Towards End-to-End Explainable Facial Action Unit Recognition via Vision-Language Joint Learning

0
Sign in to get full access
Overview
- This paper proposes a new approach for facial action unit (AU) recognition that combines visual and language information.
- The goal is to build an end-to-end explainable system that can recognize AUs and provide intuitive explanations for its predictions.
- The key contributions include a vision-language joint learning framework and a novel visualization technique for interpreting model decisions.
Plain English Explanation
Facial action units (AUs) are the basic building blocks of facial expressions, representing the movement of different facial muscles. Recognizing AUs is an important task in computer vision, with applications in areas like emotion analysis and human-computer interaction.
The researchers in this paper developed a new method for AU recognition that brings together visual information (from facial images) and language information (from text descriptions of facial expressions). By jointly learning from these two modalities, the model is able to not only accurately recognize AUs, but also provide intuitive explanations for its predictions.
For example, if the model detects that the "brow lowerer" AU is present, it can point to specific regions of the face that contributed to that decision and link it to language concepts like "frowning" or "looking angry." This explainability is important for building trust in the system and understanding how it works.
Overall, this approach represents an advance towards more interpretable and understandable AI systems for facial analysis tasks.
Technical Explanation
The proposed framework consists of a vision-language joint learning model and a novel visualization technique.
The joint learning model takes facial images and their corresponding textual descriptions as input. It learns to extract visual features and associate them with language concepts related to facial expressions and AUs. This allows the model to recognize AUs not only from visual cues, but also by understanding the semantic meanings of facial movements.
The visualization technique uses gradient-based saliency maps to highlight the regions of the face that contribute most to the model's AU predictions. It also links these visual explanations to the corresponding language concepts, providing a clear and intuitive interpretation of the model's decision-making process.
The researchers evaluated their approach on standard facial AU recognition benchmarks and found that it outperformed previous state-of-the-art methods in terms of both accuracy and explainability.
Critical Analysis
One limitation of the study is that it only considered static facial images, whereas in real-world scenarios, facial expressions are often dynamic. Incorporating temporal information could potentially improve the model's ability to recognize complex and nuanced facial expressions.
