Harnessing Knowledge Retrieval with Large Language Models for Clinical Report Error Correction
2406.15045
0
0
Abstract
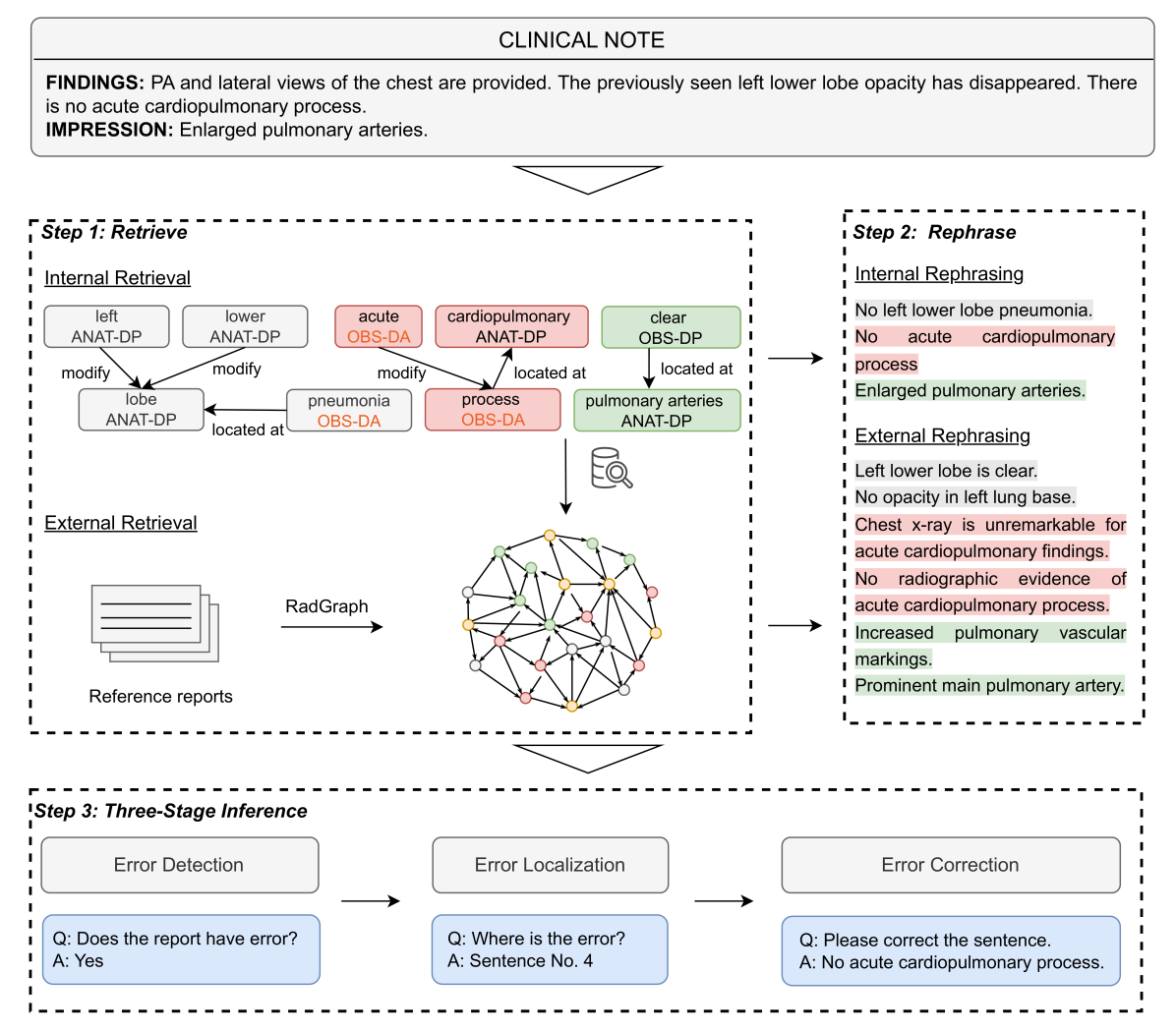
This study proposes an approach for error correction in clinical radiology reports, leveraging large language models (LLMs) and retrieval-augmented generation (RAG) techniques. The proposed framework employs internal and external retrieval mechanisms to extract relevant medical entities and relations from the report and external knowledge sources. A three-stage inference process is introduced, decomposing the task into error detection, localization, and correction subtasks, which enhances the explainability and performance of the system. The effectiveness of the approach is evaluated using a benchmark dataset created by corrupting real-world radiology reports with realistic errors, guided by domain experts. Experimental results demonstrate the benefits of the proposed methods, with the combination of internal and external retrieval significantly improving the accuracy of error detection, localization, and correction across various state-of-the-art LLMs. The findings contribute to the development of more robust and reliable error correction systems for clinical documentation.
