Progressive Knowledge Graph Completion
2404.09897
0
0
Abstract
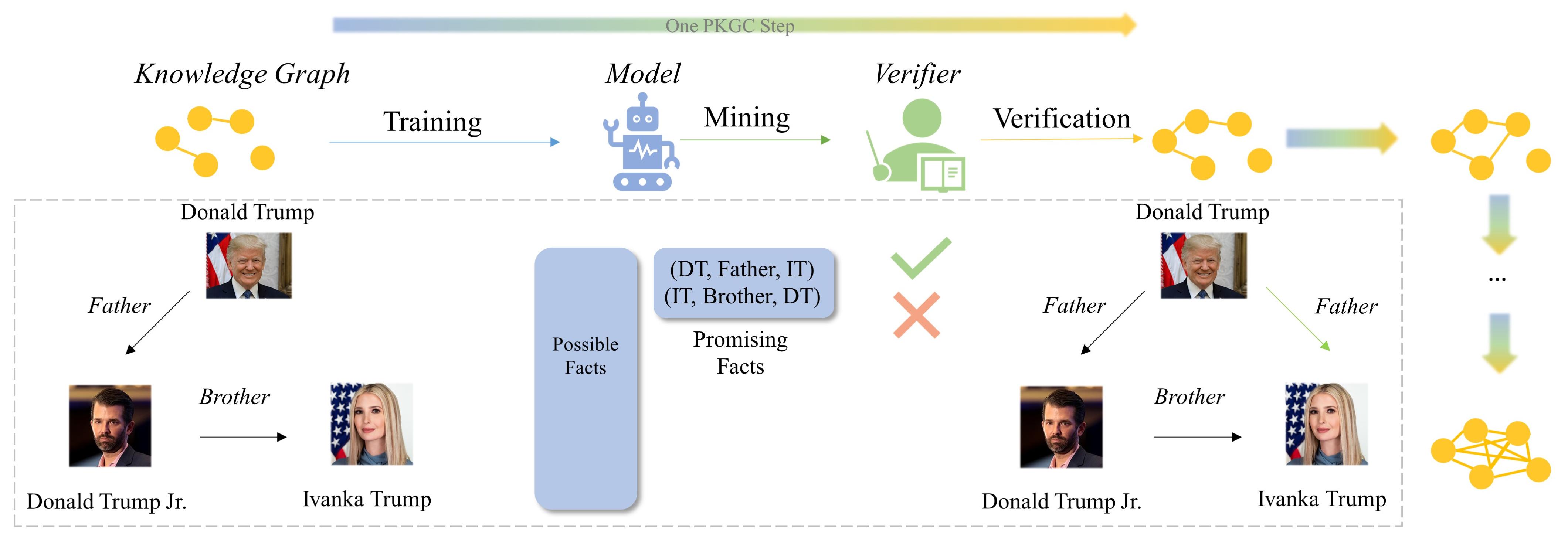
Knowledge Graph Completion (KGC) has emerged as a promising solution to address the issue of incompleteness within Knowledge Graphs (KGs). Traditional KGC research primarily centers on triple classification and link prediction. Nevertheless, we contend that these tasks do not align well with real-world scenarios and merely serve as surrogate benchmarks. In this paper, we investigate three crucial processes relevant to real-world construction scenarios: (a) the verification process, which arises from the necessity and limitations of human verifiers; (b) the mining process, which identifies the most promising candidates for verification; and (c) the training process, which harnesses verified data for subsequent utilization; in order to achieve a transition toward more realistic challenges. By integrating these three processes, we introduce the Progressive Knowledge Graph Completion (PKGC) task, which simulates the gradual completion of KGs in real-world scenarios. Furthermore, to expedite PKGC processing, we propose two acceleration modules: Optimized Top-$k$ algorithm and Semantic Validity Filter. These modules significantly enhance the efficiency of the mining procedure. Our experiments demonstrate that performance in link prediction does not accurately reflect performance in PKGC. A more in-depth analysis reveals the key factors influencing the results and provides potential directions for future research.
Create account to get full access
Overview
- This paper presents a novel technique called "Progressive Knowledge Graph Completion" for improving the performance of knowledge graph embedding models.
