GRPose: Learning Graph Relations for Human Image Generation with Pose Priors

0
Sign in to get full access
Overview
- Proposes a novel method called GRPose for generating realistic human images with accurate pose priors
- Uses a graph neural network to learn the relations between different body parts and incorporate this knowledge into the image generation process
- Demonstrates improved performance compared to previous pose-guided image generation approaches
Plain English Explanation
The GRPose method aims to generate realistic human images while accurately representing the subject's pose. Previous approaches have struggled to capture the complex spatial relationships between different body parts.
GRPose addresses this by using a graph neural network to learn the connections and dependencies between various body parts. This allows the model to understand how different limbs and joints should move together in a natural, human-like way.
By incorporating this graph-based knowledge of pose relationships, GRPose is able to generate human images that not only look realistic, but also have poses that are anatomically correct and visually appealing. This is a significant improvement over prior methods that generated poses that appeared unnatural or disconnected.
Technical Explanation
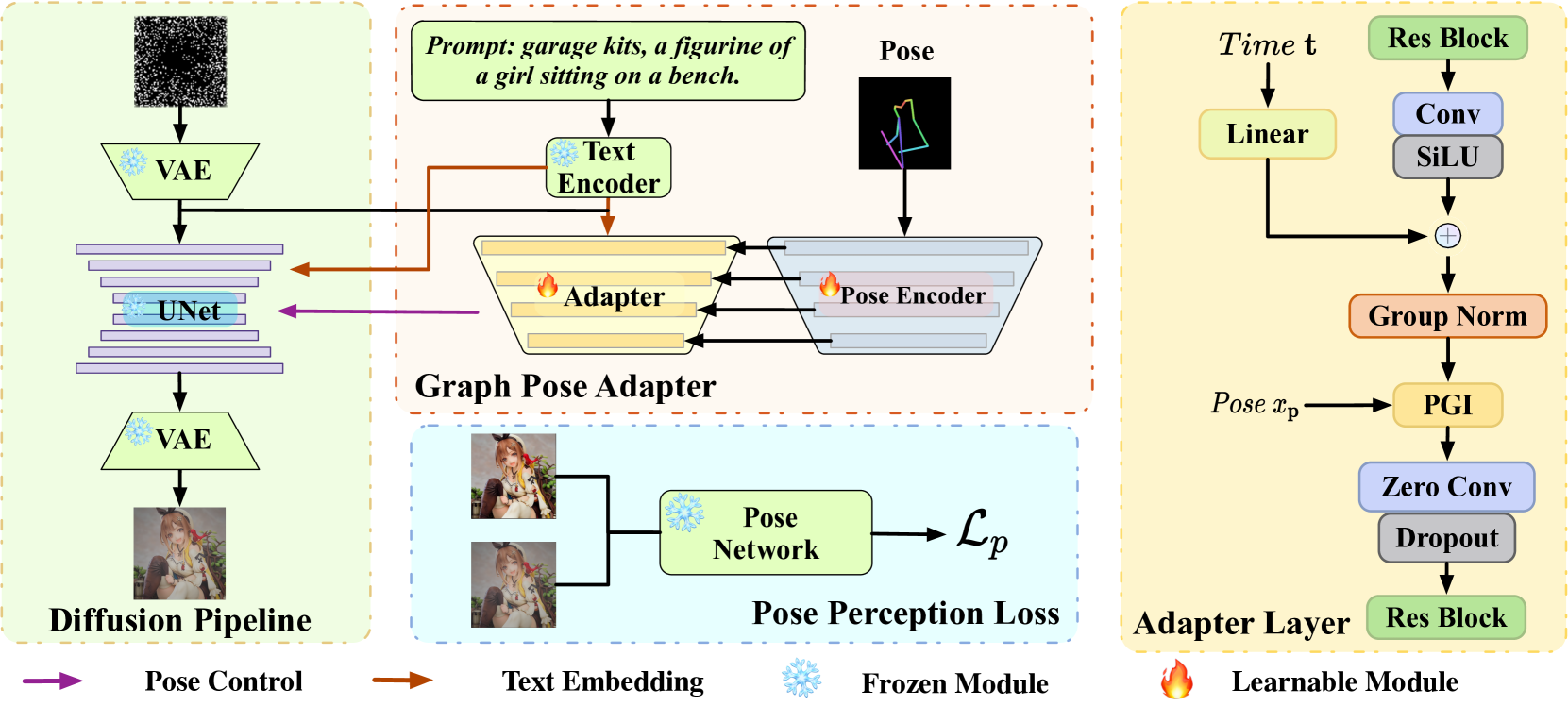
The core of the GRPose approach is a graph convolutional network that learns to represent the spatial and semantic relationships between different body parts. The input to this network is a set of 2D keypoint locations corresponding to the subject's pose.
The graph network propagates information between the keypoints, allowing it to model dependencies such as how the position of the elbow affects the position of the wrist. This learned graph representation is then used to condition the image generation process, ensuring that the final output image has a pose that is coherent and anatomically plausible.
In addition, GRPose leverages language model-derived pose priors to further guide the generation of natural-looking poses. This helps the model avoid unrealistic or impossible poses that may be generated without this additional prior knowledge.
The authors demonstrate that GRPose outperforms previous state-of-the-art methods on standard benchmarks for pose-guided image generation. The generated images show improved realism and fidelity to the target pose, validating the effectiveness of the graph-based approach.
Critical Analysis
One potential limitation of the GRPose method is that it relies on 2D keypoint locations as input, which may not capture all the nuances of 3D human pose. The authors mention that extending the approach to use 3D pose information could further improve the quality of the generated images.
Additionally, the paper does not explore the robustness of GRPose to variations in the input pose, such as noisy or partially occluded keypoints. This could be an important consideration for real-world applications where the input pose may not be perfect.
Finally, while the authors demonstrate strong results on benchmark datasets, it would be valuable to see how GRPose performs on more diverse and challenging datasets that capture a wider range of human poses and appearances.
Conclusion
The GRPose method represents an important advance in the field of pose-guided human image generation. By leveraging a graph neural network to model the complex spatial relationships between body parts, the approach is able to generate realistic and anatomically correct human images.
This work has the potential to benefit a wide range of applications, from virtual character animation to assistive technologies that rely on accurate human pose estimation. As the field of human-centric computer vision continues to evolve, methods like GRPose will play a crucial role in bridging the gap between machine perception and human-like understanding of the body and its movements.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GRPose: Learning Graph Relations for Human Image Generation with Pose Priors
Xiangchen Yin, Donglin Di, Lei Fan, Hao Li, Chen Wei, Xiaofei Gou, Yang Song, Xiao Sun, Xun Yang
Recent methods using diffusion models have made significant progress in human image generation with various additional controls such as pose priors. However, existing approaches still struggle to generate high-quality images with consistent pose alignment, resulting in unsatisfactory outputs. In this paper, we propose a framework delving into the graph relations of pose priors to provide control information for human image generation. The main idea is to establish a graph topological structure between the pose priors and latent representation of diffusion models to capture the intrinsic associations between different pose parts. A Progressive Graph Integrator (PGI) is designed to learn the spatial relationships of the pose priors with the graph structure, adopting a hierarchical strategy within an Adapter to gradually propagate information across different pose parts. A pose perception loss is further introduced based on a pretrained pose estimation network to minimize the pose differences. Extensive qualitative and quantitative experiments conducted on the Human-Art and LAION-Human datasets demonstrate that our model achieves superior performance, with a 9.98% increase in pose average precision compared to the latest benchmark model. The code is released on *******.
Read more8/30/2024

