GUNet: A Graph Convolutional Network United Diffusion Model for Stable and Diversity Pose Generation

0

Sign in to get full access
Overview
- This paper introduces GUNet, a Graph Convolutional Network United Diffusion Model for generating stable and diverse human poses.
- The researchers combine graph convolutional networks and diffusion models to create a unified framework for pose generation.
- The model aims to address issues with existing pose generation methods, such as instability and lack of diversity in generated poses.
Plain English Explanation
The paper presents a new method called GUNet for generating human poses. Generating realistic human poses is an important task in computer vision and graphics, with applications in areas like animation, virtual reality, and robotics.
Existing methods for pose generation can sometimes produce poses that are unstable or lack variety. To address these issues, the researchers combined two powerful machine learning techniques: graph convolutional networks and diffusion models.
Graph convolutional networks are a type of neural network that can effectively capture the relationships between different parts of the human body, which is crucial for modeling realistic poses. Diffusion models are a newer type of generative model that can produce diverse and high-quality outputs.
By uniting these two approaches, the researchers created a unified framework called GUNet that can generate stable and diverse human poses. The key idea is to use the graph convolutional network to capture the structural information of the human body, and then the diffusion model to generate the final pose in a step-by-step process.
The researchers evaluated GUNet on several benchmarks and found that it outperformed existing pose generation methods in terms of stability, diversity, and realism of the generated poses. This suggests that the combination of graph convolutional networks and diffusion models is a promising direction for advancing the state of the art in human pose generation.
Technical Explanation
The GUNet model consists of two main components: a Graph Convolutional Network (GCN) and a Diffusion Model.
The GCN takes in the 3D coordinates of the human body joints and learns a compact representation that captures the structural relationships between the different body parts. This is done by applying a series of graph convolution operations that propagate information between neighboring joints in the body graph.
The Diffusion Model then takes the GCN representation as input and generates the final 3D pose in a step-by-step process. The diffusion model starts with a random noise signal and gradually refines it, using the structural information from the GCN, to produce a realistic human pose.
The key innovation in GUNet is the combination of the GCN and diffusion model components into a unified framework. This allows the model to leverage the strengths of both approaches: the GCN can capture the body structure, while the diffusion model can generate diverse and stable poses.
The researchers conducted extensive experiments to evaluate GUNet on several pose generation benchmarks. They compared it to other state-of-the-art methods and found that GUNet outperformed them in terms of pose stability, diversity, and realism. This suggests that the proposed approach is a promising direction for advancing human pose generation.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the GUNet model, which is a significant contribution to the field of human pose generation. The combination of graph convolutional networks and diffusion models is a novel and promising approach that addresses key limitations of existing methods.
However, the paper does not discuss potential limitations or caveats of the GUNet approach. For example, the model may struggle with generating poses for complex or unusual body configurations, or it may require a large and diverse training dataset to achieve high-quality results.
Additionally, the paper does not provide much insight into the inner workings of the GCN and diffusion model components, or how the researchers arrived at the specific architectural choices and hyperparameters. A more detailed technical analysis could help other researchers understand and potentially build upon the proposed approach.
Overall, the GUNet model represents an important step forward in human pose generation, and the paper serves as a valuable resource for researchers in this field. Future work could explore ways to further improve the model's performance, address its limitations, and provide a deeper understanding of the underlying mechanisms.
Conclusion
The GUNet model presented in this paper is a significant advancement in the field of human pose generation. By combining graph convolutional networks and diffusion models, the researchers have created a unified framework that can generate stable and diverse 3D human poses.
The extensive evaluation of GUNet on benchmark datasets demonstrates its superior performance compared to existing methods, suggesting that the proposed approach is a promising direction for further research and development. The model's ability to capture the structural relationships in the human body and generate high-quality poses could have important applications in areas such as animation, virtual reality, and robotics.
