Harnessing Density Ratios for Online Reinforcement Learning

0
🏅
Sign in to get full access
Overview
- This paper proposes a novel online reinforcement learning (RL) algorithm that leverages density ratios to adapt to changing environments.
- The key idea is to use density ratios to estimate the importance of past experiences, allowing the agent to focus on relevant data and learn more efficiently.
- The approach is validated through experiments on several benchmark reinforcement learning tasks, demonstrating improved performance over existing online RL methods.
Plain English Explanation
In the world of reinforcement learning, agents (like AI systems) learn by interacting with their environment and receiving rewards or punishments for their actions. However, real-world environments are often dynamic and can change over time, which can make it challenging for agents to learn effectively.
This paper introduces a new approach to online reinforcement learning that aims to address this challenge. The key insight is to use density ratios to keep track of how relevant past experiences are to the agent's current situation. Density ratios are a way of measuring the similarity between two probability distributions, which in this case corresponds to how similar the current environment is to the environment the agent has seen in the past.
By using density ratios, the agent can focus on the most relevant past experiences and learn more efficiently, even as the environment changes. The researchers demonstrate the effectiveness of this approach through experiments on various reinforcement learning tasks, showing that it outperforms existing online RL methods.
The advantage of this approach is that it allows the agent to adapt to changing conditions more effectively, which is important in many real-world applications where the environment is constantly evolving. By harnessing the power of density ratios, the agent can learn more quickly and make better decisions, even in the face of continuous change.
Technical Explanation
The paper proposes a novel online reinforcement learning algorithm called Density Ratio Reinforcement Learning (DRRL), which leverages density ratios to adapt to changing environments.
The key idea behind DRRL is to use density ratios to estimate the importance of past experiences, allowing the agent to focus on the most relevant data and learn more efficiently. Specifically, the agent maintains a density ratio model that estimates the likelihood of the current state-action pair relative to the distribution of past experiences. This density ratio is then used to weight the contribution of each past experience when updating the agent's value function or policy.
The density ratio model is updated online using a rejection-based density ratio estimation technique, which allows the agent to adapt to changes in the environment without requiring any additional information about the nature of the change.
The authors evaluate DRRL on several benchmark reinforcement learning tasks, including Adapting to Continuous Covariate Shift via Online Learning, Rejection via Learning Density Ratios, Understanding the Performance Gap Between Online and Offline Alignment, Generative Modeling by Flow-Guided Density Ratio Learning, and Offline Reinforcement Learning from Imbalanced Datasets. The results demonstrate that DRRL outperforms existing online RL methods, particularly in environments with significant distribution shift.
Critical Analysis
The paper provides a compelling approach to online reinforcement learning that leverages density ratios to adapt to changing environments. The key strength of the DRRL algorithm is its ability to focus on the most relevant past experiences, which is particularly important in dynamic real-world settings.
One potential limitation of the approach is that it relies on the accurate estimation of density ratios, which can be challenging in high-dimensional or complex environments. The authors acknowledge this challenge and propose a rejection-based technique to address it, but further research may be needed to improve the robustness of the density ratio estimation process.
Additionally, the paper does not explore the potential for DRRL to be combined with other online RL techniques, such as meta-learning or transfer learning, which could further enhance its performance in the face of continuous distribution shift. Investigating such hybrid approaches could be a fruitful area for future research.
Overall, the paper makes a significant contribution to the field of online reinforcement learning and demonstrates the value of leveraging density ratios to improve adaptability in dynamic environments. The insights presented in this work could inspire further advancements in this important area of research.
Conclusion
The "Harnessing Density Ratios for Online Reinforcement Learning" paper introduces a novel online RL algorithm that leverages density ratios to adapt to changing environments. By using density ratios to estimate the importance of past experiences, the DRRL agent can focus on the most relevant data and learn more efficiently, even as the environment evolves.
The experimental results show that DRRL outperforms existing online RL methods, particularly in scenarios with significant distribution shift. This suggests that the density ratio-based approach could be a valuable tool for developing robust and adaptable reinforcement learning systems that can thrive in dynamic, real-world settings.
