GUARD: A Safe Reinforcement Learning Benchmark

0
🏅
Sign in to get full access
Overview
- Reinforcement learning (RL) algorithms can be challenging to apply to safety-critical real-world applications due to the trial-and-error nature.
- Safe RL, or constrained RL, aims to address this by having agents explore the environment while satisfying constraints.
- However, it remains difficult to compare existing safe RL algorithms due to the diversity of algorithms and tasks.
Plain English Explanation
Reinforcement learning is a way for computer systems, or "agents," to learn how to make decisions and take actions in an environment in order to achieve a goal. The agent tries different actions and gets rewards or penalties based on how well it's doing. This trial-and-error process can be very effective, but it can also be risky in situations where mistakes could be dangerous, like autonomous driving or robot manipulation.
To address this, researchers have developed "safe reinforcement learning" techniques, where the agent has to follow certain rules or "constraints" while exploring the environment. This helps ensure the agent doesn't do anything too risky. However, there are many different safe RL algorithms, and it's been hard to compare them because they're applied to different tasks and have different ways of specifying the constraints.
Technical Explanation
The researchers introduced a new benchmark called GUARD (Generalized Unified SAfe Reinforcement Learning Development Benchmark) to help address this. GUARD has several key advantages:
- It's a generalized benchmark, meaning it covers a wide variety of RL agents, tasks, and safety constraint specifications.
- It comprehensively includes implementations of the latest safe RL algorithms, so they can be easily compared.
- It's highly customizable, allowing researchers to test different tasks and algorithms.
Using GUARD, the researchers were able to compare the performance of state-of-the-art safe RL algorithms across various task settings. This provides a set of baseline results that future research can build upon.
Critical Analysis
The paper provides a valuable contribution by introducing GUARD as a standardized benchmark for evaluating and comparing safe RL algorithms. This should help accelerate progress in this important area of research.
However, the paper does not delve into the specific details of the safe RL algorithms themselves or how they work. Additionally, the paper does not address potential limitations or drawbacks of the GUARD benchmark, such as the scope of tasks and constraints covered, or how representative the benchmark is of real-world safety-critical applications.
Further research could explore these aspects in more depth, as well as investigate how the performance of safe RL algorithms on the GUARD benchmark translates to their performance in actual deployed systems.
Conclusion
The GUARD benchmark represents an important step forward in the field of safe reinforcement learning, providing a standardized platform for evaluating and comparing a wide range of safe RL algorithms. By establishing a set of baseline results, this work lays the groundwork for future advancements that can make RL techniques more robust and reliable for deployment in real-world, safety-critical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
GUARD: A Safe Reinforcement Learning Benchmark
Weiye Zhao, Yifan Sun, Feihan Li, Rui Chen, Ruixuan Liu, Tianhao Wei, Changliu Liu
Due to the trial-and-error nature, it is typically challenging to apply RL algorithms to safety-critical real-world applications, such as autonomous driving, human-robot interaction, robot manipulation, etc, where such errors are not tolerable. Recently, safe RL (i.e. constrained RL) has emerged rapidly in the literature, in which the agents explore the environment while satisfying constraints. Due to the diversity of algorithms and tasks, it remains difficult to compare existing safe RL algorithms. To fill that gap, we introduce GUARD, a Generalized Unified SAfe Reinforcement Learning Development Benchmark. GUARD has several advantages compared to existing benchmarks. First, GUARD is a generalized benchmark with a wide variety of RL agents, tasks, and safety constraint specifications. Second, GUARD comprehensively covers state-of-the-art safe RL algorithms with self-contained implementations. Third, GUARD is highly customizable in tasks and algorithms. We present a comparison of state-of-the-art safe RL algorithms in various task settings using GUARD and establish baselines that future work can build on.
Read more9/25/2024
📈
0
Guided Safe Shooting: model based reinforcement learning with safety constraints
Giuseppe Paolo, Jonas Gonzalez-Billandon, Albert Thomas, Bal'azs K'egl
In the last decade, reinforcement learning successfully solved complex control tasks and decision-making problems, like the Go board game. Yet, there are few success stories when it comes to deploying those algorithms to real-world scenarios. One of the reasons is the lack of guarantees when dealing with and avoiding unsafe states, a fundamental requirement in critical control engineering systems. In this paper, we introduce Guided Safe Shooting (GuSS), a model-based RL approach that can learn to control systems with minimal violations of the safety constraints. The model is learned on the data collected during the operation of the system in an iterated batch fashion, and is then used to plan for the best action to perform at each time step. We propose three different safe planners, one based on a simple random shooting strategy and two based on MAP-Elites, a more advanced divergent-search algorithm. Experiments show that these planners help the learning agent avoid unsafe situations while maximally exploring the state space, a necessary aspect when learning an accurate model of the system. Furthermore, compared to model-free approaches, learning a model allows GuSS reducing the number of interactions with the real-system while still reaching high rewards, a fundamental requirement when handling engineering systems.