Additionally, the researchers only evaluated their method on existing datasets, which may not fully capture the diversity of real-world facial expressions. Further testing on more diverse and realistic datasets could help validate the generalizability of the proposed approach.
Overall, this work represents a promising step towards more explainable and user-friendly facial analysis systems. By leveraging both visual and language information, the model can provide insights into its decision-making process, which is essential for building trust and understanding in AI-powered applications.
Conclusion
This paper introduces a novel approach for facial action unit recognition that combines visual and language information in an end-to-end explainable framework. The key contributions include a vision-language joint learning model and a visualization technique that links the model's predictions to intuitive language concepts.
The results demonstrate the potential of this approach for building more transparent and interpretable AI systems for facial analysis tasks. Further research is needed to address the limitations and explore the application of this technology in real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards End-to-End Explainable Facial Action Unit Recognition via Vision-Language Joint Learning
Xuri Ge, Junchen Fu, Fuhai Chen, Shan An, Nicu Sebe, Joemon M. Jose
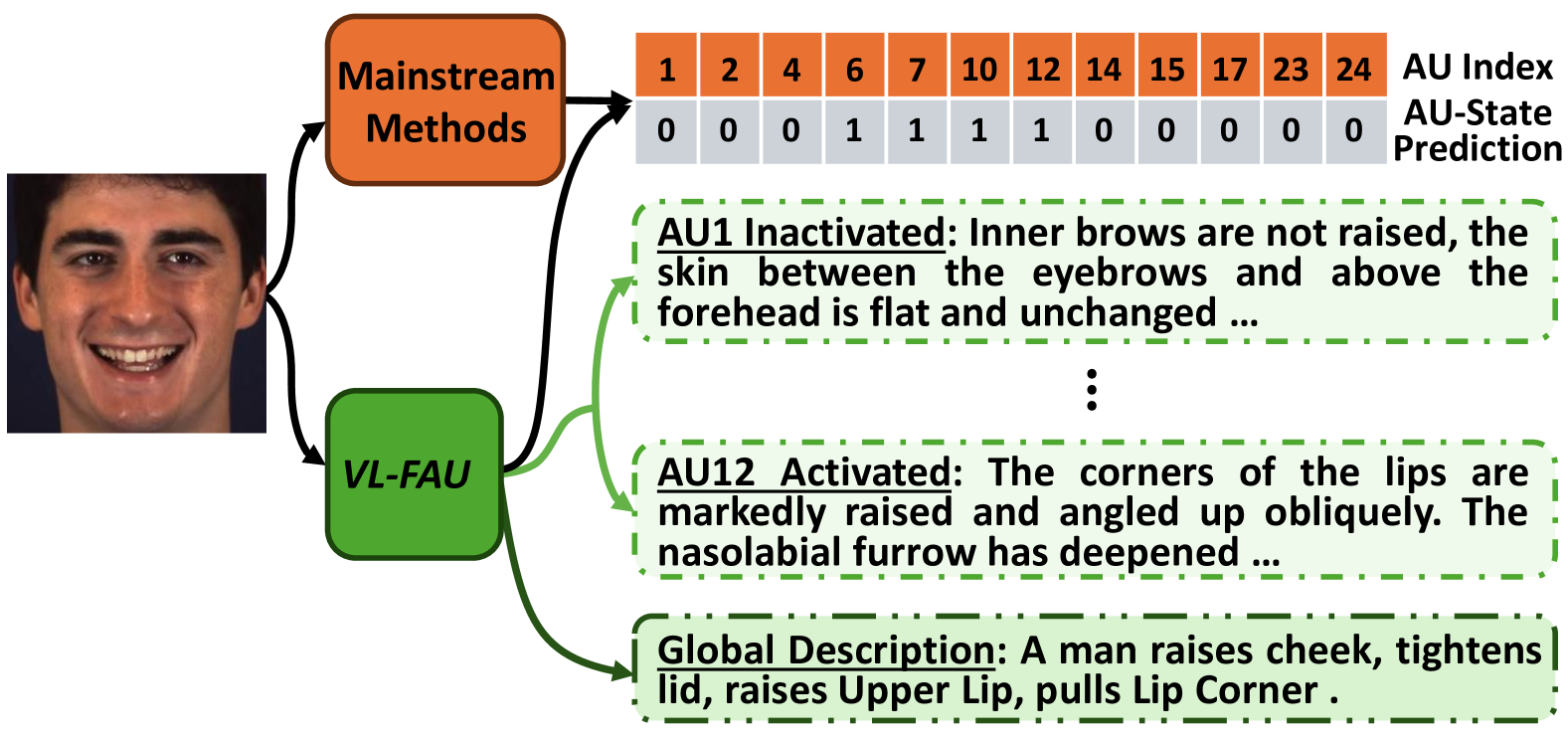
Facial action units (AUs), as defined in the Facial Action Coding System (FACS), have received significant research interest owing to their diverse range of applications in facial state analysis. Current mainstream FAU recognition models have a notable limitation, i.e., focusing only on the accuracy of AU recognition and overlooking explanations of corresponding AU states. In this paper, we propose an end-to-end Vision-Language joint learning network for explainable FAU recognition (termed VL-FAU), which aims to reinforce AU representation capability and language interpretability through the integration of joint multimodal tasks. Specifically, VL-FAU brings together language models to generate fine-grained local muscle descriptions and distinguishable global face description when optimising FAU recognition. Through this, the global facial representation and its local AU representations will achieve higher distinguishability among different AUs and different subjects. In addition, multi-level AU representation learning is utilised to improve AU individual attention-aware representation capabilities based on multi-scale combined facial stem feature. Extensive experiments on DISFA and BP4D AU datasets show that the proposed approach achieves superior performance over the state-of-the-art methods on most of the metrics. In addition, compared with mainstream FAU recognition methods, VL-FAU can provide local- and global-level interpretability language descriptions with the AUs' predictions.