While the paper does not address certain limitations or provide a deep technical analysis, it still represents a significant contribution to the field and lays the groundwork for future improvements and advancements in human pose generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GUNet: A Graph Convolutional Network United Diffusion Model for Stable and Diversity Pose Generation
Shuowen Liang, Sisi Li, Qingyun Wang, Cen Zhang, Kaiquan Zhu, Tian Yang
Pose skeleton images are an important reference in pose-controllable image generation. In order to enrich the source of skeleton images, recent works have investigated the generation of pose skeletons based on natural language. These methods are based on GANs. However, it remains challenging to perform diverse, structurally correct and aesthetically pleasing human pose skeleton generation with various textual inputs. To address this problem, we propose a framework with GUNet as the main model, PoseDiffusion. It is the first generative framework based on a diffusion model and also contains a series of variants fine-tuned based on a stable diffusion model. PoseDiffusion demonstrates several desired properties that outperform existing methods. 1) Correct Skeletons. GUNet, a denoising model of PoseDiffusion, is designed to incorporate graphical convolutional neural networks. It is able to learn the spatial relationships of the human skeleton by introducing skeletal information during the training process. 2) Diversity. We decouple the key points of the skeleton and characterise them separately, and use cross-attention to introduce textual conditions. Experimental results show that PoseDiffusion outperforms existing SoTA algorithms in terms of stability and diversity of text-driven pose skeleton generation. Qualitative analyses further demonstrate its superiority for controllable generation in Stable Diffusion.
Read more9/19/2024
0
GRPose: Learning Graph Relations for Human Image Generation with Pose Priors
Xiangchen Yin, Donglin Di, Lei Fan, Hao Li, Chen Wei, Xiaofei Gou, Yang Song, Xiao Sun, Xun Yang
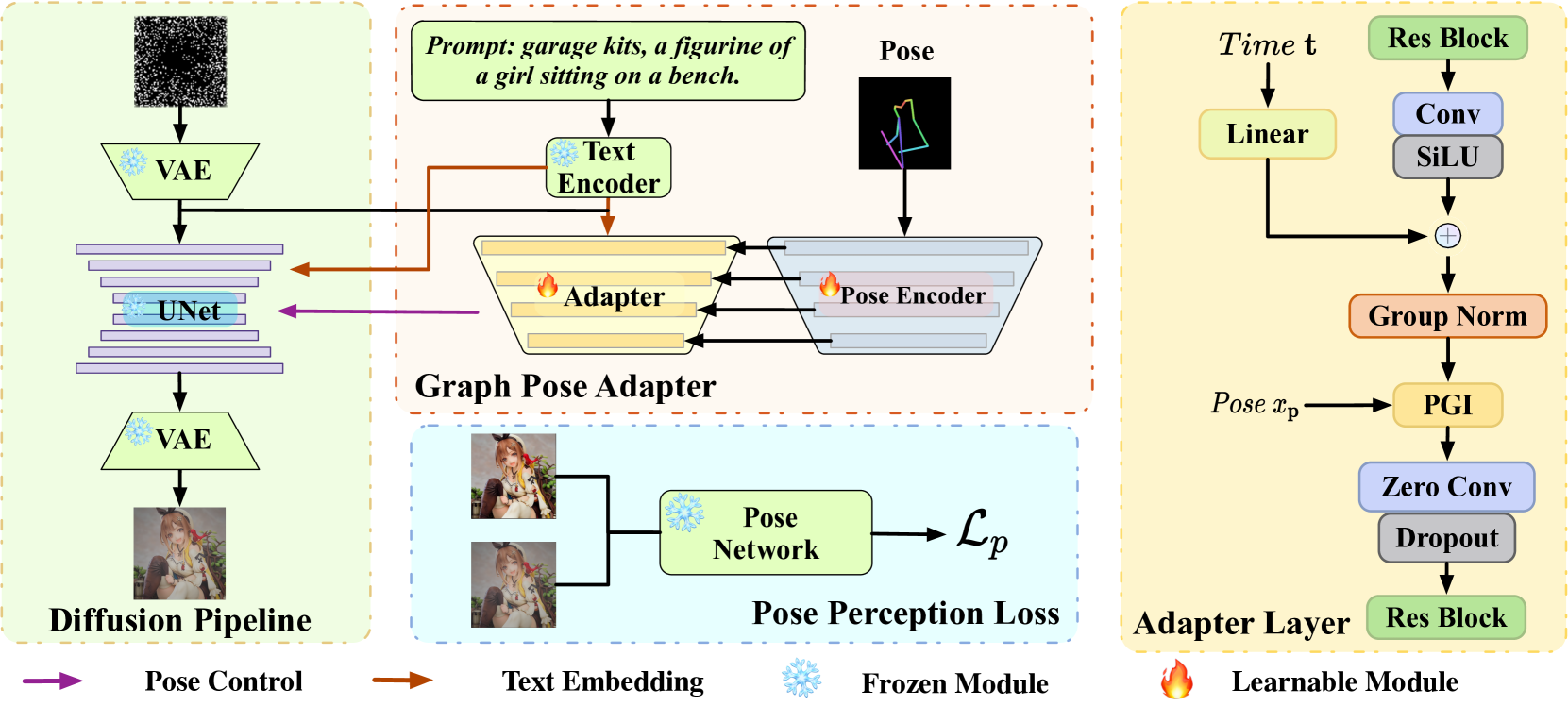
Recent methods using diffusion models have made significant progress in human image generation with various additional controls such as pose priors. However, existing approaches still struggle to generate high-quality images with consistent pose alignment, resulting in unsatisfactory outputs. In this paper, we propose a framework delving into the graph relations of pose priors to provide control information for human image generation. The main idea is to establish a graph topological structure between the pose priors and latent representation of diffusion models to capture the intrinsic associations between different pose parts. A Progressive Graph Integrator (PGI) is designed to learn the spatial relationships of the pose priors with the graph structure, adopting a hierarchical strategy within an Adapter to gradually propagate information across different pose parts. A pose perception loss is further introduced based on a pretrained pose estimation network to minimize the pose differences. Extensive qualitative and quantitative experiments conducted on the Human-Art and LAION-Human datasets demonstrate that our model achieves superior performance, with a 9.98% increase in pose average precision compared to the latest benchmark model. The code is released on *******.