Overall, this work represents an important step forward in the field of online reinforcement learning and highlights the potential of density ratios to address the challenges of learning in non-stationary environments. The insights and techniques presented in this paper could inspire further research and development in this critical area of AI and machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
Harnessing Density Ratios for Online Reinforcement Learning
Philip Amortila, Dylan J. Foster, Nan Jiang, Ayush Sekhari, Tengyang Xie
The theories of offline and online reinforcement learning, despite having evolved in parallel, have begun to show signs of the possibility for a unification, with algorithms and analysis techniques for one setting often having natural counterparts in the other. However, the notion of density ratio modeling, an emerging paradigm in offline RL, has been largely absent from online RL, perhaps for good reason: the very existence and boundedness of density ratios relies on access to an exploratory dataset with good coverage, but the core challenge in online RL is to collect such a dataset without having one to start. In this work we show -- perhaps surprisingly -- that density ratio-based algorithms have online counterparts. Assuming only the existence of an exploratory distribution with good coverage, a structural condition known as coverability (Xie et al., 2023), we give a new algorithm (GLOW) that uses density ratio realizability and value function realizability to perform sample-efficient online exploration. GLOW addresses unbounded density ratios via careful use of truncation, and combines this with optimism to guide exploration. GLOW is computationally inefficient; we complement it with a more efficient counterpart, HyGLOW, for the Hybrid RL setting (Song et al., 2022) wherein online RL is augmented with additional offline data. HyGLOW is derived as a special case of a more general meta-algorithm that provides a provable black-box reduction from hybrid RL to offline RL, which may be of independent interest.
Read more6/6/2024

0
A Density Ratio Super Learner
Wencheng Wu, David Benkeser
The estimation of the ratio of two density probability functions is of great interest in many statistics fields, including causal inference. In this study, we develop an ensemble estimator of density ratios with a novel loss function based on super learning. We show that this novel loss function is qualified for building super learners. Two simulations corresponding to mediation analysis and longitudinal modified treatment policy in causal inference, where density ratios are nuisance parameters, are conducted to show our density ratio super learner's performance empirically.
Read more8/12/2024
🔗
0
Adapting to Continuous Covariate Shift via Online Density Ratio Estimation
Yu-Jie Zhang, Zhen-Yu Zhang, Peng Zhao, Masashi Sugiyama
Dealing with distribution shifts is one of the central challenges for modern machine learning. One fundamental situation is the covariate shift, where the input distributions of data change from training to testing stages while the input-conditional output distribution remains unchanged. In this paper, we initiate the study of a more challenging scenario -- continuous covariate shift -- in which the test data appear sequentially, and their distributions can shift continuously. Our goal is to adaptively train the predictor such that its prediction risk accumulated over time can be minimized. Starting with the importance-weighted learning, we show the method works effectively if the time-varying density ratios of test and train inputs can be accurately estimated. However, existing density ratio estimation methods would fail due to data scarcity at each time step. To this end, we propose an online method that can appropriately reuse historical information. Our density ratio estimation method is proven to perform well by enjoying a dynamic regret bound, which finally leads to an excess risk guarantee for the predictor. Empirical results also validate the effectiveness.
