Hardware Acceleration for Knowledge Graph Processing: Challenges & Recent Developments

0
Sign in to get full access
Overview
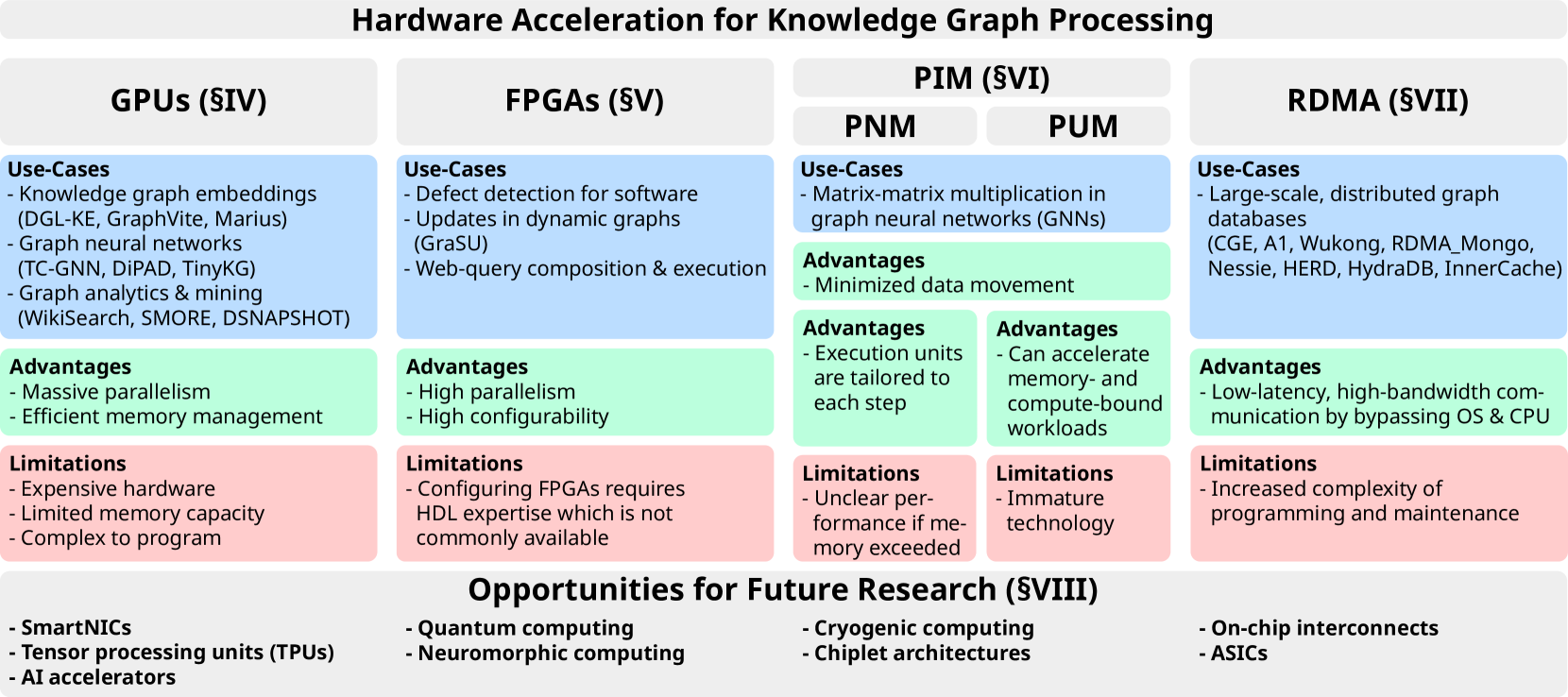
- Provides a systematic literature review on the challenges and recent developments in hardware acceleration for knowledge graph processing
- Explores the use of various hardware architectures, including CPUs, GPUs, FPGAs, and ASICs, to accelerate knowledge graph algorithms
- Discusses the trade-offs and performance considerations of these different hardware platforms
Plain English Explanation
Knowledge graphs are powerful tools for representing and analyzing complex relationships between data. However, processing large knowledge graphs can be computationally intensive, requiring significant time and resources. To address this challenge, researchers have explored the use of hardware acceleration to speed up knowledge graph processing.
