Guided Interpretable Facial Expression Recognition via Spatial Action Unit Cues

0

Sign in to get full access
Overview
- The paper introduces a guided interpretable facial expression recognition (FER) model that leverages spatial action unit (AU) cues.
- The model aims to provide interpretable and explainable predictions by focusing on the relevant facial regions associated with specific expressions.
- The approach combines a convolutional neural network (CNN) with an attention mechanism to identify and highlight the important spatial AU cues during the recognition process.
Plain English Explanation
The research paper describes a new way to recognize facial expressions that is both accurate and easy to understand. Current FER models can accurately identify different emotions, but they often work like "black boxes" - it's hard to know exactly which parts of the face they're focusing on to make their predictions.
The proposed model [https://aimodels.fyi/papers/arxiv/causal-intervention-subject-deconfounded-facial-action-unit] tries to fix this by explicitly guiding the model to pay attention to the specific facial regions (called "action units") that are most relevant for each expression. For example, when recognizing a happy expression, the model will highlight the areas around the eyes and mouth that typically show up when someone is smiling.
This approach [https://aimodels.fyi/papers/arxiv/multi-scale-dynamic-hierarchical-relationship-modeling-facial] makes the model's decision-making process more transparent and interpretable. Users can see which parts of the face the model is focusing on, which can help build trust in the model's predictions. It also allows for more detailed analysis of how the model is recognizing different expressions.
Technical Explanation
The key components of the proposed approach [https://aimodels.fyi/papers/arxiv/learning-discriminative-spatio-temporal-representations-semi-supervised] are:
- A CNN-based backbone network that extracts visual features from facial images.
- An attention module that identifies the most relevant spatial AU cues for each expression.
- A classification head that predicts the final facial expression label using the attended feature maps.
The attention module [https://aimodels.fyi/papers/arxiv/exploring-explainability-video-action-recognition] dynamically computes attention weights for different facial regions based on the input image. These weights are then used to create a weighted sum of the feature maps, highlighting the most important spatial AU cues for the given expression.
During training, the model is guided to focus on the relevant AU cues through a combination of expression recognition loss and an interpretability loss that encourages the attention maps to align with ground truth AU annotations.
Critical Analysis
The paper [https://aimodels.fyi/papers/arxiv/language-model-guided-interpretable-video-action-reasoning] presents a promising approach for improving the interpretability of FER models without sacrificing accuracy. By explicitly modeling the relationship between facial actions and expressions, the model can provide insights into its decision-making process.
However, the authors acknowledge that the model's performance is still slightly lower than state-of-the-art black-box FER models. Additionally, the reliance on ground truth AU annotations during training may limit the model's real-world applicability, as such annotations can be expensive and time-consuming to obtain.
Further research could explore ways to improve the model's accuracy, perhaps by incorporating additional data sources or architectural innovations. Investigating the model's generalization capabilities and robustness to various facial variations would also be valuable.
Conclusion
The proposed guided interpretable FER model represents an important step towards developing more transparent and explainable AI systems for facial expression recognition. By leveraging spatial AU cues, the model can provide users with a better understanding of how it arrives at its predictions, which can foster greater trust and facilitate more meaningful applications of FER technology.
As the field of AI continues to advance, such interpretable and explainable approaches will become increasingly crucial for ensuring the responsible and ethical deployment of these powerful tools in real-world settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Guided Interpretable Facial Expression Recognition via Spatial Action Unit Cues
Soufiane Belharbi, Marco Pedersoli, Alessandro Lameiras Koerich, Simon Bacon, Eric Granger
Although state-of-the-art classifiers for facial expression recognition (FER) can achieve a high level of accuracy, they lack interpretability, an important feature for end-users. Experts typically associate spatial action units (aus) from a codebook to facial regions for the visual interpretation of expressions. In this paper, the same expert steps are followed. A new learning strategy is proposed to explicitly incorporate au cues into classifier training, allowing to train deep interpretable models. During training, this au codebook is used, along with the input image expression label, and facial landmarks, to construct a au heatmap that indicates the most discriminative image regions of interest w.r.t the facial expression. This valuable spatial cue is leveraged to train a deep interpretable classifier for FER. This is achieved by constraining the spatial layer features of a classifier to be correlated with au heatmaps. Using a composite loss, the classifier is trained to correctly classify an image while yielding interpretable visual layer-wise attention correlated with au maps, simulating the expert decision process. Our strategy only relies on image class expression for supervision, without additional manual annotations. Our new strategy is generic, and can be applied to any deep CNN- or transformer-based classifier without requiring any architectural change or significant additional training time. Our extensive evaluation on two public benchmarks rafdb, and affectnet datasets shows that our proposed strategy can improve layer-wise interpretability without degrading classification performance. In addition, we explore a common type of interpretable classifiers that rely on class activation mapping (CAM) methods, and show that our approach can also improve CAM interpretability.