Read more5/28/2024
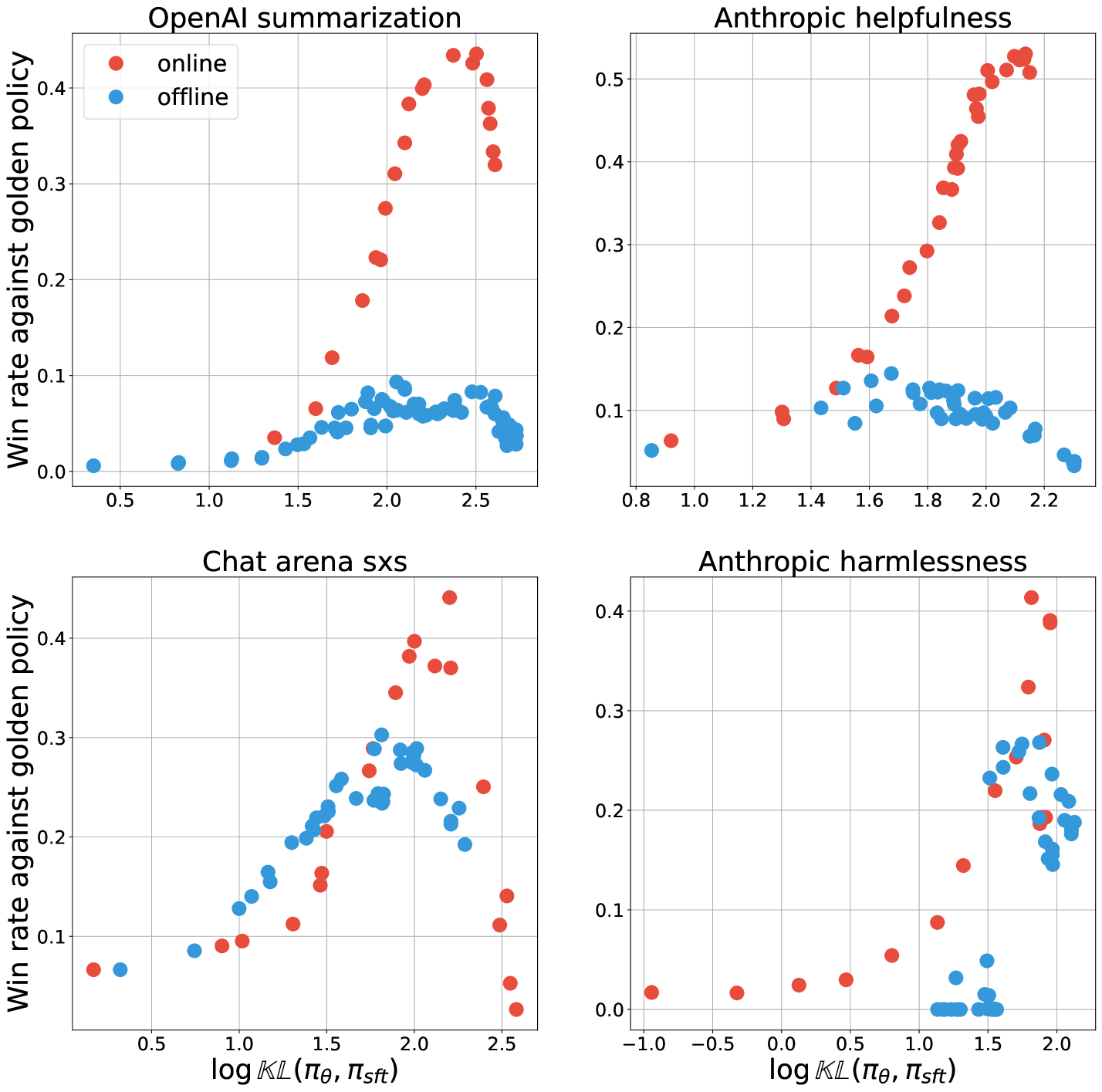
0
Understanding the performance gap between online and offline alignment algorithms
Yunhao Tang, Daniel Zhaohan Guo, Zeyu Zheng, Daniele Calandriello, Yuan Cao, Eugene Tarassov, R'emi Munos, Bernardo 'Avila Pires, Michal Valko, Yong Cheng, Will Dabney
Reinforcement learning from human feedback (RLHF) is the canonical framework for large language model alignment. However, rising popularity in offline alignment algorithms challenge the need for on-policy sampling in RLHF. Within the context of reward over-optimization, we start with an opening set of experiments that demonstrate the clear advantage of online methods over offline methods. This prompts us to investigate the causes to the performance discrepancy through a series of carefully designed experimental ablations. We show empirically that hypotheses such as offline data coverage and data quality by itself cannot convincingly explain the performance difference. We also find that while offline algorithms train policy to become good at pairwise classification, it is worse at generations; in the meantime the policies trained by online algorithms are good at generations while worse at pairwise classification. This hints at a unique interplay between discriminative and generative capabilities, which is greatly impacted by the sampling process. Lastly, we observe that the performance discrepancy persists for both contrastive and non-contrastive loss functions, and appears not to be addressed by simply scaling up policy networks. Taken together, our study sheds light on the pivotal role of on-policy sampling in AI alignment, and hints at certain fundamental challenges of offline alignment algorithms.
Read more5/15/2024