HaLo-NeRF: Learning Geometry-Guided Semantics for Exploring Unconstrained Photo Collections

0
📶
Sign in to get full access
Overview
- This paper explores the potential of using internet image collections, captured by crowds of photographers, to enable digital exploration of large-scale tourist landmarks.
- Prior works have focused primarily on geometric reconstruction and visualization, but have neglected the key role of language in providing a semantic interface for navigation and fine-grained understanding.
- The authors present a localization system that connects neural representations of scenes depicting large-scale landmarks with text describing a semantic region within the scene, by leveraging state-of-the-art vision-and-language models and adapting them to understand landmark scene semantics.
Plain English Explanation
The paper discusses a new approach to exploring and understanding large-scale tourist landmarks using internet image collections. Traditional methods have focused on creating 3D models and visualizations of these landmarks, but have often overlooked the importance of language in helping people navigate and understand the details of these spaces.
The researchers developed a system that can connect visual information from images of landmarks with textual descriptions of specific features or regions within the scene. This is done by using advanced machine learning models that can understand both visual and language data.
To improve the performance of these models, the researchers leveraged large-scale internet data containing images of similar landmarks along with related textual information. The idea is that the connections between the visual and textual data can provide a powerful signal for understanding the semantics of these landmark scenes, even for concepts that may not be fully captured in the original image and text data.
The key innovation is using the spatial relationships between different views of the same scene to guide the localization of semantic concepts described in the text. This allows the system to map these concepts onto a 3D representation of the landmark, providing a more comprehensive and interactive way for people to explore and understand these complex spaces.
Technical Explanation
The paper presents a localization system that connects neural representations of scenes depicting large-scale landmarks with text describing a semantic region within the scene. This is achieved by leveraging state-of-the-art vision-and-language models and adapting them to understand landmark scene semantics.
To bolster these models with fine-grained knowledge, the researchers leverage large-scale internet data containing images of similar landmarks along with weakly-related textual information. The premise is that images physically grounded in space can provide a powerful supervision signal for localizing new concepts, whose semantics may be unlocked from internet textual metadata using large language models.
The system uses correspondences between views of scenes to bootstrap spatial understanding of these semantics, providing guidance for 3D-compatible segmentation that ultimately lifts to a volumetric scene representation. This approach, called HaLo-NeRF, allows the accurate localization of a variety of semantic concepts related to architectural landmarks, surpassing the results of other 3D models as well as strong 2D segmentation baselines.
Critical Analysis
The paper presents a novel approach to leveraging internet image collections and language data to enable a more comprehensive and interactive understanding of large-scale landmarks. However, the authors acknowledge that their system is still limited in its ability to handle the full complexity and diversity of real-world landmark scenes.
One potential issue is that the system relies heavily on the availability and quality of the internet data used to train the models. If the data is biased or incomplete, it could lead to blind spots or inaccuracies in the system's understanding of landmark semantics.
Additionally, the paper does not fully address the challenge of scaling this approach to handle a broader range of landmark types and locations. The experiments are focused on a relatively constrained set of architectural landmarks, and it's unclear how well the system would perform on more diverse or abstract landmark types.
Further research is needed to explore the generalizability of this approach, as well as to investigate ways to improve the robustness and reliability of the language-based localization and understanding capabilities. Incorporating additional data sources, such as crowdsourced annotations or expert knowledge, could be a promising direction for enhancing the system's capabilities.
Conclusion
This paper presents a novel approach to leveraging internet image collections and language data to enable a more comprehensive and interactive understanding of large-scale landmarks. By connecting visual representations of scenes with textual descriptions of semantic regions, the researchers have developed a system that can accurately localize a variety of architectural concepts.
While the system has limitations in its ability to handle the full complexity of real-world landmark scenes, the core idea of using spatially grounded visual data and language models to bootstrap fine-grained semantic understanding is a promising direction for the field of computer vision and language understanding. This work highlights the potential of integrating multiple modalities to unlock new capabilities in digital exploration and understanding of the physical world.