In this review paper, the authors examine the current state of hardware acceleration for knowledge graphs. They explore the various hardware architectures that have been explored, including CPUs, GPUs, FPGAs, and ASICs. Each of these hardware platforms has its own strengths and weaknesses, and the authors discuss the trade-offs and performance considerations for using these different technologies to accelerate knowledge graph processing.
The paper also covers recent advancements in the field, such as the development of novel algorithms and techniques specifically designed for hardware-accelerated knowledge graph processing. These developments have the potential to significantly improve the efficiency and scalability of knowledge graph applications, making them more accessible and useful for a wider range of users and applications.
Technical Explanation
The paper presents a comprehensive systematic literature review on the challenges and recent developments in hardware acceleration for knowledge graph processing. The authors first provide an overview of knowledge graphs and their importance in various domains, as well as the computational challenges associated with processing large-scale knowledge graphs.
The paper then delves into the different hardware architectures that have been explored for accelerating knowledge graph algorithms, including CPUs, GPUs, FPGAs, and ASICs. For each hardware platform, the authors discuss the performance characteristics, trade-offs, and recent advancements in hardware-accelerated knowledge graph processing.
The paper also covers novel algorithms and techniques that have been developed to leverage these hardware architectures, such as graph partitioning, data layout optimization, and task-specific accelerator design. These advancements have the potential to significantly improve the efficiency and scalability of knowledge graph applications.
Critical Analysis
The paper provides a comprehensive and well-structured overview of the challenges and recent developments in hardware acceleration for knowledge graph processing. The authors have done a thorough job of surveying the existing literature and highlighting the key trade-offs and performance considerations for different hardware architectures.
One potential limitation of the paper is that it focuses primarily on the technical aspects of hardware acceleration, without delving too deeply into the practical implications or real-world applications of these technologies. Further research could explore the use cases and potential impact of hardware-accelerated knowledge graph processing in various domains, such as medical research, scientific discovery, or business intelligence.
Additionally, the paper could have discussed the potential challenges and limitations of the reviewed hardware architectures, such as power consumption, cost, and scalability, to provide a more balanced perspective.
Conclusion
This review paper provides a comprehensive overview of the challenges and recent developments in hardware acceleration for knowledge graph processing. The authors have explored the various hardware architectures, including CPUs, GPUs, FPGAs, and ASICs, and discussed their trade-offs and performance characteristics. The paper also covers novel algorithms and techniques that have been developed to leverage these hardware platforms, highlighting the potential for significant improvements in the efficiency and scalability of knowledge graph applications.
While the paper focuses primarily on the technical aspects, the insights and findings presented could have important implications for the broader field of knowledge graph research and applications. Further exploration of the practical use cases and potential impact of hardware-accelerated knowledge graph processing could be a valuable area for future research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Hardware Acceleration for Knowledge Graph Processing: Challenges & Recent Developments
Maciej Besta, Robert Gerstenberger, Patrick Iff, Pournima Sonawane, Juan G'omez Luna, Raghavendra Kanakagiri, Rui Min, Onur Mutlu, Torsten Hoefler, Raja Appuswamy, Aidan O Mahony
Knowledge graphs (KGs) have achieved significant attention in recent years, particularly in the area of the Semantic Web as well as gaining popularity in other application domains such as data mining and search engines. Simultaneously, there has been enormous progress in the development of different types of heterogeneous hardware, impacting the way KGs are processed. The aim of this paper is to provide a systematic literature review of knowledge graph hardware acceleration. For this, we present a classification of the primary areas in knowledge graph technology that harnesses different hardware units for accelerating certain knowledge graph functionalities. We then extensively describe respective works, focusing on how KG related schemes harness modern hardware accelerators. Based on our review, we identify various research gaps and future exploratory directions that are anticipated to be of significant value both for academics and industry practitioners.