Create account to get full access
Overview
- This paper explores the use of large language models (LLMs) to assist in correcting errors in clinical reports.
- The researchers developed a system that retrieves relevant medical knowledge from LLMs to help identify and fix errors in clinical documentation.
- The proposed approach aims to improve the accuracy and quality of medical reports, which is crucial for patient care and clinical decision-making.
Plain English Explanation
The paper looks at how we can use powerful language models, known as large language models (LLMs), to help fix mistakes in medical reports. These reports are important because they contain information about patients that doctors and nurses use to make decisions about their care.
The researchers created a system that can pull relevant medical knowledge from LLMs and use that information to identify and correct errors in clinical documentation. For example, if a report states a patient has a certain condition, but the LLM knows that's not accurate based on the patient's symptoms and test results, the system can flag the error and suggest a correction.
This is an important task because accurate clinical reports are essential for providing high-quality patient care. Errors in these reports can lead to misdiagnoses, inappropriate treatments, or other problems. By using powerful language models to help catch and fix these mistakes, the researchers hope to improve the overall quality and reliability of medical documentation.
Technical Explanation
The paper presents a system that leverages retrieval-augmented generation (RAG) techniques to harness the knowledge stored in large language models (LLMs) for the task of clinical report error correction.
The proposed approach consists of two key components:
-
Knowledge Retrieval Module: This module uses a RAG-based model to retrieve relevant medical knowledge from an LLM based on the content of the clinical report. The retrieved information can help identify potential errors or inconsistencies in the report.
-
Error Correction Module: This module takes the original report and the retrieved knowledge to generate a corrected version of the report. The researchers experimented with different language model architectures, including BiomedRAG, to optimize the error correction performance.
The researchers evaluated their system on a dataset of real-world clinical reports, measuring its ability to correctly identify and fix various types of errors, such as factual mistakes, inconsistencies, and missing information. The results demonstrated the effectiveness of the proposed approach in enhancing the accuracy and quality of clinical documentation.
Critical Analysis
The paper presents a promising approach to leveraging LLMs for clinical report error correction, which is an important and practical problem in the healthcare domain. The use of retrieval-augmented generation techniques to incorporate external medical knowledge is a key strength of the proposed system.
However, the paper does not provide a detailed analysis of the limitations or potential drawbacks of the system. For example, it would be valuable to understand the types of errors the system struggles with, the impact of the size and quality of the underlying knowledge base, and any potential biases or errors introduced by the LLMs.
Additionally, while the researchers demonstrate the system's effectiveness on a dataset of real-world clinical reports, it would be helpful to see further validation on a larger and more diverse set of reports to assess the generalizability of the approach.
Future research could also explore ways to make the error correction process more transparent and interpretable, allowing clinicians to better understand the reasoning behind the suggested corrections and have more confidence in the system's outputs.
Conclusion
This paper presents a novel approach to leveraging large language models and retrieval-augmented generation techniques to improve the accuracy and quality of clinical documentation. By harnessing medical knowledge stored in LLMs, the proposed system can effectively identify and correct various types of errors in clinical reports.
The successful implementation of this technology could have a significant impact on patient care, as accurate and reliable clinical reports are crucial for making informed medical decisions. The researchers have demonstrated the potential of this approach, and further development and validation could lead to valuable tools for healthcare professionals.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Tool Calling: Enhancing Medication Consultation via Retrieval-Augmented Large Language Models
Zhongzhen Huang, Kui Xue, Yongqi Fan, Linjie Mu, Ruoyu Liu, Tong Ruan, Shaoting Zhang, Xiaofan Zhang
0
0
Large-scale language models (LLMs) have achieved remarkable success across various language tasks but suffer from hallucinations and temporal misalignment. To mitigate these shortcomings, Retrieval-augmented generation (RAG) has been utilized to provide external knowledge to facilitate the answer generation. However, applying such models to the medical domain faces several challenges due to the lack of domain-specific knowledge and the intricacy of real-world scenarios. In this study, we explore LLMs with RAG framework for knowledge-intensive tasks in the medical field. To evaluate the capabilities of LLMs, we introduce MedicineQA, a multi-round dialogue benchmark that simulates the real-world medication consultation scenario and requires LLMs to answer with retrieved evidence from the medicine database. MedicineQA contains 300 multi-round question-answering pairs, each embedded within a detailed dialogue history, highlighting the challenge posed by this knowledge-intensive task to current LLMs. We further propose a new textit{Distill-Retrieve-Read} framework instead of the previous textit{Retrieve-then-Read}. Specifically, the distillation and retrieval process utilizes a tool calling mechanism to formulate search queries that emulate the keyword-based inquiries used by search engines. With experimental results, we show that our framework brings notable performance improvements and surpasses the previous counterparts in the evidence retrieval process in terms of evidence retrieval accuracy. This advancement sheds light on applying RAG to the medical domain.
