Robust Guidance for Unsupervised Data Selection: Capturing Perplexing Named Entities for Domain-Specific Machine Translation

0
Sign in to get full access
Overview
- This paper focuses on improving machine translation performance in specialized domains by developing a robust approach for selecting relevant training data.
- The authors propose a method to identify and capture "perplexing" named entities that are challenging for machine translation models, particularly in technical or domain-specific contexts.
- By incorporating these challenging named entities into the training data, the authors aim to enhance the model's ability to translate specialized vocabulary and improve overall translation quality.
Plain English Explanation
Machine translation models, which convert text from one language to another, often struggle when dealing with specialized or technical vocabulary. This is because the training data they are exposed to during the model's development may not cover the full breadth of terminology used in specialized domains.
To address this challenge, the authors of this paper have developed a technique to identify and include the most "perplexing" named entities - proper nouns like people, places, or organizations - in the training data. These are the terms that tend to be the most difficult for the model to translate accurately.
By ensuring the model is exposed to these challenging named entities during training, the authors aim to improve the overall quality of the machine translations, particularly in specialized or technical contexts. This could be helpful for applications like cost-efficient prompt engineering for unsupervised entity resolution or leveraging contextual information for effective entity salience detection.
Technical Explanation
The paper proposes a novel approach for selecting training data to enhance the performance of domain-specific machine translation models. The key components of their method are:
-
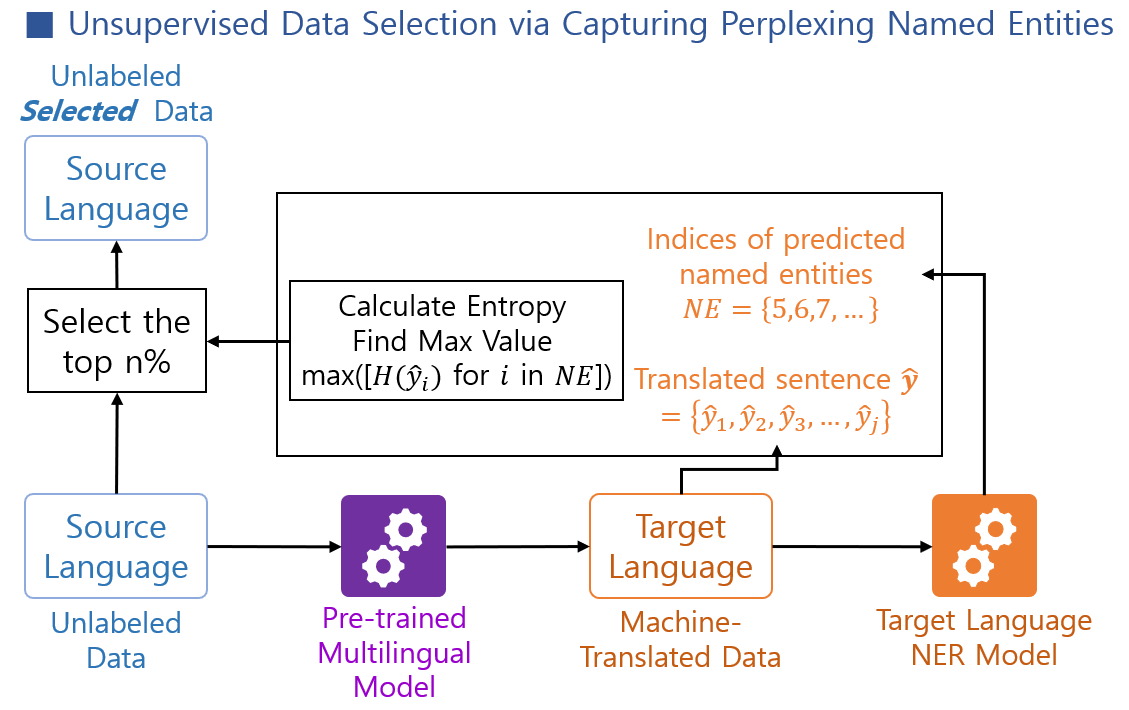
Perplexity-based Named Entity Identification: The authors use a language model to calculate the perplexity (a measure of how surprising or uncertain the model is about a given token) of named entities in the training data. Named entities with high perplexity are considered "perplexing" and are prioritized for inclusion in the final training dataset.
