Harnessing Increased Client Participation with Cohort-Parallel Federated Learning
2405.15644
0
0
Abstract
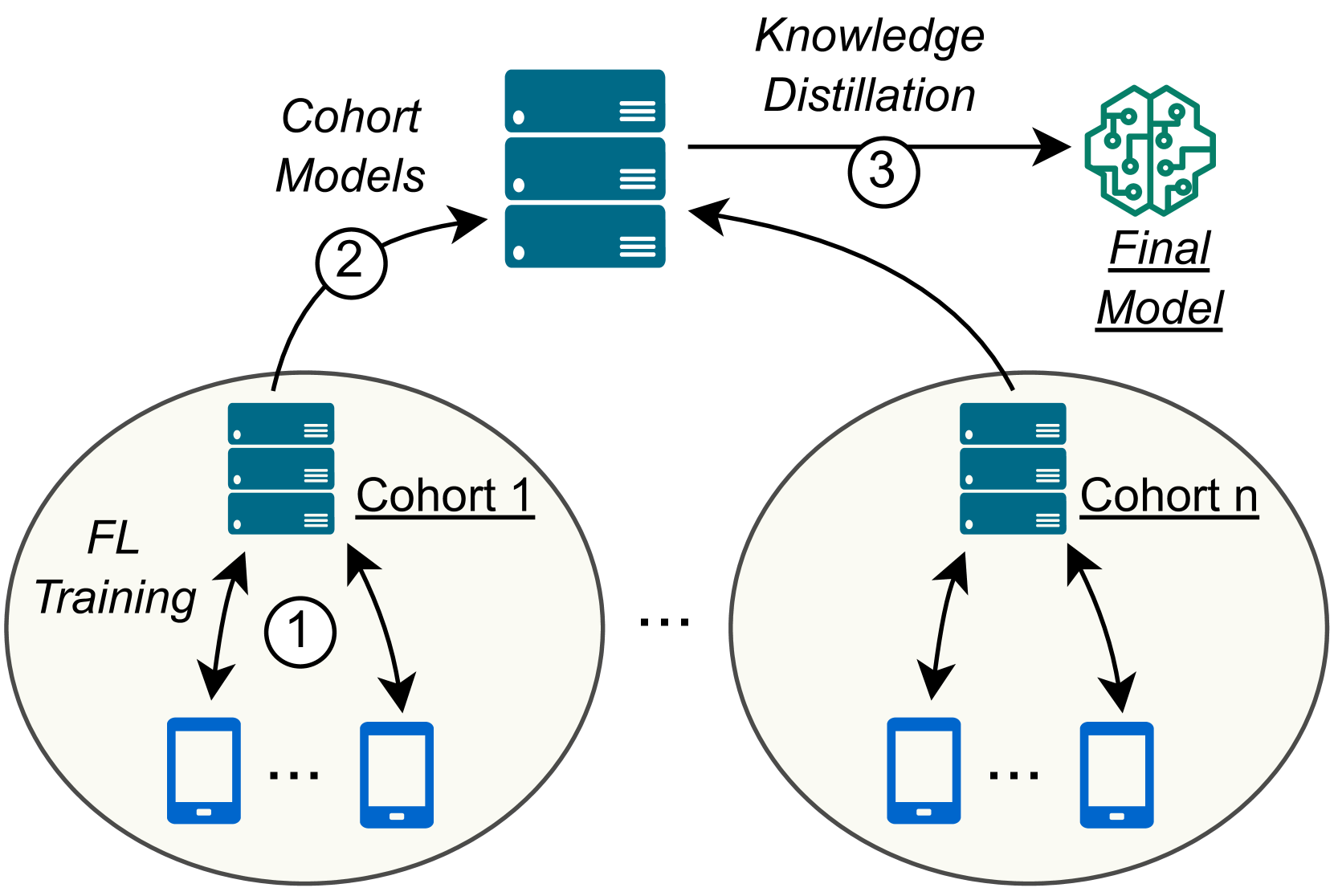
Federated Learning (FL) is a machine learning approach where nodes collaboratively train a global model. As more nodes participate in a round of FL, the effectiveness of individual model updates by nodes also diminishes. In this study, we increase the effectiveness of client updates by dividing the network into smaller partitions, or cohorts. We introduce Cohort-Parallel Federated Learning (CPFL): a novel learning approach where each cohort independently trains a global model using FL, until convergence, and the produced models by each cohort are then unified using one-shot Knowledge Distillation (KD) and a cross-domain, unlabeled dataset. The insight behind CPFL is that smaller, isolated networks converge quicker than in a one-network setting where all nodes participate. Through exhaustive experiments involving realistic traces and non-IID data distributions on the CIFAR-10 and FEMNIST image classification tasks, we investigate the balance between the number of cohorts, model accuracy, training time, and compute and communication resources. Compared to traditional FL, CPFL with four cohorts, non-IID data distribution, and CIFAR-10 yields a 1.9$times$ reduction in train time and a 1.3$times$ reduction in resource usage, with a minimal drop in test accuracy.
