Optimizing Visual Question Answering Models for Driving: Bridging the Gap Between Human and Machine Attention Patterns
2406.09203
0
0

Abstract
Visual Question Answering (VQA) models play a critical role in enhancing the perception capabilities of autonomous driving systems by allowing vehicles to analyze visual inputs alongside textual queries, fostering natural interaction and trust between the vehicle and its occupants or other road users. This study investigates the attention patterns of humans compared to a VQA model when answering driving-related questions, revealing disparities in the objects observed. We propose an approach integrating filters to optimize the model's attention mechanisms, prioritizing relevant objects and improving accuracy. Utilizing the LXMERT model for a case study, we compare attention patterns of the pre-trained and Filter Integrated models, alongside human answers using images from the NuImages dataset, gaining insights into feature prioritization. We evaluated the models using a Subjective scoring framework which shows that the integration of the feature encoder filter has enhanced the performance of the VQA model by refining its attention mechanisms.
Create account to get full access
Overview
- This paper focuses on optimizing visual question answering (VQA) models for driving applications, with the goal of bridging the gap between human and machine attention patterns.
- The researchers explore ways to enhance VQA models to better align with how humans perceive and interpret visual scenes, particularly in the context of driving scenarios.
- The paper presents a comprehensive study that investigates the challenges and opportunities in adapting VQA models for driving-related tasks.
Plain English Explanation
Visual question answering (VQA) is a type of artificial intelligence technology that allows computers to answer questions about images. This paper looks at how to make VQA models work better for driving-related tasks.
The researchers wanted to understand the differences between how humans and machines focus on and interpret visual information when answering questions about driving scenes. By understanding these differences, they can optimize VQA models to perform better in real-world driving situations.
For example, humans might focus on things like traffic signals, pedestrians, or road conditions when answering questions about a driving scene. But current VQA models may not always capture these same important details. The paper explores ways to bridge this gap and make VQA models better align with human attention and reasoning patterns.
The goal is to develop VQA systems that can more accurately and safely assist drivers by understanding the visual world in a way that is more similar to how humans perceive it. This could have important applications for autonomous vehicles, driver assistance systems, and other transportation technologies.
Technical Explanation
The paper begins with a background study on existing VQA models and their limitations for driving-related tasks. It notes that current VQA models often focus on generic image understanding, rather than the specific needs of driving scenarios.
The researchers then present a novel approach to enhancing VQA for driving by explicitly modeling the differences between human and machine attention patterns. This involves developing new visual grounding methods that can better align the model's focus with salient elements in driving scenes.
The paper also introduces techniques for selectively answering visual questions based on the model's confidence and the relevance of the question to the driving context. This helps improve the overall performance and robustness of the VQA system.
Through extensive experiments and evaluations, the researchers demonstrate the effectiveness of their proposed methods in bridging the gap between human and machine attention patterns for driving-related VQA tasks.
Critical Analysis
The paper provides a well-designed and thorough investigation of the challenges in adapting VQA models for driving applications. The researchers acknowledge the limitations of current VQA approaches and make a compelling case for the need to better align these models with human attention and reasoning patterns.
One potential area for further research mentioned in the paper is the need to incorporate additional contextual information, such as driver behavior and road conditions, to further enhance the VQA model's performance in real-world driving scenarios.
Additionally, while the paper focuses on driving-related tasks, the proposed techniques for bridging the gap between human and machine attention could potentially be applicable to other domains where VQA models are used, such as healthcare or security applications. Exploring the generalizability of these methods could be an interesting direction for future work.
Conclusion
This paper presents a significant contribution to the field of visual question answering by addressing the specific needs and challenges of driving-related tasks. By developing new methods to align VQA models with human attention patterns, the researchers have taken an important step towards bridging the gap between machine and human perception in the context of transportation applications.