-
Unsupervised Data Selection: To build the final training dataset, the authors employ an unsupervised data selection approach inspired by TextGram and GET-MORE. This allows them to capture a diverse set of relevant sentences while minimizing redundancy.
-
Domain-Specific Evaluation: The authors evaluate their approach on domain-specific machine translation tasks, demonstrating significant improvements in translation quality compared to baseline methods, particularly for low-resource named entity recognition in cross-lingual settings.
Critical Analysis
The authors acknowledge that their approach relies on the availability of a pre-trained language model, which may not always be the case, especially for low-resource languages or specialized domains. Additionally, the perplexity-based named entity identification could be sensitive to the quality and coverage of the language model used.
Further research could explore alternative techniques for identifying challenging named entities, such as leveraging domain-specific dictionaries or utilizing contextual information. Evaluating the approach on a broader range of domains and language pairs would also help validate its robustness.
Conclusion
This paper presents a promising approach for improving the performance of domain-specific machine translation models by selectively incorporating challenging named entities into the training data. By focusing on these perplexing terms, the authors demonstrate that it is possible to enhance the model's ability to handle specialized vocabulary, which is crucial for many real-world applications. The findings of this research could have a significant impact on the development of more accurate and reliable machine translation systems, particularly in technical or domain-specific contexts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Robust Guidance for Unsupervised Data Selection: Capturing Perplexing Named Entities for Domain-Specific Machine Translation
Seunghyun Ji, Hagai Raja Sinulingga, Darongsae Kwon
Low-resourced data presents a significant challenge for neural machine translation. In most cases, the low-resourced environment is caused by high costs due to the need for domain experts or the lack of language experts. Therefore, identifying the most training-efficient data within an unsupervised setting emerges as a practical strategy. Recent research suggests that such effective data can be identified by selecting 'appropriately complex data' based on its volume, providing strong intuition for unsupervised data selection. However, we have discovered that establishing criteria for unsupervised data selection remains a challenge, as the 'appropriate level of difficulty' may vary depending on the data domain. We introduce a novel unsupervised data selection method named 'Capturing Perplexing Named Entities,' which leverages the maximum inference entropy in translated named entities as a metric for selection. When tested with the 'Korean-English Parallel Corpus of Specialized Domains,' our method served as robust guidance for identifying training-efficient data across different domains, in contrast to existing methods.
Read more5/22/2024
0
A Survey on Data Selection for Language Models
Alon Albalak, Yanai Elazar, Sang Michael Xie, Shayne Longpre, Nathan Lambert, Xinyi Wang, Niklas Muennighoff, Bairu Hou, Liangming Pan, Haewon Jeong, Colin Raffel, Shiyu Chang, Tatsunori Hashimoto, William Yang Wang
A major factor in the recent success of large language models is the use of enormous and ever-growing text datasets for unsupervised pre-training. However, naively training a model on all available data may not be optimal (or feasible), as the quality of available text data can vary. Filtering out data can also decrease the carbon footprint and financial costs of training models by reducing the amount of training required. Data selection methods aim to determine which candidate data points to include in the training dataset and how to appropriately sample from the selected data points. The promise of improved data selection methods has caused the volume of research in the area to rapidly expand. However, because deep learning is mostly driven by empirical evidence and experimentation on large-scale data is expensive, few organizations have the resources for extensive data selection research. Consequently, knowledge of effective data selection practices has become concentrated within a few organizations, many of which do not openly share their findings and methodologies. To narrow this gap in knowledge, we present a comprehensive review of existing literature on data selection methods and related research areas, providing a taxonomy of existing approaches. By describing the current landscape of research, this work aims to accelerate progress in data selection by establishing an entry point for new and established researchers. Additionally, throughout this review we draw attention to noticeable holes in the literature and conclude the paper by proposing promising avenues for future research.