- The approach involves gradually incorporating additional information into the model during training, allowing it to learn more effectively and achieve better results on knowledge graph completion tasks.
- The authors demonstrate the effectiveness of their method through experiments on several standard knowledge graph datasets.
Plain English Explanation
Knowledge graphs are computer-readable representations of information that capture the relationships between different entities, like people, places, and concepts. They are used in a variety of applications, such as recommender systems and question-answering systems.
One challenge in working with knowledge graphs is that they are often incomplete, missing many of the connections between entities. The goal of knowledge graph completion is to use machine learning techniques to infer these missing links, allowing the knowledge graph to become more comprehensive and useful.
The authors of this paper propose a new approach called "Progressive Knowledge Graph Completion" that aims to improve the performance of knowledge graph embedding models, which are a common way of representing knowledge graphs in machine learning. The key idea is to gradually incorporate additional information into the model during the training process, rather than trying to learn everything at once. This allows the model to learn more effectively and achieve better results on knowledge graph completion tasks.
Technical Explanation
The core of the authors' approach is a "progressive" training strategy that gradually expands the information used by the knowledge graph embedding model. The process begins by training the model on a small subset of the knowledge graph, focusing on the most essential entities and relationships. Over time, the model is then exposed to more and more of the graph, allowing it to progressively learn a richer and more comprehensive representation.
The authors evaluate their method on several standard knowledge graph datasets, including FB15k-237 and WN18RR. They compare the performance of their progressive approach to that of traditional knowledge graph embedding techniques, and demonstrate that their method achieves significantly better results on link prediction and other knowledge graph completion tasks.
The authors also analyze the impact of different hyperparameters and design choices on the performance of their progressive training strategy, providing insights that could inform the development of future knowledge graph completion systems.
Critical Analysis
One potential limitation of the progressive training approach is that it may require more computational resources and training time than traditional knowledge graph embedding techniques, as the model needs to be trained in multiple stages. The authors do not provide a detailed comparison of the computational costs of their method.
Additionally, the authors only evaluate their approach on a few standard knowledge graph datasets, and it's unclear how it would perform on more complex or domain-specific knowledge graphs. Further research would be needed to assess the generalizability of the progressive training strategy.
Overall, the authors present a promising new technique for improving the performance of knowledge graph embedding models, with potential applications in a variety of domains that rely on knowledge graphs, such as natural language processing and recommender systems. The progressive training approach is an interesting contribution to the ongoing efforts to make large language models perform better with knowledge and to explore connected subgraph explanations in knowledge graphs.
Conclusion
The "Progressive Knowledge Graph Completion" technique proposed in this paper represents a promising new approach to improving the performance of knowledge graph embedding models. By gradually incorporating additional information into the model during training, the authors demonstrate that their method can achieve better results on knowledge graph completion tasks compared to traditional techniques.
While the authors have identified some potential limitations of their approach, the overall concept and results are compelling. The progressive training strategy could have significant implications for a wide range of applications that rely on knowledge graphs, from recommender systems to question-answering systems. Further research and development in this area may lead to even more advanced and effective knowledge graph completion models in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Multi-level Shared Knowledge Guided Learning for Knowledge Graph Completion
Yongxue Shan, Jie Zhou, Jie Peng, Xin Zhou, Jiaqian Yin, Xiaodong Wang
0
0
In the task of Knowledge Graph Completion (KGC), the existing datasets and their inherent subtasks carry a wealth of shared knowledge that can be utilized to enhance the representation of knowledge triplets and overall performance. However, no current studies specifically address the shared knowledge within KGC. To bridge this gap, we introduce a multi-level Shared Knowledge Guided learning method (SKG) that operates at both the dataset and task levels. On the dataset level, SKG-KGC broadens the original dataset by identifying shared features within entity sets via text summarization. On the task level, for the three typical KGC subtasks - head entity prediction, relation prediction, and tail entity prediction - we present an innovative multi-task learning architecture with dynamically adjusted loss weights. This approach allows the model to focus on more challenging and underperforming tasks, effectively mitigating the imbalance of knowledge sharing among subtasks. Experimental results demonstrate that SKG-KGC outperforms existing text-based methods significantly on three well-known datasets, with the most notable improvement on WN18RR.