The insights and techniques presented in this work have the potential to enhance the safety and effectiveness of various driving assistance technologies, as well as inform the development of more robust and user-centric VQA systems in general. As the field of artificial intelligence continues to advance, research like this will be crucial in ensuring that these technologies can be seamlessly integrated into our daily lives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
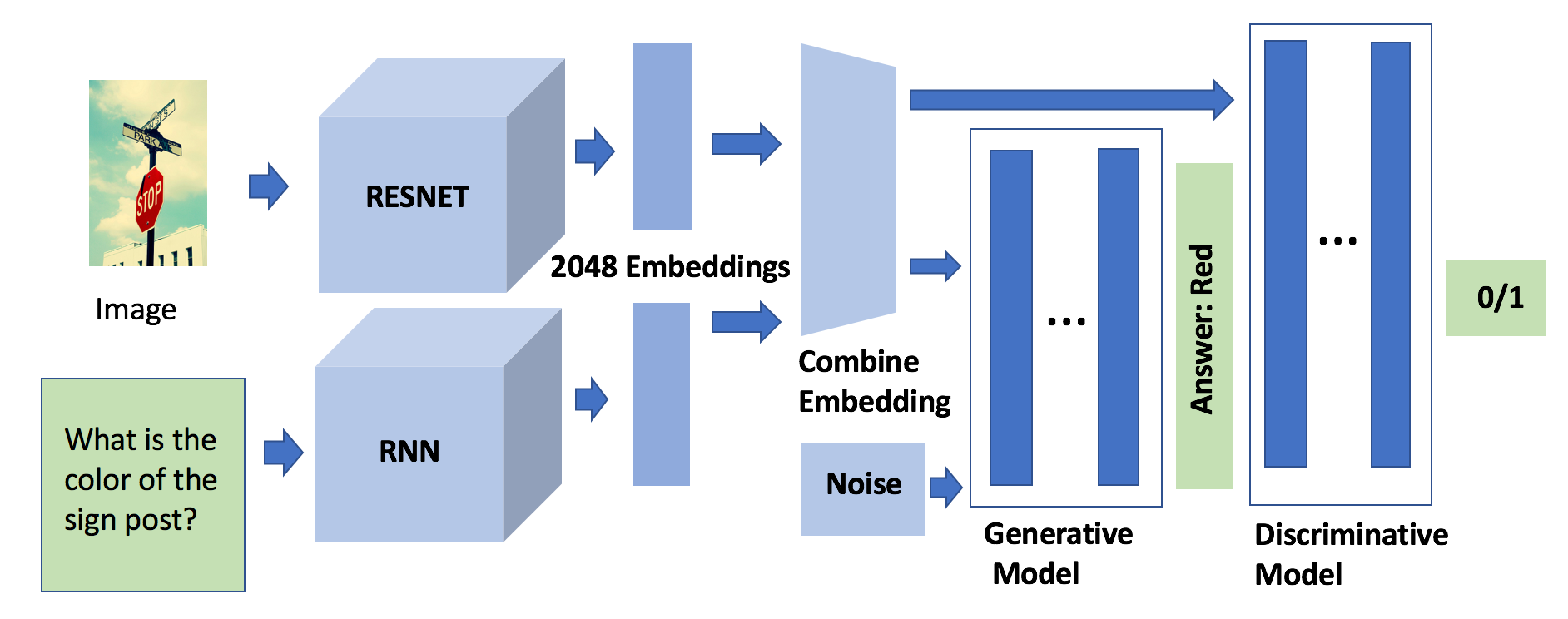
Exploring Diverse Methods in Visual Question Answering
Panfeng Li, Qikai Yang, Xieming Geng, Wenjing Zhou, Zhicheng Ding, Yi Nian
0
0
This study explores innovative methods for improving Visual Question Answering (VQA) using Generative Adversarial Networks (GANs), autoencoders, and attention mechanisms. Leveraging a balanced VQA dataset, we investigate three distinct strategies. Firstly, GAN-based approaches aim to generate answer embeddings conditioned on image and question inputs, showing potential but struggling with more complex tasks. Secondly, autoencoder-based techniques focus on learning optimal embeddings for questions and images, achieving comparable results with GAN due to better ability on complex questions. Lastly, attention mechanisms, incorporating Multimodal Compact Bilinear pooling (MCB), address language priors and attention modeling, albeit with a complexity-performance trade-off. This study underscores the challenges and opportunities in VQA and suggests avenues for future research, including alternative GAN formulations and attentional mechanisms.