Read more5/15/2024
0
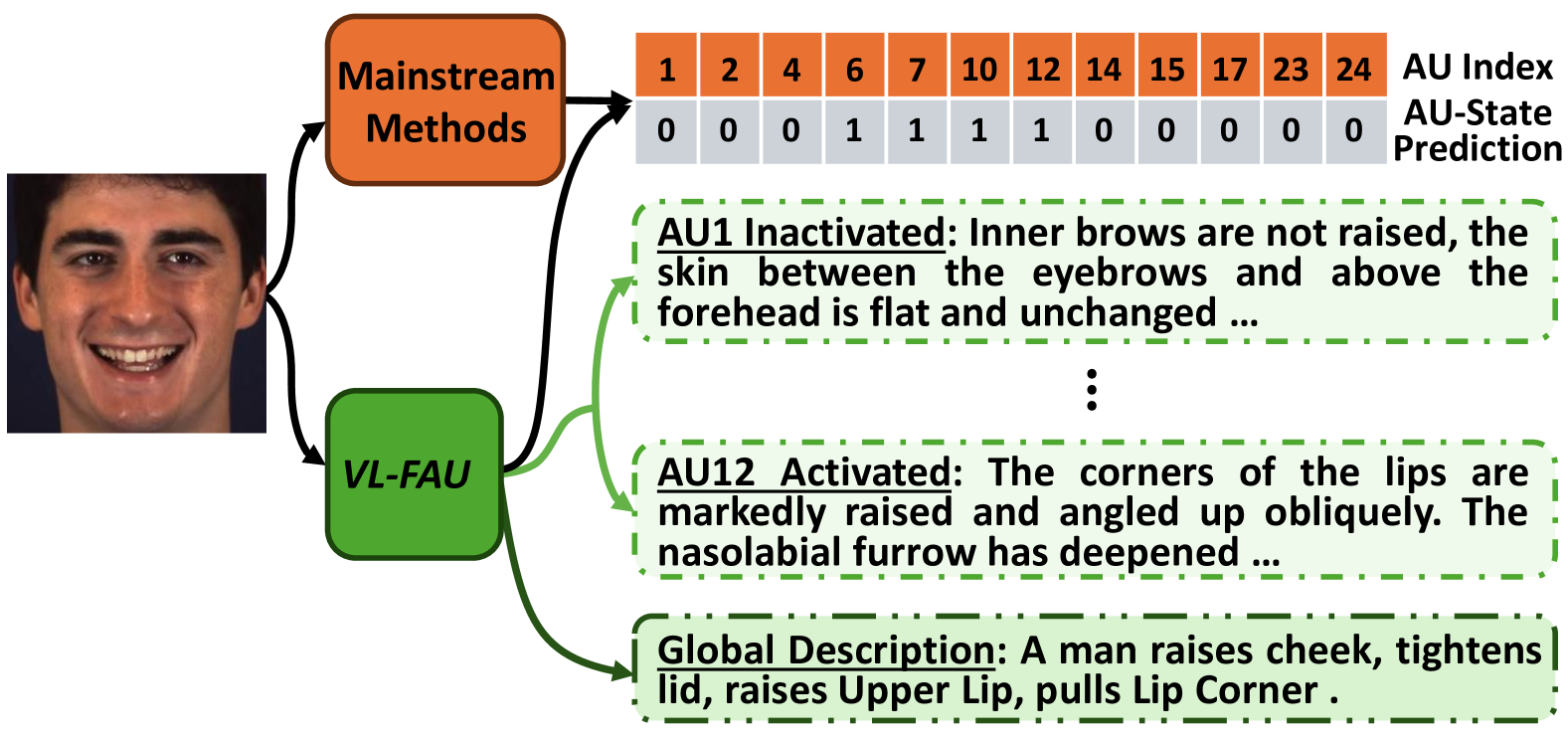
Towards End-to-End Explainable Facial Action Unit Recognition via Vision-Language Joint Learning
Xuri Ge, Junchen Fu, Fuhai Chen, Shan An, Nicu Sebe, Joemon M. Jose
Facial action units (AUs), as defined in the Facial Action Coding System (FACS), have received significant research interest owing to their diverse range of applications in facial state analysis. Current mainstream FAU recognition models have a notable limitation, i.e., focusing only on the accuracy of AU recognition and overlooking explanations of corresponding AU states. In this paper, we propose an end-to-end Vision-Language joint learning network for explainable FAU recognition (termed VL-FAU), which aims to reinforce AU representation capability and language interpretability through the integration of joint multimodal tasks. Specifically, VL-FAU brings together language models to generate fine-grained local muscle descriptions and distinguishable global face description when optimising FAU recognition. Through this, the global facial representation and its local AU representations will achieve higher distinguishability among different AUs and different subjects. In addition, multi-level AU representation learning is utilised to improve AU individual attention-aware representation capabilities based on multi-scale combined facial stem feature. Extensive experiments on DISFA and BP4D AU datasets show that the proposed approach achieves superior performance over the state-of-the-art methods on most of the metrics. In addition, compared with mainstream FAU recognition methods, VL-FAU can provide local- and global-level interpretability language descriptions with the AUs' predictions.
Read more8/2/2024
👁️
0
Causal Intervention for Subject-Deconfounded Facial Action Unit Recognition
Yingjie Chen, Diqi Chen, Tao Wang, Yizhou Wang, Yun Liang
