain English Explanation
The researchers developed a new way to boost the performance of Named Entity Recognition (NER) models in specialized domains. NER is the task of identifying and classifying important entities like people, organizations, and locations in text.
Oftentimes, NER models trained on general-purpose data struggle to perform well on specialized domains like medical or legal texts. This is because the language and the types of entities in these domains can be quite different from the data the models were originally trained on.
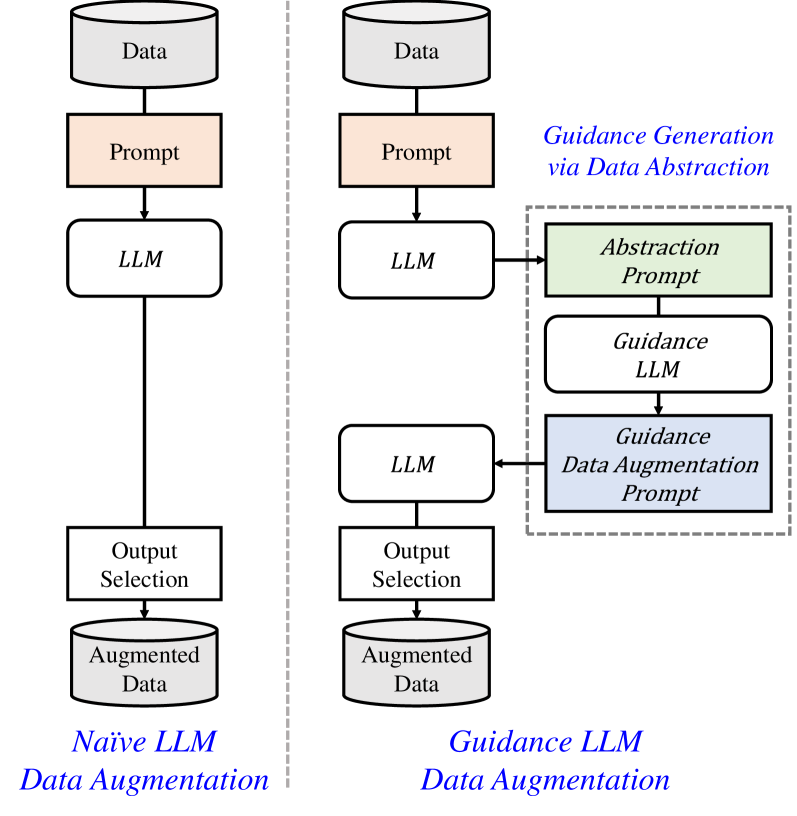
To address this, the researchers used a technique called guidance-based prompt data augmentation. This involves generating new synthetic training examples by modifying existing examples using language models that have been "guided" to produce text matching the target domain.
By creating these synthetic examples, the researchers were able to expand the diversity of the training data in a way that better captured the nuances of the specialized domain. This led to significant improvements in the NER model's performance compared to standard data augmentation techniques.
The key insight is that carefully crafting the prompts used to generate the synthetic data can help the model learn the right patterns and features for the specialized task at hand. This guidance-based approach is a powerful way to enhance the capabilities of NER systems in domains where labeled data is scarce.
Technical Explanation
The paper proposes a guidance-based prompt data augmentation technique to improve Named Entity Recognition (NER) performance in specialized domains.
The authors first fine-tune a pre-trained language model on a small amount of domain-specific text to capture the linguistic characteristics of the target domain. They then use this fine-tuned model to generate synthetic training examples by modifying existing examples through prompting.
The key insight is that the fine-tuned language model can be "guided" to produce text that matches the target domain, resulting in synthetic examples that are more representative of the specialized data. This is in contrast to standard data augmentation methods that may not capture the nuances of the target domain as effectively.
The authors evaluate their approach on NER tasks in the medical and legal domains, demonstrating significant improvements over baseline methods. They also provide detailed ablation studies to understand the impact of different components of their approach.
Overall, the guidance-based prompt data augmentation technique offers a promising way to enhance the performance of NER models in specialized domains where labeled data is scarce.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed guidance-based prompt data augmentation approach for NER in specialized domains. The authors acknowledge several limitations and areas for future research, such as the need to explore more diverse target domains and to investigate the impact of the seed dataset size on the effectiveness of the approach.
One potential concern is the computational cost of the fine-tuning process required to adapt the language model to the target domain. This may limit the scalability of the approach, especially for resource-constrained settings. The authors could have discussed strategies to mitigate this, such as efficient fine-tuning techniques or the use of smaller, more specialized language models.
Additionally, the paper could have delved deeper into the qualitative analysis of the generated synthetic examples to better understand the types of linguistic patterns and entity types that the approach is able to capture. This could provide valuable insights for further improving the technique.