Read more8/2/2024

0
New!Towards Unified Facial Action Unit Recognition Framework by Large Language Models
Guohong Hu, Xing Lan, Hanyu Jiang, Jiayi Lyu, Jian Xue
Facial Action Units (AUs) are of great significance in the realm of affective computing. In this paper, we propose AU-LLaVA, the first unified AU recognition framework based on the Large Language Model (LLM). AU-LLaVA consists of a visual encoder, a linear projector layer, and a pre-trained LLM. We meticulously craft the text descriptions and fine-tune the model on various AU datasets, allowing it to generate different formats of AU recognition results for the same input image. On the BP4D and DISFA datasets, AU-LLaVA delivers the most accurate recognition results for nearly half of the AUs. Our model achieves improvements of F1-score up to 11.4% in specific AU recognition compared to previous benchmark results. On the FEAFA dataset, our method achieves significant improvements over all 24 AUs compared to previous benchmark results. AU-LLaVA demonstrates exceptional performance and versatility in AU recognition.
Read more9/16/2024

0
AU-vMAE: Knowledge-Guide Action Units Detection via Video Masked Autoencoder
Qiaoqiao Jin, Rui Shi, Yishun Dou, Bingbing Ni
Current Facial Action Unit (FAU) detection methods generally encounter difficulties due to the scarcity of labeled video training data and the limited number of training face IDs, which renders the trained feature extractor insufficient coverage for modeling the large diversity of inter-person facial structures and movements. To explicitly address the above challenges, we propose a novel video-level pre-training scheme by fully exploring the multi-label property of FAUs in the video as well as the temporal label consistency. At the heart of our design is a pre-trained video feature extractor based on the video-masked autoencoder together with a fine-tuning network that jointly completes the multi-level video FAUs analysis tasks, emph{i.e.} integrating both video-level and frame-level FAU detections, thus dramatically expanding the supervision set from sparse FAUs annotations to ALL video frames including masked ones. Moreover, we utilize inter-frame and intra-frame AU pair state matrices as prior knowledge to guide network training instead of traditional Graph Neural Networks, for better temporal supervision. Our approach demonstrates substantial enhancement in performance compared to the existing state-of-the-art methods used in BP4D and DISFA FAUs datasets.
Read more7/17/2024

0
Guided Interpretable Facial Expression Recognition via Spatial Action Unit Cues
Soufiane Belharbi, Marco Pedersoli, Alessandro Lameiras Koerich, Simon Bacon, Eric Granger
Although state-of-the-art classifiers for facial expression recognition (FER) can achieve a high level of accuracy, they lack interpretability, an important feature for end-users. Experts typically associate spatial action units (aus) from a codebook to facial regions for the visual interpretation of expressions. In this paper, the same expert steps are followed. A new learning strategy is proposed to explicitly incorporate au cues into classifier training, allowing to train deep interpretable models. During training, this au codebook is used, along with the input image expression label, and facial landmarks, to construct a au heatmap that indicates the most discriminative image regions of interest w.r.t the facial expression. This valuable spatial cue is leveraged to train a deep interpretable classifier for FER. This is achieved by constraining the spatial layer features of a classifier to be correlated with au heatmaps. Using a composite loss, the classifier is trained to correctly classify an image while yielding interpretable visual layer-wise attention correlated with au maps, simulating the expert decision process. Our strategy only relies on image class expression for supervision, without additional manual annotations. Our new strategy is generic, and can be applied to any deep CNN- or transformer-based classifier without requiring any architectural change or significant additional training time. Our extensive evaluation on two public benchmarks rafdb, and affectnet datasets shows that our proposed strategy can improve layer-wise interpretability without degrading classification performance. In addition, we explore a common type of interpretable classifiers that rely on class activation mapping (CAM) methods, and show that our approach can also improve CAM interpretability.
Read more5/15/2024