Read more8/23/2024
0
Enabling Accelerators for Graph Computing
Kaustubh Shivdikar
The advent of Graph Neural Networks (GNNs) has revolutionized the field of machine learning, offering a novel paradigm for learning on graph-structured data. Unlike traditional neural networks, GNNs are capable of capturing complex relationships and dependencies inherent in graph data, making them particularly suited for a wide range of applications including social network analysis, molecular chemistry, and network security. GNNs, with their unique structure and operation, present new computational challenges compared to conventional neural networks. This requires comprehensive benchmarking and a thorough characterization of GNNs to obtain insight into their computational requirements and to identify potential performance bottlenecks. In this thesis, we aim to develop a better understanding of how GNNs interact with the underlying hardware and will leverage this knowledge as we design specialized accelerators and develop new optimizations, leading to more efficient and faster GNN computations. A pivotal component within GNNs is the Sparse General Matrix-Matrix Multiplication (SpGEMM) kernel, known for its computational intensity and irregular memory access patterns. In this thesis, we address the challenges posed by SpGEMM by implementing a highly optimized hashing-based SpGEMM kernel tailored for a custom accelerator. Synthesizing these insights and optimizations, we design state-of-the-art hardware accelerators capable of efficiently handling various GNN workloads. Our accelerator architectures are built on our characterization of GNN computational demands, providing clear motivation for our approaches. This exploration into novel models underlines our comprehensive approach, as we strive to enable accelerators that are not just performant, but also versatile, able to adapt to the evolving landscape of graph computing.
Read more5/7/2024
🤿
0
A Survey on Deep Learning Hardware Accelerators for Heterogeneous HPC Platforms
Cristina Silvano, Daniele Ielmini, Fabrizio Ferrandi, Leandro Fiorin, Serena Curzel, Luca Benini, Francesco Conti, Angelo Garofalo, Cristian Zambelli, Enrico Calore, Sebastiano Fabio Schifano, Maurizio Palesi, Giuseppe Ascia, Davide Patti, Nicola Petra, Davide De Caro, Luciano Lavagno, Teodoro Urso, Valeria Cardellini, Gian Carlo Cardarilli, Robert Birke, Stefania Perri
Recent trends in deep learning (DL) imposed hardware accelerators as the most viable solution for several classes of high-performance computing (HPC) applications such as image classification, computer vision, and speech recognition. This survey summarizes and classifies the most recent advances in designing DL accelerators suitable to reach the performance requirements of HPC applications. In particular, it highlights the most advanced approaches to support deep learning accelerations including not only GPU and TPU-based accelerators but also design-specific hardware accelerators such as FPGA-based and ASIC-based accelerators, Neural Processing Units, open hardware RISC-V-based accelerators and co-processors. The survey also describes accelerators based on emerging memory technologies and computing paradigms, such as 3D-stacked Processor-In-Memory, non-volatile memories (mainly, Resistive RAM and Phase Change Memories) to implement in-memory computing, Neuromorphic Processing Units, and accelerators based on Multi-Chip Modules. Among emerging technologies, we also include some insights into quantum-based accelerators and photonics. To conclude, the survey classifies the most influential architectures and technologies proposed in the last years, with the purpose of offering the reader a comprehensive perspective in the rapidly evolving field of deep learning.
Read more7/15/2024

0
Acceleration Algorithms in GNNs: A Survey
Lu Ma, Zeang Sheng, Xunkai Li, Xinyi Gao, Zhezheng Hao, Ling Yang, Wentao Zhang, Bin Cui
Graph Neural Networks (GNNs) have demonstrated effectiveness in various graph-based tasks. However, their inefficiency in training and inference presents challenges for scaling up to real-world and large-scale graph applications. To address the critical challenges, a range of algorithms have been proposed to accelerate training and inference of GNNs, attracting increasing attention from the research community. In this paper, we present a systematic review of acceleration algorithms in GNNs, which can be categorized into three main topics based on their purpose: training acceleration, inference acceleration, and execution acceleration. Specifically, we summarize and categorize the existing approaches for each main topic, and provide detailed characterizations of the approaches within each category. Additionally, we review several libraries related to acceleration algorithms in GNNs and discuss our Scalable Graph Learning (SGL) library. Finally, we propose promising directions for future research. A complete summary is presented in our GitHub repository: https://github.com/PKU-DAIR/SGL/blob/main/Awsome-GNN-Acceleration.md.
Read more5/8/2024