Read more8/6/2024
0
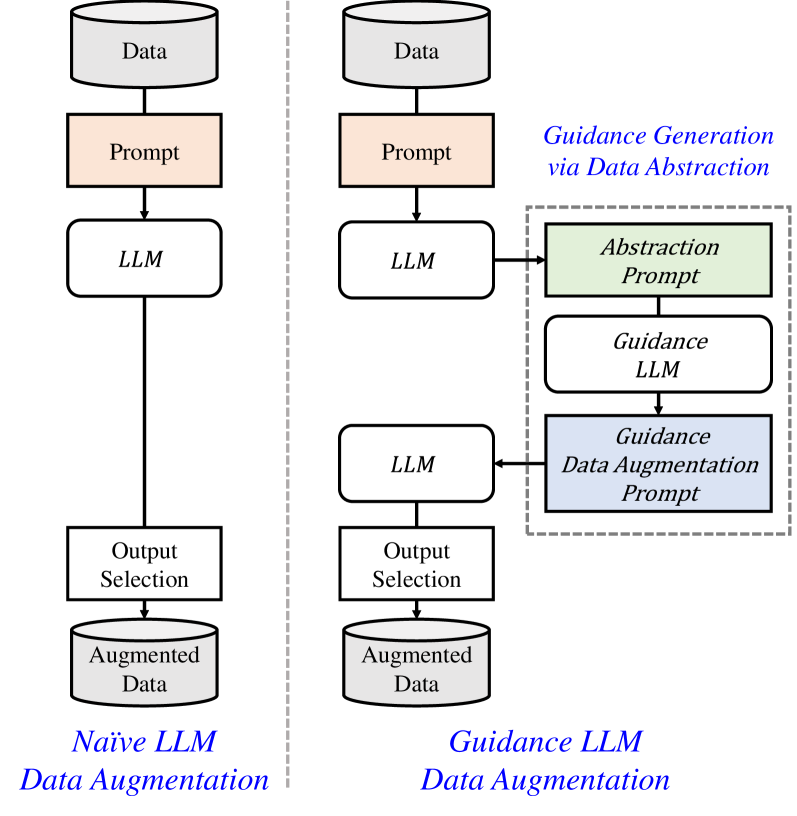
Guidance-Based Prompt Data Augmentation in Specialized Domains for Named Entity Recognition
Hyeonseok Kang, Hyein Seo, Jeesu Jung, Sangkeun Jung, Du-Seong Chang, Riwoo Chung
While the abundance of rich and vast datasets across numerous fields has facilitated the advancement of natural language processing, sectors in need of specialized data types continue to struggle with the challenge of finding quality data. Our study introduces a novel guidance data augmentation technique utilizing abstracted context and sentence structures to produce varied sentences while maintaining context-entity relationships, addressing data scarcity challenges. By fostering a closer relationship between context, sentence structure, and role of entities, our method enhances data augmentation's effectiveness. Consequently, by showcasing diversification in both entity-related vocabulary and overall sentence structure, and simultaneously improving the training performance of named entity recognition task.