Create account to get full access
Overview
- Explores a new approach to Federated Learning called "Cohort-Parallel Federated Learning" that aims to increase client participation and improve convergence.
- Federated Learning is a machine learning technique that trains an AI model across multiple decentralized devices or servers holding local data, without exchanging the data itself.
- The proposed approach divides clients into cohorts that train in parallel, which the authors claim can lead to faster convergence and higher client participation compared to traditional Federated Learning.
Plain English Explanation
Federated Learning is a way of training AI models that allows many different devices or servers to contribute to the model without sharing the data on those devices. This is important for privacy and efficiency reasons. However, getting all the devices to participate can be challenging.
The researchers in this paper propose a new approach called "Cohort-Parallel Federated Learning" that divides the participating devices into smaller groups or "cohorts". These cohorts then train the model in parallel, which the authors claim can lead to the model converging (reaching a good solution) faster.
Imagine you have a group project where everyone needs to contribute, but some people are slower or less engaged. By splitting the group into smaller teams that work in parallel, you may be able to finish the project more quickly. The same idea applies here - by dividing the participating devices into cohorts, the model can improve faster overall.
The authors also suggest this approach could lead to more devices participating, since the work is divided into more manageable pieces. This is important, as getting a large number of devices to participate is a key challenge in Federated Learning.
Technical Explanation
The paper proposes a new Federated Learning approach called "Cohort-Parallel Federated Learning" (CPFL). In CPFL, the participating clients (devices or servers) are divided into smaller "cohorts" that train the model in parallel.
Specifically, the authors divide the clients into cohorts based on their data distributions. Each cohort then performs local training on its own data and periodically shares model updates with a central server. The central server aggregates these updates and sends the updated model back to the cohorts.
The authors claim this parallel training of cohorts can lead to faster convergence compared to traditional Federated Learning approaches, where all clients train sequentially. They also suggest CPFL can increase overall client participation, as the workload is divided into more manageable pieces for each client.
The paper includes experiments on both synthetic and real-world datasets that demonstrate the benefits of CPFL over standard Federated Learning in terms of convergence speed and client participation rates. The authors also explore the impact of cohort size and other hyperparameters on the performance of CPFL.
Critical Analysis
The authors make a compelling case for the benefits of their Cohort-Parallel Federated Learning approach. The idea of dividing clients into smaller training groups is intuitive and the experimental results seem to support the claimed advantages.
However, the paper does not address some potential limitations or areas for further research. For example, it's not clear how the cohorts are formed in practice - the authors use a simplified clustering approach, but real-world data distributions may be more complex. Additionally, the impact of unbalanced or non-i.i.d. data across cohorts is not extensively explored.
It would also be helpful to understand the communication and coordination overhead introduced by the parallel cohort training, as this could be a practical concern in real-world Federated Learning deployments. The authors briefly mention this but don't provide a detailed analysis.
Overall, the research presents a promising new direction for Federated Learning, but further investigation is needed to fully understand the strengths, weaknesses, and practical considerations of the Cohort-Parallel approach.
Conclusion
This paper introduces a novel Federated Learning technique called Cohort-Parallel Federated Learning (CPFL) that aims to improve convergence speed and client participation compared to traditional Federated Learning.
By dividing participating clients into cohorts that train in parallel, CPFL appears to offer benefits in terms of both model convergence and overall engagement of the client population. The experimental results are encouraging and suggest this approach could be a valuable tool for organizations looking to harness the power of Federated Learning while overcoming some of the common challenges.
