Guiding Attention in End-to-End Driving Models
2405.00242
0
0

Abstract
Vision-based end-to-end driving models trained by imitation learning can lead to affordable solutions for autonomous driving. However, training these well-performing models usually requires a huge amount of data, while still lacking explicit and intuitive activation maps to reveal the inner workings of these models while driving. In this paper, we study how to guide the attention of these models to improve their driving quality and obtain more intuitive activation maps by adding a loss term during training using salient semantic maps. In contrast to previous work, our method does not require these salient semantic maps to be available during testing time, as well as removing the need to modify the model's architecture to which it is applied. We perform tests using perfect and noisy salient semantic maps with encouraging results in both, the latter of which is inspired by possible errors encountered with real data. Using CIL++ as a representative state-of-the-art model and the CARLA simulator with its standard benchmarks, we conduct experiments that show the effectiveness of our method in training better autonomous driving models, especially when data and computational resources are scarce.
Create account to get full access
Overview
- The paper explores methods for guiding the attention of end-to-end driving models, which learn to control a vehicle directly from visual inputs.
- The authors propose a novel attention module that can be integrated into existing end-to-end driving models to improve their performance and safety.
- The attention module leverages auxiliary tasks, such as predicting the drivers' gaze, to help the model focus on the most relevant areas of the input image.
Plain English Explanation
The paper is about improving self-driving car systems that use "end-to-end" machine learning models. These models are trained to control the car directly from camera images, without relying on traditional mapping or planning components. The key challenge with end-to-end models is that they can struggle to focus on the most important parts of the scene, which is crucial for safe driving.
To address this, the researchers developed a new attention module that can be added to existing end-to-end models. This attention module uses additional information, like where the human driver is looking, to help the model figure out what parts of the image are most important for driving. By guiding the model's attention to the right places, the researchers were able to improve the model's performance and safety.
The main idea is that by giving the model a better understanding of what to focus on, it can make more informed and reliable decisions when controlling the vehicle. This is an important step forward for making end-to-end driving models more robust and trustworthy.
Technical Explanation
The paper proposes a novel attention module that can be integrated into existing end-to-end driving models to improve their performance and safety. The attention module leverages auxiliary tasks, such as predicting the drivers' gaze, to help the model focus on the most relevant areas of the input image.
The authors first review related work on imitation learning, gaze prediction, and attention mechanisms for autonomous driving (link to "Imitation Learning for Autonomous Driving" paper), (link to "Gaze-Augmented Driving" paper), (link to "Prompting Multi-Modal Tokens" paper), (link to "Understanding and Modeling the Effects of Task and Context on Drivers' Gaze" paper). They then describe the architecture of their attention module, which includes a gaze prediction branch and an attention map generation branch. The gaze prediction branch is trained to predict the driver's gaze location, while the attention map generation branch uses this gaze information to compute an attention map that highlights the most relevant regions of the input image.
The authors evaluate their approach on several benchmark datasets for end-to-end driving, including CARLA and TIPE. The results show that the attention module can significantly improve the performance of existing end-to-end driving models, particularly in terms of safety-critical metrics like lane keeping and collision avoidance.
Critical Analysis
The paper presents a compelling approach for guiding the attention of end-to-end driving models, which is an important challenge in the field of autonomous driving. The use of auxiliary tasks, such as gaze prediction, to inform the model's attention is a clever and well-motivated idea.
One potential limitation of the approach is that it relies on having access to gaze data during training, which may not always be available in real-world deployment scenarios. The authors acknowledge this and suggest exploring ways to generate synthetic gaze data or leverage other cues, such as object detection, to guide the attention module.
Additionally, the paper does not provide a detailed analysis of the attention maps generated by the model, which could be useful for understanding the model's decision-making process and identifying potential failure modes. Providing more insight into the attention mechanism and its interpretability would strengthen the overall contribution of the work.
Despite these minor concerns, the paper makes a valuable contribution to the field of end-to-end driving and demonstrates the potential benefits of attention-guided models for improving the safety and reliability of autonomous vehicles.
Conclusion
The paper presents a novel attention module that can be integrated into existing end-to-end driving models to improve their performance and safety. By leveraging auxiliary tasks, such as gaze prediction, the attention module helps the model focus on the most relevant areas of the input image, which is crucial for safe driving.