4/30/2024
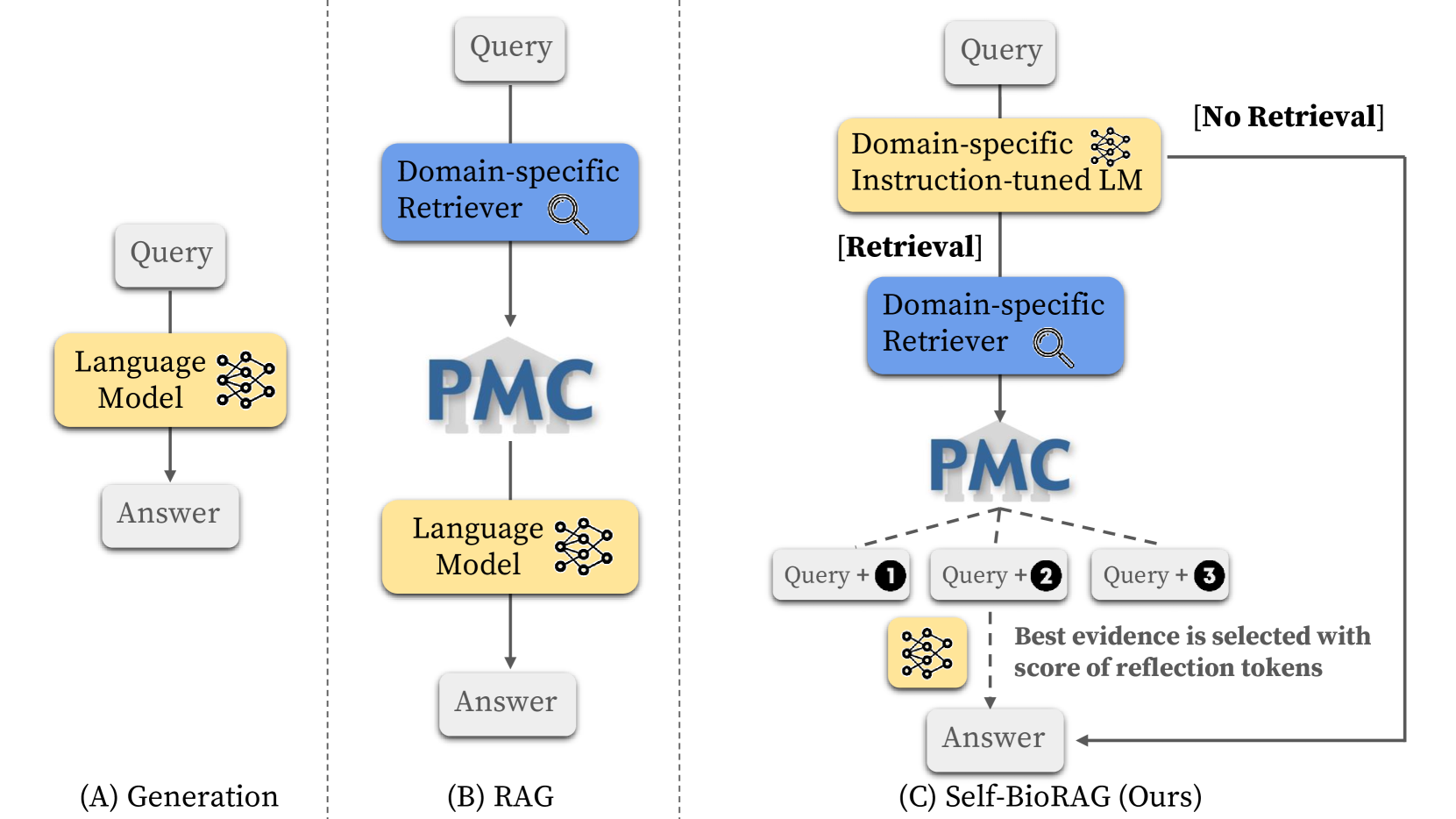
Improving Medical Reasoning through Retrieval and Self-Reflection with Retrieval-Augmented Large Language Models
Minbyul Jeong, Jiwoong Sohn, Mujeen Sung, Jaewoo Kang
0
0
Recent proprietary large language models (LLMs), such as GPT-4, have achieved a milestone in tackling diverse challenges in the biomedical domain, ranging from multiple-choice questions to long-form generations. To address challenges that still cannot be handled with the encoded knowledge of LLMs, various retrieval-augmented generation (RAG) methods have been developed by searching documents from the knowledge corpus and appending them unconditionally or selectively to the input of LLMs for generation. However, when applying existing methods to different domain-specific problems, poor generalization becomes apparent, leading to fetching incorrect documents or making inaccurate judgments. In this paper, we introduce Self-BioRAG, a framework reliable for biomedical text that specializes in generating explanations, retrieving domain-specific documents, and self-reflecting generated responses. We utilize 84k filtered biomedical instruction sets to train Self-BioRAG that can assess its generated explanations with customized reflective tokens. Our work proves that domain-specific components, such as a retriever, domain-related document corpus, and instruction sets are necessary for adhering to domain-related instructions. Using three major medical question-answering benchmark datasets, experimental results of Self-BioRAG demonstrate significant performance gains by achieving a 7.2% absolute improvement on average over the state-of-the-art open-foundation model with a parameter size of 7B or less. Overall, we analyze that Self-BioRAG finds the clues in the question, retrieves relevant documents if needed, and understands how to answer with information from retrieved documents and encoded knowledge as a medical expert does. We release our data and code for training our framework components and model weights (7B and 13B) to enhance capabilities in biomedical and clinical domains.
6/19/2024
Improving Retrieval for RAG based Question Answering Models on Financial Documents
Spurthi Setty, Katherine Jijo, Eden Chung, Natan Vidra
0
0