Subject-invariant facial action unit (AU) recognition remains challenging for the reason that the data distribution varies among subjects. In this paper, we propose a causal inference framework for subject-invariant facial action unit recognition. To illustrate the causal effect existing in AU recognition task, we formulate the causalities among facial images, subjects, latent AU semantic relations, and estimated AU occurrence probabilities via a structural causal model. By constructing such a causal diagram, we clarify the causal effect among variables and propose a plug-in causal intervention module, CIS, to deconfound the confounder emph{Subject} in the causal diagram. Extensive experiments conducted on two commonly used AU benchmark datasets, BP4D and DISFA, show the effectiveness of our CIS, and the model with CIS inserted, CISNet, has achieved state-of-the-art performance.
Read more4/4/2024

0
Towards Localized Fine-Grained Control for Facial Expression Generation
Tuomas Varanka, Huai-Qian Khor, Yante Li, Mengting Wei, Hanwei Kung, Nicu Sebe, Guoying Zhao
Generative models have surged in popularity recently due to their ability to produce high-quality images and video. However, steering these models to produce images with specific attributes and precise control remains challenging. Humans, particularly their faces, are central to content generation due to their ability to convey rich expressions and intent. Current generative models mostly generate flat neutral expressions and characterless smiles without authenticity. Other basic expressions like anger are possible, but are limited to the stereotypical expression, while other unconventional facial expressions like doubtful are difficult to reliably generate. In this work, we propose the use of AUs (action units) for facial expression control in face generation. AUs describe individual facial muscle movements based on facial anatomy, allowing precise and localized control over the intensity of facial movements. By combining different action units, we unlock the ability to create unconventional facial expressions that go beyond typical emotional models, enabling nuanced and authentic reactions reflective of real-world expressions. The proposed method can be seamlessly integrated with both text and image prompts using adapters, offering precise and intuitive control of the generated results. Code and dataset are available in {https://github.com/tvaranka/fineface}.
Read more7/30/2024