Overall, the guidance-based prompt data augmentation method represents a promising direction for enhancing NER performance in specialized domains, and the paper serves as a solid foundation for future research in this area.
Conclusion
The researchers introduced a novel guidance-based prompt data augmentation technique to improve Named Entity Recognition (NER) in specialized domains. By fine-tuning a language model on domain-specific text and using it to generate synthetic training examples, they were able to significantly boost NER performance compared to standard data augmentation methods.
This work highlights the importance of leveraging domain-specific knowledge and language modeling capabilities to overcome the challenges of limited labeled data in specialized tasks like NER. The guidance-based prompt data augmentation approach offers a promising direction for enhancing the performance and robustness of NER systems in a wide range of real-world applications, from medical informatics to legal document processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Guidance-Based Prompt Data Augmentation in Specialized Domains for Named Entity Recognition
Hyeonseok Kang, Hyein Seo, Jeesu Jung, Sangkeun Jung, Du-Seong Chang, Riwoo Chung
While the abundance of rich and vast datasets across numerous fields has facilitated the advancement of natural language processing, sectors in need of specialized data types continue to struggle with the challenge of finding quality data. Our study introduces a novel guidance data augmentation technique utilizing abstracted context and sentence structures to produce varied sentences while maintaining context-entity relationships, addressing data scarcity challenges. By fostering a closer relationship between context, sentence structure, and role of entities, our method enhances data augmentation's effectiveness. Consequently, by showcasing diversification in both entity-related vocabulary and overall sentence structure, and simultaneously improving the training performance of named entity recognition task.
Read more7/29/2024

0
Knowledge-Based Domain-Oriented Data Augmentation for Enhancing Unsupervised Sentence Embedding
Peichao Lai, Zhengfeng Zhang, Bin Cui
Recently, unsupervised sentence embedding models have received significant attention in downstream natural language processing tasks. Using large language models (LLMs) for data augmentation has led to considerable improvements in previous studies. Nevertheless, these strategies emphasize data augmentation with extensive generic corpora, neglecting the consideration of few-shot domain data. The synthesized data lacks fine-grained information and may introduce negative sample noise. This study introduces a novel pipeline-based data augmentation method that leverages LLM to synthesize the domain-specific dataset. It produces both positive and negative samples through entity- and quantity-aware augmentation, utilizing an entity knowledge graph to synthesize samples with fine-grained semantic distinctions, increasing training sample diversity and relevance. We then present a Gaussian-decayed gradient-assisted Contrastive Sentence Embedding (GCSE) model to reduce synthetic data noise and improve model discrimination to reduce negative sample noise. Experimental results demonstrate that our approach achieves state-of-the-art semantic textual similarity performance with fewer synthetic data samples and lesser LLM parameters, demonstrating its efficiency and robustness in varied backbones.
Read more9/20/2024
⛏️
0
Targeted Augmentation for Low-Resource Event Extraction
Sijia Wang, Lifu Huang
Addressing the challenge of low-resource information extraction remains an ongoing issue due to the inherent information scarcity within limited training examples. Existing data augmentation methods, considered potential solutions, struggle to strike a balance between weak augmentation (e.g., synonym augmentation) and drastic augmentation (e.g., conditional generation without proper guidance). This paper introduces a novel paradigm that employs targeted augmentation and back validation to produce augmented examples with enhanced diversity, polarity, accuracy, and coherence. Extensive experimental results demonstrate the effectiveness of the proposed paradigm. Furthermore, identified limitations are discussed, shedding light on areas for future improvement.
Read more5/15/2024
🛠️
0
APrompt4EM: Augmented Prompt Tuning for Generalized Entity Matching
Yikuan Xia, Jiazun Chen, Xinchi Li, Jun Gao
Generalized Entity Matching (GEM), which aims at judging whether two records represented in different formats refer to the same real-world entity, is an essential task in data management. The prompt tuning paradigm for pre-trained language models (PLMs), including the recent PromptEM model, effectively addresses the challenges of low-resource GEM in practical applications, offering a robust solution when labeled data is scarce. However, existing prompt tuning models for GEM face the challenges of prompt design and information gap. This paper introduces an augmented prompt tuning framework for the challenges, which consists of two main improvements. The first is an augmented contextualized soft token-based prompt tuning method that extracts a guiding soft token benefit for the PLMs' prompt tuning, and the second is a cost-effective information augmentation strategy leveraging large language models (LLMs). Our approach performs well on the low-resource GEM challenges. Extensive experiments show promising advancements of our basic model without information augmentation over existing methods based on moderate-size PLMs (average 5.24%+), and our model with information augmentation achieves comparable performance compared with fine-tuned LLMs, using less than 14% of the API fee.
Read more5/9/2024