0
PGAHum: Prior-Guided Geometry and Appearance Learning for High-Fidelity Animatable Human Reconstruction
Hao Wang, Qingshan Xu, Hongyuan Chen, Rui Ma
Recent techniques on implicit geometry representation learning and neural rendering have shown promising results for 3D clothed human reconstruction from sparse video inputs. However, it is still challenging to reconstruct detailed surface geometry and even more difficult to synthesize photorealistic novel views with animated human poses. In this work, we introduce PGAHum, a prior-guided geometry and appearance learning framework for high-fidelity animatable human reconstruction. We thoroughly exploit 3D human priors in three key modules of PGAHum to achieve high-quality geometry reconstruction with intricate details and photorealistic view synthesis on unseen poses. First, a prior-based implicit geometry representation of 3D human, which contains a delta SDF predicted by a tri-plane network and a base SDF derived from the prior SMPL model, is proposed to model the surface details and the body shape in a disentangled manner. Second, we introduce a novel prior-guided sampling strategy that fully leverages the prior information of the human pose and body to sample the query points within or near the body surface. By avoiding unnecessary learning in the empty 3D space, the neural rendering can recover more appearance details. Last, we propose a novel iterative backward deformation strategy to progressively find the correspondence for the query point in observation space. A skinning weights prediction model is learned based on the prior provided by the SMPL model to achieve the iterative backward LBS deformation. Extensive quantitative and qualitative comparisons on various datasets are conducted and the results demonstrate the superiority of our framework. Ablation studies also verify the effectiveness of each scheme for geometry and appearance learning.
Read more4/23/2024

0
GUNet: A Graph Convolutional Network United Diffusion Model for Stable and Diversity Pose Generation
Shuowen Liang, Sisi Li, Qingyun Wang, Cen Zhang, Kaiquan Zhu, Tian Yang
Pose skeleton images are an important reference in pose-controllable image generation. In order to enrich the source of skeleton images, recent works have investigated the generation of pose skeletons based on natural language. These methods are based on GANs. However, it remains challenging to perform diverse, structurally correct and aesthetically pleasing human pose skeleton generation with various textual inputs. To address this problem, we propose a framework with GUNet as the main model, PoseDiffusion. It is the first generative framework based on a diffusion model and also contains a series of variants fine-tuned based on a stable diffusion model. PoseDiffusion demonstrates several desired properties that outperform existing methods. 1) Correct Skeletons. GUNet, a denoising model of PoseDiffusion, is designed to incorporate graphical convolutional neural networks. It is able to learn the spatial relationships of the human skeleton by introducing skeletal information during the training process. 2) Diversity. We decouple the key points of the skeleton and characterise them separately, and use cross-attention to introduce textual conditions. Experimental results show that PoseDiffusion outperforms existing SoTA algorithms in terms of stability and diversity of text-driven pose skeleton generation. Qualitative analyses further demonstrate its superiority for controllable generation in Stable Diffusion.
Read more9/19/2024
💬
0
Pose Priors from Language Models
Sanjay Subramanian, Evonne Ng, Lea Muller, Dan Klein, Shiry Ginosar, Trevor Darrell
We present a zero-shot pose optimization method that enforces accurate physical contact constraints when estimating the 3D pose of humans. Our central insight is that since language is often used to describe physical interaction, large pretrained text-based models can act as priors on pose estimation. We can thus leverage this insight to improve pose estimation by converting natural language descriptors, generated by a large multimodal model (LMM), into tractable losses to constrain the 3D pose optimization. Despite its simplicity, our method produces surprisingly compelling pose reconstructions of people in close contact, correctly capturing the semantics of the social and physical interactions. We demonstrate that our method rivals more complex state-of-the-art approaches that require expensive human annotation of contact points and training specialized models. Moreover, unlike previous approaches, our method provides a unified framework for resolving self-contact and person-to-person contact.
Read more5/7/2024