As Federated Learning continues to gain traction in real-world applications, techniques like CPFL that address key limitations will be increasingly important. Further research is needed to fully understand the practical implications and potential pitfalls of this approach, but the core idea presented in this paper is a promising step forward for the field of Federated Learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Accelerating Hybrid Federated Learning Convergence under Partial Participation
Jieming Bian, Lei Wang, Kun Yang, Cong Shen, Jie Xu
0
0
Over the past few years, Federated Learning (FL) has become a popular distributed machine learning paradigm. FL involves a group of clients with decentralized data who collaborate to learn a common model under the coordination of a centralized server, with the goal of protecting clients' privacy by ensuring that local datasets never leave the clients and that the server only performs model aggregation. However, in realistic scenarios, the server may be able to collect a small amount of data that approximately mimics the population distribution and has stronger computational ability to perform the learning process. To address this, we focus on the hybrid FL framework in this paper. While previous hybrid FL work has shown that the alternative training of clients and server can increase convergence speed, it has focused on the scenario where clients fully participate and ignores the negative effect of partial participation. In this paper, we provide theoretical analysis of hybrid FL under clients' partial participation to validate that partial participation is the key constraint on convergence speed. We then propose a new algorithm called FedCLG, which investigates the two-fold role of the server in hybrid FL. Firstly, the server needs to process the training steps using its small amount of local datasets. Secondly, the server's calculated gradient needs to guide the participated clients' training and the server's aggregation. We validate our theoretical findings through numerical experiments, which show that our proposed method FedCLG outperforms state-of-the-art methods.
5/21/2024

Towards Client Driven Federated Learning
Songze Li, Chenqing Zhu
0
0
Conventional federated learning (FL) frameworks follow a server-driven model where the server determines session initiation and client participation, which faces challenges in accommodating clients' asynchronous needs for model updates. We introduce Client-Driven Federated Learning (CDFL), a novel FL framework that puts clients at the driving role. In CDFL, each client independently and asynchronously updates its model by uploading the locally trained model to the server and receiving a customized model tailored to its local task. The server maintains a repository of cluster models, iteratively refining them using received client models. Our framework accommodates complex dynamics in clients' data distributions, characterized by time-varying mixtures of cluster distributions, enabling rapid adaptation to new tasks with superior performance. In contrast to traditional clustered FL protocols that send multiple cluster models to a client to perform distribution estimation, we propose a paradigm that offloads the estimation task to the server and only sends a single model to a client, and novel strategies to improve estimation accuracy. We provide a theoretical analysis of CDFL's convergence. Extensive experiments across various datasets and system settings highlight CDFL's substantial advantages in model performance and computation efficiency over baselines.
5/27/2024
Federated Learning: A Cutting-Edge Survey of the Latest Advancements and Applications
Azim Akhtarshenas, Mohammad Ali Vahedifar, Navid Ayoobi, Behrouz Maham, Tohid Alizadeh, Sina Ebrahimi, David L'opez-P'erez
0
0
Robust machine learning (ML) models can be developed by leveraging large volumes of data and distributing the computational tasks across numerous devices or servers. Federated learning (FL) is a technique in the realm of ML that facilitates this goal by utilizing cloud infrastructure to enable collaborative model training among a network of decentralized devices. Beyond distributing the computational load, FL targets the resolution of privacy issues and the reduction of communication costs simultaneously. To protect user privacy, FL requires users to send model updates rather than transmitting large quantities of raw and potentially confidential data. Specifically, individuals train ML models locally using their own data and then upload the results in the form of weights and gradients to the cloud for aggregation into the global model. This strategy is also advantageous in environments with limited bandwidth or high communication costs, as it prevents the transmission of large data volumes. With the increasing volume of data and rising privacy concerns, alongside the emergence of large-scale ML models like Large Language Models (LLMs), FL presents itself as a timely and relevant solution. It is therefore essential to review current FL algorithms to guide future research that meets the rapidly evolving ML demands. This survey provides a comprehensive analysis and comparison of the most recent FL algorithms, evaluating them on various fronts including mathematical frameworks, privacy protection, resource allocation, and applications. Beyond summarizing existing FL methods, this survey identifies potential gaps, open areas, and future challenges based on the performance reports and algorithms used in recent studies. This survey enables researchers to readily identify existing limitations in the FL field for further exploration.