5/14/2024

Towards Better Benchmark Datasets for Inductive Knowledge Graph Completion
Harry Shomer, Jay Revolinsky, Jiliang Tang
0
0
Knowledge Graph Completion (KGC) attempts to predict missing facts in a Knowledge Graph (KG). Recently, there's been an increased focus on designing KGC methods that can excel in the {it inductive setting}, where a portion or all of the entities and relations seen in inference are unobserved during training. Numerous benchmark datasets have been proposed for inductive KGC, all of which are subsets of existing KGs used for transductive KGC. However, we find that the current procedure for constructing inductive KGC datasets inadvertently creates a shortcut that can be exploited even while disregarding the relational information. Specifically, we observe that the Personalized PageRank (PPR) score can achieve strong or near SOTA performance on most inductive datasets. In this paper, we study the root cause of this problem. Using these insights, we propose an alternative strategy for constructing inductive KGC datasets that helps mitigate the PPR shortcut. We then benchmark multiple popular methods using the newly constructed datasets and analyze their performance. The new benchmark datasets help promote a better understanding of the capabilities and challenges of inductive KGC by removing any shortcuts that obfuscate performance.
6/19/2024

Multilingual Knowledge Graph Completion from Pretrained Language Models with Knowledge Constraints
Ran Song, Shizhu He, Shengxiang Gao, Li Cai, Kang Liu, Zhengtao Yu, Jun Zhao
0
0
Multilingual Knowledge Graph Completion (mKGC) aim at solving queries like (h, r, ?) in different languages by reasoning a tail entity t thus improving multilingual knowledge graphs. Previous studies leverage multilingual pretrained language models (PLMs) and the generative paradigm to achieve mKGC. Although multilingual pretrained language models contain extensive knowledge of different languages, its pretraining tasks cannot be directly aligned with the mKGC tasks. Moreover, the majority of KGs and PLMs currently available exhibit a pronounced English-centric bias. This makes it difficult for mKGC to achieve good results, particularly in the context of low-resource languages. To overcome previous problems, this paper introduces global and local knowledge constraints for mKGC. The former is used to constrain the reasoning of answer entities, while the latter is used to enhance the representation of query contexts. The proposed method makes the pretrained model better adapt to the mKGC task. Experimental results on public datasets demonstrate that our method outperforms the previous SOTA on Hits@1 and Hits@10 by an average of 12.32% and 16.03%, which indicates that our proposed method has significant enhancement on mKGC.
6/27/2024
💬
Does Pre-trained Language Model Actually Infer Unseen Links in Knowledge Graph Completion?
Yusuke Sakai, Hidetaka Kamigaito, Katsuhiko Hayashi, Taro Watanabe
0
0
Knowledge graphs (KGs) consist of links that describe relationships between entities. Due to the difficulty of manually enumerating all relationships between entities, automatically completing them is essential for KGs. Knowledge Graph Completion (KGC) is a task that infers unseen relationships between entities in a KG. Traditional embedding-based KGC methods, such as RESCAL, TransE, DistMult, ComplEx, RotatE, HAKE, HousE, etc., infer missing links using only the knowledge from training data. In contrast, the recent Pre-trained Language Model (PLM)-based KGC utilizes knowledge obtained during pre-training. Therefore, PLM-based KGC can estimate missing links between entities by reusing memorized knowledge from pre-training without inference. This approach is problematic because building KGC models aims to infer unseen links between entities. However, conventional evaluations in KGC do not consider inference and memorization abilities separately. Thus, a PLM-based KGC method, which achieves high performance in current KGC evaluations, may be ineffective in practical applications. To address this issue, we analyze whether PLM-based KGC methods make inferences or merely access memorized knowledge. For this purpose, we propose a method for constructing synthetic datasets specified in this analysis and conclude that PLMs acquire the inference abilities required for KGC through pre-training, even though the performance improvements mostly come from textual information of entities and relations.
6/7/2024