Read more8/30/2024
🎯
0
GatedUniPose: A Novel Approach for Pose Estimation Combining UniRepLKNet and Gated Convolution
Liang Feng, Ming Xu, Lihua Wen, Zhixuan Shen
Pose estimation is a crucial task in computer vision, with wide applications in autonomous driving, human motion capture, and virtual reality. However, existing methods still face challenges in achieving high accuracy, particularly in complex scenes. This paper proposes a novel pose estimation method, GatedUniPose, which combines UniRepLKNet and Gated Convolution and introduces the GLACE module for embedding. Additionally, we enhance the feature map concatenation method in the head layer by using DySample upsampling. Compared to existing methods, GatedUniPose excels in handling complex scenes and occlusion challenges. Experimental results on the COCO, MPII, and CrowdPose datasets demonstrate that GatedUniPose achieves significant performance improvements with a relatively small number of parameters, yielding better or comparable results to models with similar or larger parameter sizes.
Read more9/14/2024

0
Stable-Pose: Leveraging Transformers for Pose-Guided Text-to-Image Generation
Jiajun Wang, Morteza Ghahremani, Yitong Li, Bjorn Ommer, Christian Wachinger
Controllable text-to-image (T2I) diffusion models have shown impressive performance in generating high-quality visual content through the incorporation of various conditions. Current methods, however, exhibit limited performance when guided by skeleton human poses, especially in complex pose conditions such as side or rear perspectives of human figures. To address this issue, we present Stable-Pose, a novel adapter model that introduces a coarse-to-fine attention masking strategy into a vision Transformer (ViT) to gain accurate pose guidance for T2I models. Stable-Pose is designed to adeptly handle pose conditions within pre-trained Stable Diffusion, providing a refined and efficient way of aligning pose representation during image synthesis. We leverage the query-key self-attention mechanism of ViTs to explore the interconnections among different anatomical parts in human pose skeletons. Masked pose images are used to smoothly refine the attention maps based on target pose-related features in a hierarchical manner, transitioning from coarse to fine levels. Additionally, our loss function is formulated to allocate increased emphasis to the pose region, thereby augmenting the model's precision in capturing intricate pose details. We assessed the performance of Stable-Pose across five public datasets under a wide range of indoor and outdoor human pose scenarios. Stable-Pose achieved an AP score of 57.1 in the LAION-Human dataset, marking around 13% improvement over the established technique ControlNet. The project link and code is available at https://github.com/ai-med/StablePose.
Read more6/5/2024