The authors' experimental results show that the attention module can significantly enhance the capabilities of end-to-end driving models, particularly in terms of safety-critical metrics like lane keeping and collision avoidance. This work represents an important step forward in making end-to-end driving models more robust and trustworthy, which is a crucial requirement for the widespread adoption of autonomous vehicle technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Enhancing End-to-End Autonomous Driving with Latent World Model
Yingyan Li, Lue Fan, Jiawei He, Yuqi Wang, Yuntao Chen, Zhaoxiang Zhang, Tieniu Tan
0
0
End-to-end autonomous driving has garnered widespread attention. Current end-to-end approaches largely rely on the supervision from perception tasks such as detection, tracking, and map segmentation to aid in learning scene representations. However, these methods require extensive annotations, hindering the data scalability. To address this challenge, we propose a novel self-supervised method to enhance end-to-end driving without the need for costly labels. Specifically, our framework textbf{LAW} uses a LAtent World model to predict future latent features based on the predicted ego actions and the latent feature of the current frame. The predicted latent features are supervised by the actually observed features in the future. This supervision jointly optimizes the latent feature learning and action prediction, which greatly enhances the driving performance. As a result, our approach achieves state-of-the-art performance in both open-loop and closed-loop benchmarks without costly annotations.
6/13/2024

Driver Attention Tracking and Analysis
Dat Viet Thanh Nguyen, Anh Tran, Hoai Nam Vu, Cuong Pham, Minh Hoai
0
0
We propose a novel method to estimate a driver's points-of-gaze using a pair of ordinary cameras mounted on the windshield and dashboard of a car. This is a challenging problem due to the dynamics of traffic environments with 3D scenes of unknown depths. This problem is further complicated by the volatile distance between the driver and the camera system. To tackle these challenges, we develop a novel convolutional network that simultaneously analyzes the image of the scene and the image of the driver's face. This network has a camera calibration module that can compute an embedding vector that represents the spatial configuration between the driver and the camera system. This calibration module improves the overall network's performance, which can be jointly trained end to end. We also address the lack of annotated data for training and evaluation by introducing a large-scale driving dataset with point-of-gaze annotations. This is an in situ dataset of real driving sessions in an urban city, containing synchronized images of the driving scene as well as the face and gaze of the driver. Experiments on this dataset show that the proposed method outperforms various baseline methods, having the mean prediction error of 29.69 pixels, which is relatively small compared to the $1280{times}720$ resolution of the scene camera.