Read more9/14/2024
🏅
0
A Review of Safe Reinforcement Learning: Methods, Theory and Applications
Shangding Gu, Long Yang, Yali Du, Guang Chen, Florian Walter, Jun Wang, Alois Knoll
Reinforcement Learning (RL) has achieved tremendous success in many complex decision-making tasks. However, safety concerns are raised during deploying RL in real-world applications, leading to a growing demand for safe RL algorithms, such as in autonomous driving and robotics scenarios. While safe control has a long history, the study of safe RL algorithms is still in the early stages. To establish a good foundation for future safe RL research, in this paper, we provide a review of safe RL from the perspectives of methods, theories, and applications. Firstly, we review the progress of safe RL from five dimensions and come up with five crucial problems for safe RL being deployed in real-world applications, coined as 2H3W. Secondly, we analyze the algorithm and theory progress from the perspectives of answering the 2H3W problems. Particularly, the sample complexity of safe RL algorithms is reviewed and discussed, followed by an introduction to the applications and benchmarks of safe RL algorithms. Finally, we open the discussion of the challenging problems in safe RL, hoping to inspire future research on this thread. To advance the study of safe RL algorithms, we release an open-sourced repository containing the implementations of major safe RL algorithms at the link: https://github.com/chauncygu/Safe-Reinforcement-Learning-Baselines.git.
Read more5/28/2024
0
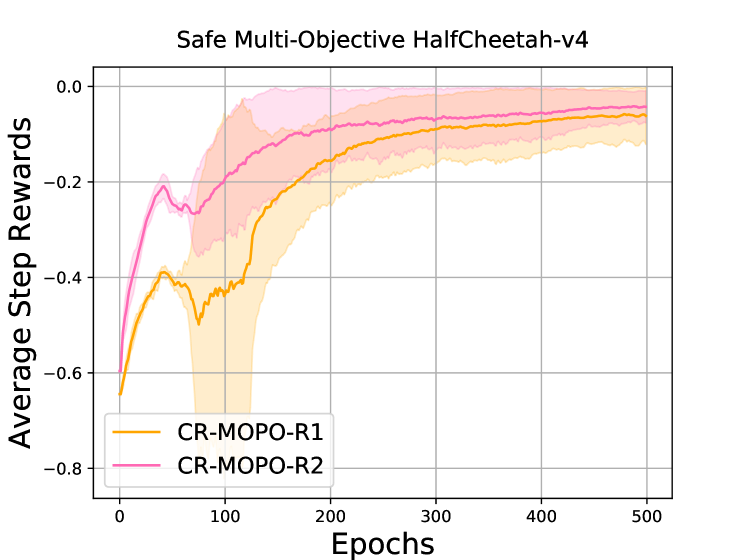
Safe and Balanced: A Framework for Constrained Multi-Objective Reinforcement Learning
Shangding Gu, Bilgehan Sel, Yuhao Ding, Lu Wang, Qingwei Lin, Alois Knoll, Ming Jin
In numerous reinforcement learning (RL) problems involving safety-critical systems, a key challenge lies in balancing multiple objectives while simultaneously meeting all stringent safety constraints. To tackle this issue, we propose a primal-based framework that orchestrates policy optimization between multi-objective learning and constraint adherence. Our method employs a novel natural policy gradient manipulation method to optimize multiple RL objectives and overcome conflicting gradients between different tasks, since the simple weighted average gradient direction may not be beneficial for specific tasks' performance due to misaligned gradients of different task objectives. When there is a violation of a hard constraint, our algorithm steps in to rectify the policy to minimize this violation. We establish theoretical convergence and constraint violation guarantees in a tabular setting. Empirically, our proposed method also outperforms prior state-of-the-art methods on challenging safe multi-objective reinforcement learning tasks.
Read more5/28/2024