As research in this area continues to evolve, we can expect to see increasingly sophisticated systems that can seamlessly bridge the gap between visual and textual representations, empowering users to explore and interact with large-scale environments in more intuitive and meaningful ways.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📶
0
HaLo-NeRF: Learning Geometry-Guided Semantics for Exploring Unconstrained Photo Collections
Chen Dudai, Morris Alper, Hana Bezalel, Rana Hanocka, Itai Lang, Hadar Averbuch-Elor
Internet image collections containing photos captured by crowds of photographers show promise for enabling digital exploration of large-scale tourist landmarks. However, prior works focus primarily on geometric reconstruction and visualization, neglecting the key role of language in providing a semantic interface for navigation and fine-grained understanding. In constrained 3D domains, recent methods have leveraged vision-and-language models as a strong prior of 2D visual semantics. While these models display an excellent understanding of broad visual semantics, they struggle with unconstrained photo collections depicting such tourist landmarks, as they lack expert knowledge of the architectural domain. In this work, we present a localization system that connects neural representations of scenes depicting large-scale landmarks with text describing a semantic region within the scene, by harnessing the power of SOTA vision-and-language models with adaptations for understanding landmark scene semantics. To bolster such models with fine-grained knowledge, we leverage large-scale Internet data containing images of similar landmarks along with weakly-related textual information. Our approach is built upon the premise that images physically grounded in space can provide a powerful supervision signal for localizing new concepts, whose semantics may be unlocked from Internet textual metadata with large language models. We use correspondences between views of scenes to bootstrap spatial understanding of these semantics, providing guidance for 3D-compatible segmentation that ultimately lifts to a volumetric scene representation. Our results show that HaLo-NeRF can accurately localize a variety of semantic concepts related to architectural landmarks, surpassing the results of other 3D models as well as strong 2D segmentation baselines. Our project page is at https://tau-vailab.github.io/HaLo-NeRF/.
Read more4/29/2024

0
HarmonicNeRF: Geometry-Informed Synthetic View Augmentation for 3D Scene Reconstruction in Driving Scenarios
Xiaochao Pan, Jiawei Yao, Hongrui Kou, Tong Wu, Canran Xiao
In the realm of autonomous driving, achieving precise 3D reconstruction of the driving environment is critical for ensuring safety and effective navigation. Neural Radiance Fields (NeRF) have shown promise in creating highly detailed and accurate models of complex environments. However, the application of NeRF in autonomous driving scenarios encounters several challenges, primarily due to the sparsity of viewpoints inherent in camera trajectories and the constraints on data collection in unbounded outdoor scenes, which typically occur along predetermined paths. This limitation not only reduces the available scene information but also poses significant challenges for NeRF training, as the sparse and path-distributed observational data leads to under-representation of the scene's geometry. In this paper, we introduce HarmonicNeRF, a novel approach for outdoor self-supervised monocular scene reconstruction. HarmonicNeRF