Guided Safe Shooting: model based reinforcement learning with safety constraints

0
📈
Sign in to get full access
Overview
- Reinforcement learning has successfully tackled complex problems, but struggles with real-world deployment due to lack of safety guarantees.
- This paper introduces Guided Safe Shooting (GuSS), a model-based reinforcement learning approach that can learn to control systems while minimizing violations of safety constraints.
- GuSS learns a model of the system through iterative data collection, then uses this model to plan actions that maximize reward while avoiding unsafe states.
- The paper proposes three different safe planning algorithms and shows they help the learning agent explore the state space while staying safe.
- Compared to model-free approaches, GuSS can reduce the number of interactions with the real system while still achieving high rewards, an important factor for engineering applications.
Plain English Explanation
Reinforcement learning is a powerful technique that has been used to solve complex problems, like beating humans at the game of Go. However, deploying these algorithms in the real world has proven challenging, especially when it comes to ensuring safety.
In many real-world applications, such as controlling critical engineering systems, it's essential that the system never enters an unsafe state. The paper introduces a new approach called Guided Safe Shooting (GuSS) that aims to address this challenge.
GuSS works by first learning a model of the system it's trying to control. It does this by collecting data as the system operates and then using that data to train a predictive model. Once the model is learned, GuSS can use it to plan actions that will maximize the reward (e.g. the system's performance) while also avoiding unsafe states.
The paper proposes three different algorithms for this "safe planning" process. One is a simple random approach, while the other two use a more advanced technique called MAP-Elites. These algorithms help the learning agent explore the system's full range of behaviors while still staying within the safety boundaries.
Compared to other reinforcement learning methods that don't learn a model, GuSS has the advantage of being able to achieve high rewards with fewer interactions with the real system. This is crucial for real-world engineering applications, where interacting with the actual system can be expensive or risky.
Technical Explanation
The key innovation of the Guided Safe Shooting (GuSS) approach is its use of a learned model to plan actions that maximize reward while avoiding unsafe states.
The process starts by collecting data as the system operates and using that data to train a predictive model. This model allows GuSS to simulate the effects of different actions and plan accordingly. The authors propose three different safe planning algorithms:
- Random Shooting: This simple approach randomly samples actions and evaluates their safety and reward using the learned model.
- MAP-Elites (Uniform): This algorithm uses the MAP-Elites divergent search technique to find a diverse set of high-performing, safe policies.
- MAP-Elites (Gaussian): A variant of the above that uses a Gaussian distribution to sample actions around high-performing, safe policies.
The experiments show that these safe planning approaches help the learning agent avoid unsafe situations while still thoroughly exploring the system's state space. This exploration is crucial for learning an accurate model of the system.
Furthermore, the use of a learned model allows GuSS to achieve high rewards with fewer interactions with the real system, compared to model-free reinforcement learning techniques. This is a key advantage for real-world engineering applications where interactions with the actual system can be costly or dangerous.
Critical Analysis
The Guided Safe Shooting (GuSS) approach represents an important step towards making reinforcement learning more practical for safety-critical applications. By explicitly incorporating safety constraints into the planning process, GuSS addresses a key limitation of many reinforcement learning algorithms.
That said, the paper does not provide a comprehensive analysis of the limitations and potential issues with the GuSS approach. For example, the authors do not discuss how the performance of GuSS might be affected by inaccuracies or biases in the learned model. It's also unclear how well GuSS would scale to more complex, high-dimensional systems.
Additionally, the paper focuses solely on single-objective optimization, where the goal is to maximize a single reward signal. In many real-world applications, there may be multiple, potentially conflicting objectives that need to be balanced. Extensions of GuSS to handle multi-objective optimization problems could be an important area for future research.
Overall, the Guided Safe Shooting (GuSS) approach is a promising step forward, but further research is needed to fully understand its capabilities and limitations in practical settings.
Conclusion
The Guided Safe Shooting (GuSS) paper introduces a novel model-based reinforcement learning approach that can learn to control systems while minimizing violations of safety constraints. By learning a predictive model of the system and using it to plan actions that maximize reward while avoiding unsafe states, GuSS addresses a key challenge in deploying reinforcement learning in real-world, safety-critical applications.
The experiments demonstrate the effectiveness of GuSS's safe planning algorithms, which help the learning agent thoroughly explore the system's state space while staying within the safety boundaries. Compared to model-free approaches, GuSS can achieve high rewards with fewer interactions with the real system, an important practical advantage.
While the GuSS approach represents an important step forward, further research is needed to fully understand its limitations and explore extensions to more complex, multi-objective optimization problems. Nonetheless, this work highlights the potential of model-based reinforcement learning techniques to unlock the power of these algorithms for real-world, safety-critical systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
Guided Safe Shooting: model based reinforcement learning with safety constraints
Giuseppe Paolo, Jonas Gonzalez-Billandon, Albert Thomas, Bal'azs K'egl
In the last decade, reinforcement learning successfully solved complex control tasks and decision-making problems, like the Go board game. Yet, there are few success stories when it comes to deploying those algorithms to real-world scenarios. One of the reasons is the lack of guarantees when dealing with and avoiding unsafe states, a fundamental requirement in critical control engineering systems. In this paper, we introduce Guided Safe Shooting (GuSS), a model-based RL approach that can learn to control systems with minimal violations of the safety constraints. The model is learned on the data collected during the operation of the system in an iterated batch fashion, and is then used to plan for the best action to perform at each time step. We propose three different safe planners, one based on a simple random shooting strategy and two based on MAP-Elites, a more advanced divergent-search algorithm. Experiments show that these planners help the learning agent avoid unsafe situations while maximally exploring the state space, a necessary aspect when learning an accurate model of the system. Furthermore, compared to model-free approaches, learning a model allows GuSS reducing the number of interactions with the real-system while still reaching high rewards, a fundamental requirement when handling engineering systems.