Read more7/29/2024
0
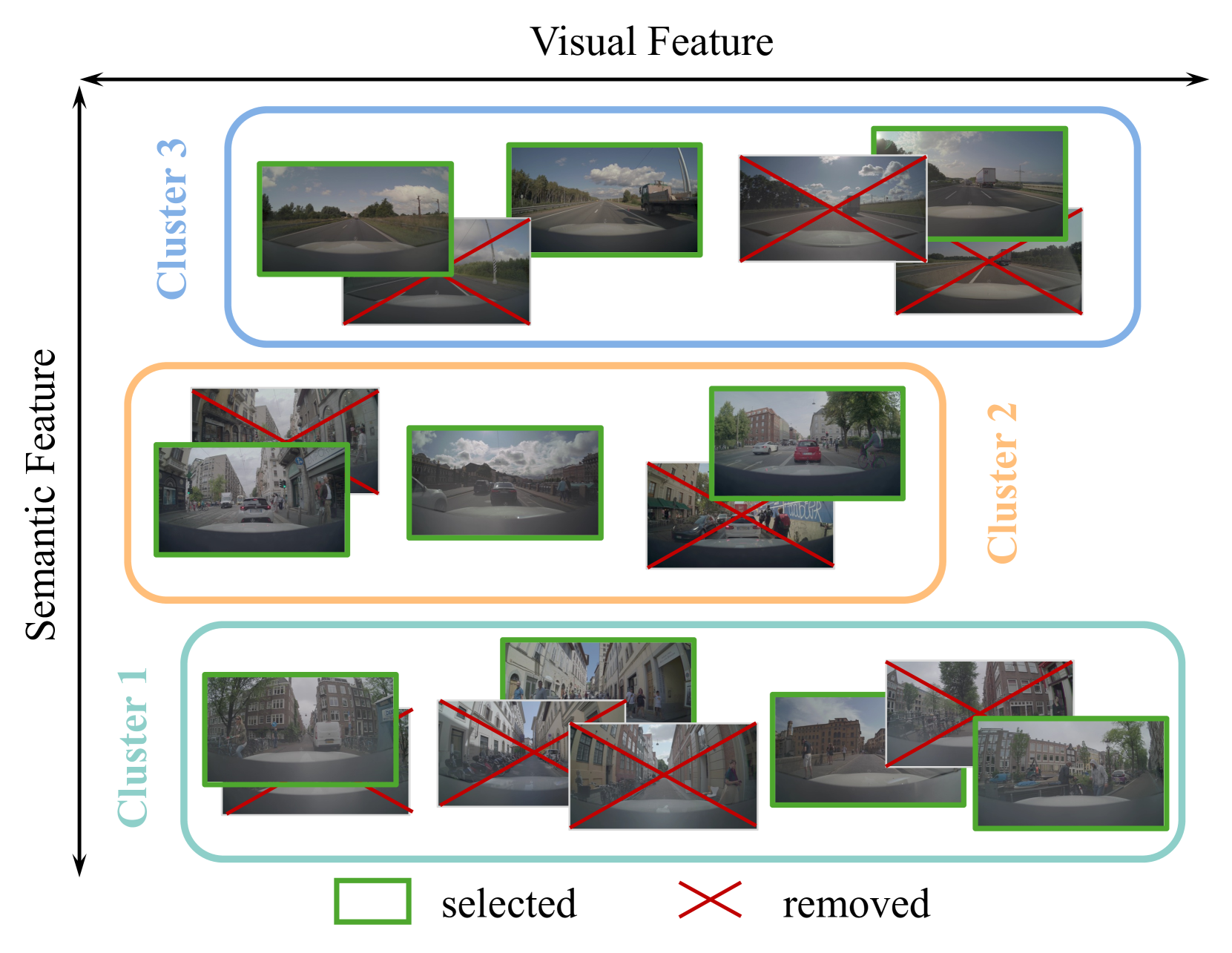
SSE: Multimodal Semantic Data Selection and Enrichment for Industrial-scale Data Assimilation
Maying Shen, Nadine Chang, Sifei Liu, Jose M. Alvarez
In recent years, the data collected for artificial intelligence has grown to an unmanageable amount. Particularly within industrial applications, such as autonomous vehicles, model training computation budgets are being exceeded while model performance is saturating -- and yet more data continues to pour in. To navigate the flood of data, we propose a framework to select the most semantically diverse and important dataset portion. Then, we further semantically enrich it by discovering meaningful new data from a massive unlabeled data pool. Importantly, we can provide explainability by leveraging foundation models to generate semantics for every data point. We quantitatively show that our Semantic Selection and Enrichment framework (SSE) can a) successfully maintain model performance with a smaller training dataset and b) improve model performance by enriching the smaller dataset without exceeding the original dataset size. Consequently, we demonstrate that semantic diversity is imperative for optimal data selection and model performance.
Read more9/24/2024