5/22/2024

Precision Empowers, Excess Distracts: Visual Question Answering With Dynamically Infused Knowledge In Language Models
Manas Jhalani, Annervaz K M, Pushpak Bhattacharyya
0
0
In the realm of multimodal tasks, Visual Question Answering (VQA) plays a crucial role by addressing natural language questions grounded in visual content. Knowledge-Based Visual Question Answering (KBVQA) advances this concept by adding external knowledge along with images to respond to questions. We introduce an approach for KBVQA, augmenting the existing vision-language transformer encoder-decoder (OFA) model. Our main contribution involves enhancing questions by incorporating relevant external knowledge extracted from knowledge graphs, using a dynamic triple extraction method. We supply a flexible number of triples from the knowledge graph as context, tailored to meet the requirements for answering the question. Our model, enriched with knowledge, demonstrates an average improvement of 4.75% in Exact Match Score over the state-of-the-art on three different KBVQA datasets. Through experiments and analysis, we demonstrate that furnishing variable triples for each question improves the reasoning capabilities of the language model in contrast to supplying a fixed number of triples. This is illustrated even for recent large language models. Additionally, we highlight the model's generalization capability by showcasing its SOTA-beating performance on a small dataset, achieved through straightforward fine-tuning.
6/17/2024

Enhancing Visual Question Answering through Question-Driven Image Captions as Prompts
Ovgu Ozdemir, Erdem Akagunduz
0
0
Visual question answering (VQA) is known as an AI-complete task as it requires understanding, reasoning, and inferring about the vision and the language content. Over the past few years, numerous neural architectures have been suggested for the VQA problem. However, achieving success in zero-shot VQA remains a challenge due to its requirement for advanced generalization and reasoning skills. This study explores the impact of incorporating image captioning as an intermediary process within the VQA pipeline. Specifically, we explore the efficacy of utilizing image captions instead of images and leveraging large language models (LLMs) to establish a zero-shot setting. Since image captioning is the most crucial step in this process, we compare the impact of state-of-the-art image captioning models on VQA performance across various question types in terms of structure and semantics. We propose a straightforward and efficient question-driven image captioning approach within this pipeline to transfer contextual information into the question-answering (QA) model. This method involves extracting keywords from the question, generating a caption for each image-question pair using the keywords, and incorporating the question-driven caption into the LLM prompt. We evaluate the efficacy of using general-purpose and question-driven image captions in the VQA pipeline. Our study highlights the potential of employing image captions and harnessing the capabilities of LLMs to achieve competitive performance on GQA under the zero-shot setting. Our code is available at url{https://github.com/ovguyo/captions-in-VQA}.
4/15/2024
🚀
Visual Grounding Methods for VQA are Working for the Wrong Reasons!
Robik Shrestha, Kushal Kafle, Christopher Kanan
0
0
Existing Visual Question Answering (VQA) methods tend to exploit dataset biases and spurious statistical correlations, instead of producing right answers for the right reasons. To address this issue, recent bias mitigation methods for VQA propose to incorporate visual cues (e.g., human attention maps) to better ground the VQA models, showcasing impressive gains. However, we show that the performance improvements are not a result of improved visual grounding, but a regularization effect which prevents over-fitting to linguistic priors. For instance, we find that it is not actually necessary to provide proper, human-based cues; random, insensible cues also result in similar improvements. Based on this observation, we propose a simpler regularization scheme that does not require any external annotations and yet achieves near state-of-the-art performance on VQA-CPv2.
4/24/2024