Read more9/14/2024
🛠️
0
New!Learn With Imagination: Safe Set Guided State-wise Constrained Policy Optimization
Feihan Li, Yifan Sun, Weiye Zhao, Rui Chen, Tianhao Wei, Changliu Liu
Deep reinforcement learning (RL) excels in various control tasks, yet the absence of safety guarantees hampers its real-world applicability. In particular, explorations during learning usually results in safety violations, while the RL agent learns from those mistakes. On the other hand, safe control techniques ensure persistent safety satisfaction but demand strong priors on system dynamics, which is usually hard to obtain in practice. To address these problems, we present Safe Set Guided State-wise Constrained Policy Optimization (S-3PO), a pioneering algorithm generating state-wise safe optimal policies with zero training violations, i.e., learning without mistakes. S-3PO first employs a safety-oriented monitor with black-box dynamics to ensure safe exploration. It then enforces an imaginary cost for the RL agent to converge to optimal behaviors within safety constraints. S-3PO outperforms existing methods in high-dimensional robotics tasks, managing state-wise constraints with zero training violation. This innovation marks a significant stride towards real-world safe RL deployment.
Read more10/2/2024
🏅
0
GUARD: A Safe Reinforcement Learning Benchmark
Weiye Zhao, Yifan Sun, Feihan Li, Rui Chen, Ruixuan Liu, Tianhao Wei, Changliu Liu
Due to the trial-and-error nature, it is typically challenging to apply RL algorithms to safety-critical real-world applications, such as autonomous driving, human-robot interaction, robot manipulation, etc, where such errors are not tolerable. Recently, safe RL (i.e. constrained RL) has emerged rapidly in the literature, in which the agents explore the environment while satisfying constraints. Due to the diversity of algorithms and tasks, it remains difficult to compare existing safe RL algorithms. To fill that gap, we introduce GUARD, a Generalized Unified SAfe Reinforcement Learning Development Benchmark. GUARD has several advantages compared to existing benchmarks. First, GUARD is a generalized benchmark with a wide variety of RL agents, tasks, and safety constraint specifications. Second, GUARD comprehensively covers state-of-the-art safe RL algorithms with self-contained implementations. Third, GUARD is highly customizable in tasks and algorithms. We present a comparison of state-of-the-art safe RL algorithms in various task settings using GUARD and establish baselines that future work can build on.
Read more9/25/2024
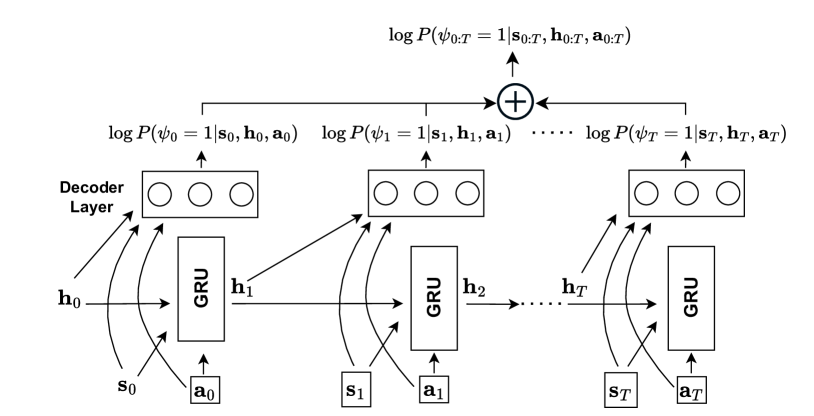
0
Safe Reinforcement Learning with Learned Non-Markovian Safety Constraints
Siow Meng Low, Akshat Kumar
In safe Reinforcement Learning (RL), safety cost is typically defined as a function dependent on the immediate state and actions. In practice, safety constraints can often be non-Markovian due to the insufficient fidelity of state representation, and safety cost may not be known. We therefore address a general setting where safety labels (e.g., safe or unsafe) are associated with state-action trajectories. Our key contributions are: first, we design a safety model that specifically performs credit assignment to assess contributions of partial state-action trajectories on safety. This safety model is trained using a labeled safety dataset. Second, using RL-as-inference strategy we derive an effective algorithm for optimizing a safe policy using the learned safety model. Finally, we devise a method to dynamically adapt the tradeoff coefficient between reward maximization and safety compliance. We rewrite the constrained optimization problem into its dual problem and derive a gradient-based method to dynamically adjust the tradeoff coefficient during training. Our empirical results demonstrate that this approach is highly scalable and able to satisfy sophisticated non-Markovian safety constraints.
Read more5/7/2024