The effectiveness of Large Language Models (LLMs) in generating accurate responses relies heavily on the quality of input provided, particularly when employing Retrieval Augmented Generation (RAG) techniques. RAG enhances LLMs by sourcing the most relevant text chunk(s) to base queries upon. Despite the significant advancements in LLMs' response quality in recent years, users may still encounter inaccuracies or irrelevant answers; these issues often stem from suboptimal text chunk retrieval by RAG rather than the inherent capabilities of LLMs. To augment the efficacy of LLMs, it is crucial to refine the RAG process. This paper explores the existing constraints of RAG pipelines and introduces methodologies for enhancing text retrieval. It delves into strategies such as sophisticated chunking techniques, query expansion, the incorporation of metadata annotations, the application of re-ranking algorithms, and the fine-tuning of embedding algorithms. Implementing these approaches can substantially improve the retrieval quality, thereby elevating the overall performance and reliability of LLMs in processing and responding to queries.
4/12/2024
💬
A Survey on RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, Qing Li
0
0
As one of the most advanced techniques in AI, Retrieval-Augmented Generation (RAG) can offer reliable and up-to-date external knowledge, providing huge convenience for numerous tasks. Particularly in the era of AI-Generated Content (AIGC), the powerful capacity of retrieval in providing additional knowledge enables RAG to assist existing generative AI in producing high-quality outputs. Recently, Large Language Models (LLMs) have demonstrated revolutionary abilities in language understanding and generation, while still facing inherent limitations, such as hallucinations and out-of-date internal knowledge. Given the powerful abilities of RAG in providing the latest and helpful auxiliary information, Retrieval-Augmented Large Language Models (RA-LLMs) have emerged to harness external and authoritative knowledge bases, rather than solely relying on the model's internal knowledge, to augment the generation quality of LLMs. In this survey, we comprehensively review existing research studies in RA-LLMs, covering three primary technical perspectives: architectures, training strategies, and applications. As the preliminary knowledge, we briefly introduce the foundations and recent advances of LLMs. Then, to illustrate the practical significance of RAG for LLMs, we systematically review mainstream relevant work by their architectures, training strategies, and application areas, detailing specifically the challenges of each and the corresponding capabilities of RA-LLMs. Finally, to deliver deeper insights, we discuss current limitations and several promising directions for future research. Updated information about this survey can be found at https://advanced-recommender-systems.github.io/RAG-Meets-LLMs/
6/18/2024