5/28/2024
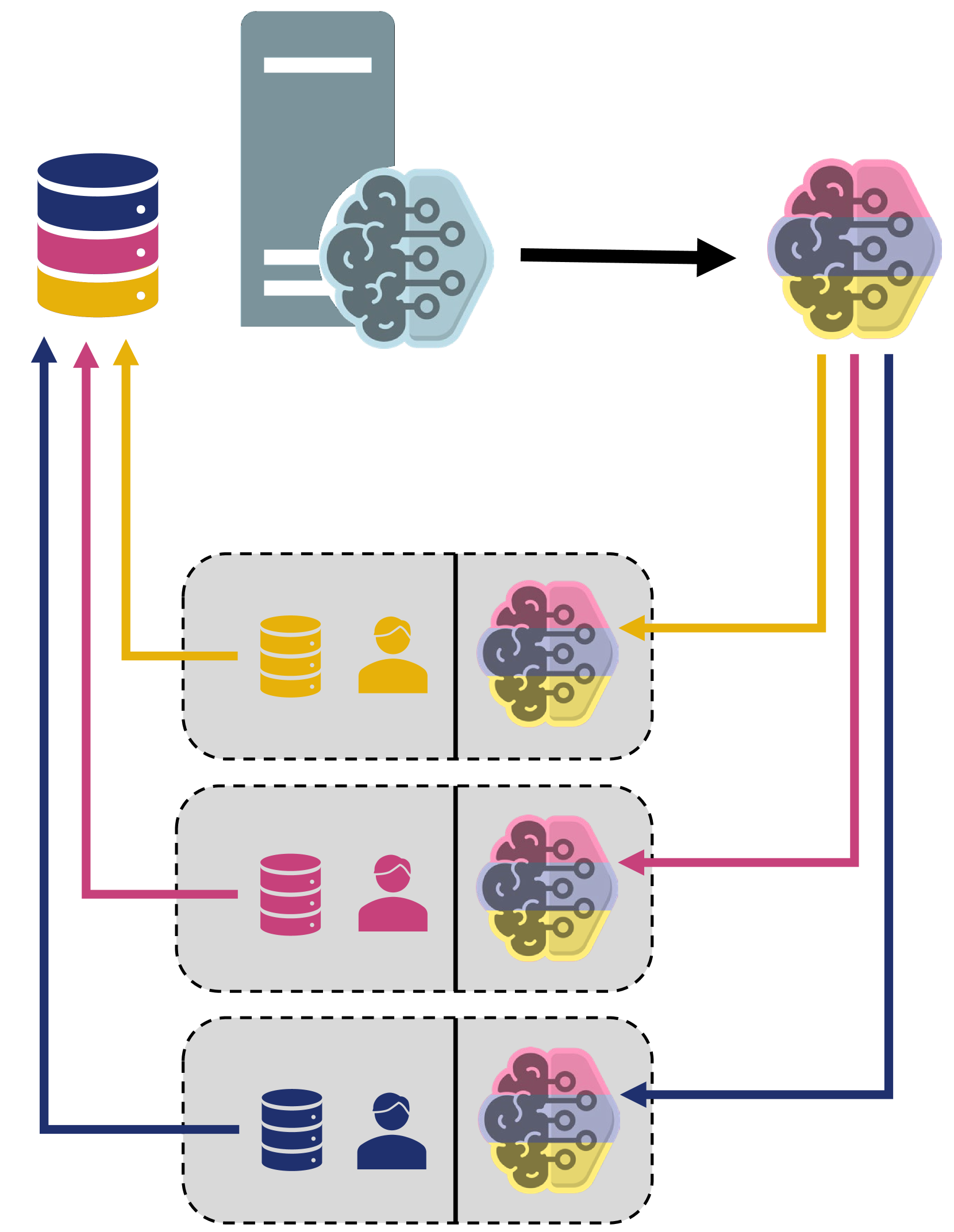
Decentralized Personalized Federated Learning
Salma Kharrat, Marco Canini, Samuel Horvath
0
0
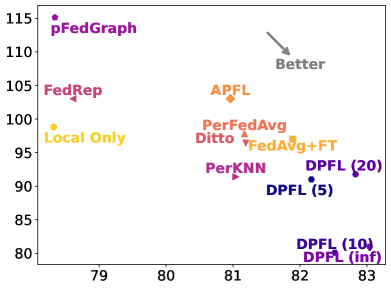
This work tackles the challenges of data heterogeneity and communication limitations in decentralized federated learning. We focus on creating a collaboration graph that guides each client in selecting suitable collaborators for training personalized models that leverage their local data effectively. Our approach addresses these issues through a novel, communication-efficient strategy that enhances resource efficiency. Unlike traditional methods, our formulation identifies collaborators at a granular level by considering combinatorial relations of clients, enhancing personalization while minimizing communication overhead. We achieve this through a bi-level optimization framework that employs a constrained greedy algorithm, resulting in a resource-efficient collaboration graph for personalized learning. Extensive evaluation against various baselines across diverse datasets demonstrates the superiority of our method, named DPFL. DPFL consistently outperforms other approaches, showcasing its effectiveness in handling real-world data heterogeneity, minimizing communication overhead, enhancing resource efficiency, and building personalized models in decentralized federated learning scenarios.
6/11/2024