4/12/2024
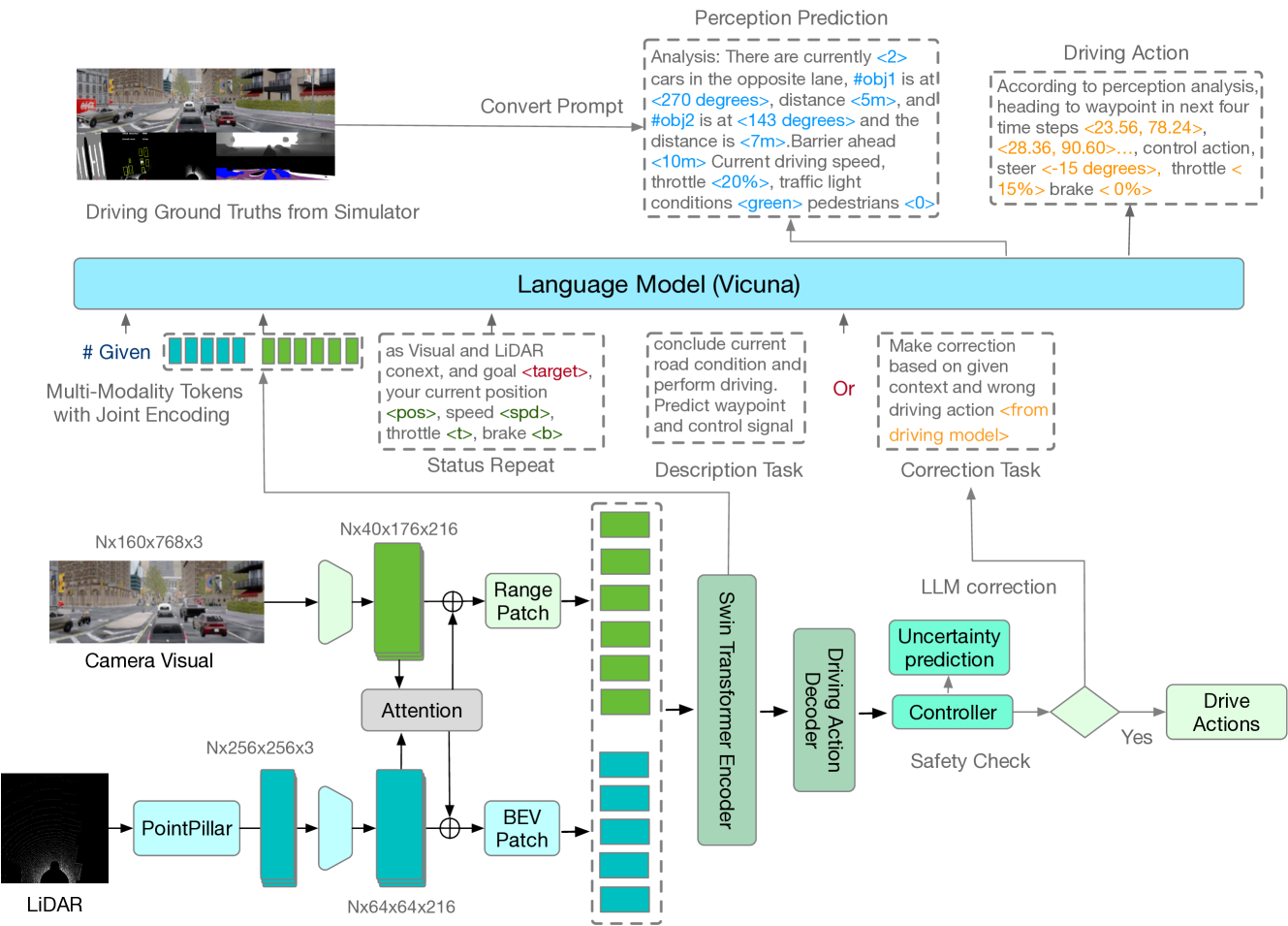
Prompting Multi-Modal Tokens to Enhance End-to-End Autonomous Driving Imitation Learning with LLMs
Yiqun Duan, Qiang Zhang, Renjing Xu
0
0
The utilization of Large Language Models (LLMs) within the realm of reinforcement learning, particularly as planners, has garnered a significant degree of attention in recent scholarly literature. However, a substantial proportion of existing research predominantly focuses on planning models for robotics that transmute the outputs derived from perception models into linguistic forms, thus adopting a `pure-language' strategy. In this research, we propose a hybrid End-to-End learning framework for autonomous driving by combining basic driving imitation learning with LLMs based on multi-modality prompt tokens. Instead of simply converting perception results from the separated train model into pure language input, our novelty lies in two aspects. 1) The end-to-end integration of visual and LiDAR sensory input into learnable multi-modality tokens, thereby intrinsically alleviating description bias by separated pre-trained perception models. 2) Instead of directly letting LLMs drive, this paper explores a hybrid setting of letting LLMs help the driving model correct mistakes and complicated scenarios. The results of our experiments suggest that the proposed methodology can attain driving scores of 49.21%, coupled with an impressive route completion rate of 91.34% in the offline evaluation conducted via CARLA. These performance metrics are comparable to the most advanced driving models.
4/9/2024

Optimizing Visual Question Answering Models for Driving: Bridging the Gap Between Human and Machine Attention Patterns
Kaavya Rekanar, Martin Hayes, Ganesh Sistu, Ciaran Eising
0
0
Visual Question Answering (VQA) models play a critical role in enhancing the perception capabilities of autonomous driving systems by allowing vehicles to analyze visual inputs alongside textual queries, fostering natural interaction and trust between the vehicle and its occupants or other road users. This study investigates the attention patterns of humans compared to a VQA model when answering driving-related questions, revealing disparities in the objects observed. We propose an approach integrating filters to optimize the model's attention mechanisms, prioritizing relevant objects and improving accuracy. Utilizing the LXMERT model for a case study, we compare attention patterns of the pre-trained and Filter Integrated models, alongside human answers using images from the NuImages dataset, gaining insights into feature prioritization. We evaluated the models using a Subjective scoring framework which shows that the integration of the feature encoder filter has enhanced the performance of the VQA model by refining its attention mechanisms.
6/14/2024