capitalizes on the strengths of NeRF and enhances surface reconstruction accuracy by augmenting the input space with geometry-informed synthetic views. This is achieved through the application of spherical harmonics to generate novel radiance values, taking into careful consideration the color observations from the limited available real-world views. Additionally, our method incorporates proxy geometry to effectively manage occlusion, generating radiance pseudo-labels that circumvent the limitations of traditional image-warping techniques, which often fail in sparse data conditions typical of autonomous driving environments. Extensive experiments conducted on the KITTI, Argoverse, and NuScenes datasets demonstrate our approach establishes new benchmarks in synthesizing novel depth views and reconstructing scenes, significantly outperforming existing methods. Project page: https://github.com/Jiawei-Yao0812/HarmonicNeRF
Read more7/26/2024
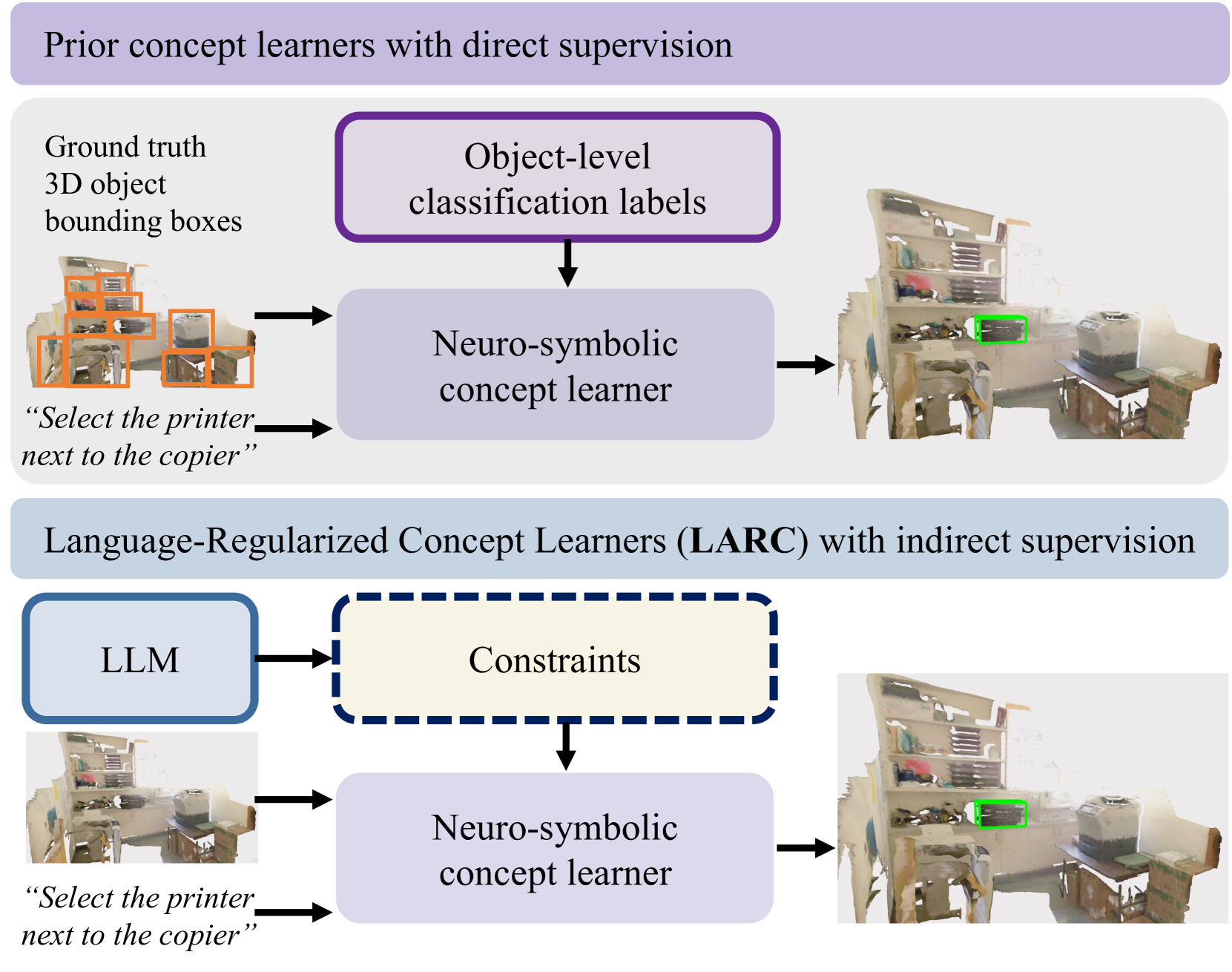
0
Naturally Supervised 3D Visual Grounding with Language-Regularized Concept Learners
Chun Feng, Joy Hsu, Weiyu Liu, Jiajun Wu
3D visual grounding is a challenging task that often requires direct and dense supervision, notably the semantic label for each object in the scene. In this paper, we instead study the naturally supervised setting that learns from only 3D scene and QA pairs, where prior works underperform. We propose the Language-Regularized Concept Learner (LARC), which uses constraints from language as regularization to significantly improve the accuracy of neuro-symbolic concept learners in the naturally supervised setting. Our approach is based on two core insights: the first is that language constraints (e.g., a word's relation to another) can serve as effective regularization for structured representations in neuro-symbolic models; the second is that we can query large language models to distill such constraints from language properties. We show that LARC improves performance of prior works in naturally supervised 3D visual grounding, and demonstrates a wide range of 3D visual reasoning capabilities-from zero-shot composition, to data efficiency and transferability. Our method represents a promising step towards regularizing structured visual reasoning frameworks with language-based priors, for learning in settings without dense supervision.
Read more5/1/2024

0
Rethinking Open-Vocabulary Segmentation of Radiance Fields in 3D Space
Hyunjee Lee, Youngsik Yun, Jeongmin Bae, Seoha Kim, Youngjung Uh
Understanding the 3D semantics of a scene is a fundamental problem for various scenarios such as embodied agents. While NeRFs and 3DGS excel at novel-view synthesis, previous methods for understanding their semantics have been limited to incomplete 3D understanding: their segmentation results are 2D masks and their supervision is anchored at 2D pixels. This paper revisits the problem set to pursue a better 3D understanding of a scene modeled by NeRFs and 3DGS as follows. 1) We directly supervise the 3D points to train the language embedding field. It achieves state-of-the-art accuracy without relying on multi-scale language embeddings. 2) We transfer the pre-trained language field to 3DGS, achieving the first real-time rendering speed without sacrificing training time or accuracy. 3) We introduce a 3D querying and evaluation protocol for assessing the reconstructed geometry and semantics together. Code, checkpoints, and annotations will be available online. Project page: https://hyunji12.github.io/Open3DRF
Read more8/20/2024