Tool Calling: Enhancing Medication Consultation via Retrieval-Augmented Large Language Models
2404.17897
0
0
Abstract
Large-scale language models (LLMs) have achieved remarkable success across various language tasks but suffer from hallucinations and temporal misalignment. To mitigate these shortcomings, Retrieval-augmented generation (RAG) has been utilized to provide external knowledge to facilitate the answer generation. However, applying such models to the medical domain faces several challenges due to the lack of domain-specific knowledge and the intricacy of real-world scenarios. In this study, we explore LLMs with RAG framework for knowledge-intensive tasks in the medical field. To evaluate the capabilities of LLMs, we introduce MedicineQA, a multi-round dialogue benchmark that simulates the real-world medication consultation scenario and requires LLMs to answer with retrieved evidence from the medicine database. MedicineQA contains 300 multi-round question-answering pairs, each embedded within a detailed dialogue history, highlighting the challenge posed by this knowledge-intensive task to current LLMs. We further propose a new textit{Distill-Retrieve-Read} framework instead of the previous textit{Retrieve-then-Read}. Specifically, the distillation and retrieval process utilizes a tool calling mechanism to formulate search queries that emulate the keyword-based inquiries used by search engines. With experimental results, we show that our framework brings notable performance improvements and surpasses the previous counterparts in the evidence retrieval process in terms of evidence retrieval accuracy. This advancement sheds light on applying RAG to the medical domain.
Create account to get full access
Overview
- This paper introduces "Tool Calling", a system that enhances medication consultation by integrating a retrieval-augmented large language model (LLM) into the consultation process.
- The goal is to improve the quality and accuracy of medication-related conversations between healthcare providers and patients.
- The system leverages a large knowledge base to provide relevant information and context during the consultation, helping to ensure that all important details are addressed.
Plain English Explanation
The research paper describes a new system called "Tool Calling" that aims to improve the quality of conversations between healthcare providers and patients about medications. Improving medical reasoning through retrieval and self-reflection and unlocking multi-view insights through knowledge-dense retrieval are two related approaches that also leverage retrieval to enhance language models.
The key idea behind Tool Calling is to integrate a large language model (LLM) that has been trained on a large knowledge base of medical information. During a medication consultation, the system can rapidly retrieve relevant facts and details from this knowledge base to provide context and guidance to the healthcare provider. This helps ensure that all important points are covered and that the conversation is as thorough and accurate as possible.
For example, if a patient asks about potential side effects of a medication, the LLM could quickly pull up information on common side effects, contraindications, and dosage guidelines to inform the provider's response. By having this additional knowledge readily available, the consultation is more comprehensive and the patient can feel more confident that their questions have been fully addressed.
Technical Explanation
The core of the Tool Calling system is a retrieval-augmented LLM that has been trained on a large corpus of medical knowledge. Improving retrieval for RAG-based question answering models and leveraging missing knowledge in LLMs provide relevant insights into enhancing retrieval capabilities of language models.
During a medication consultation, the system takes the dialogue between the provider and patient as input. It then uses this context to query the knowledge base and retrieve the most relevant information to include in the provider's response. This allows the LLM to supplement its own language generation capabilities with targeted retrieval of specific medical facts and details.
The authors evaluate the Tool Calling system through a series of experiments, including comparisons to baseline language models and assessments of end-user satisfaction. Their results demonstrate that the retrieval-augmented approach leads to more informative and accurate medication consultations compared to conventional language models.
Critical Analysis
The authors acknowledge some limitations of their work, such as the challenge of maintaining an up-to-date knowledge base and the potential biases that could be introduced by the retrieval process. ConfLARE: Conformal Large Language Model Retrieval proposes an approach to address calibration issues in retrieval-augmented LLMs.
Additionally, the paper does not delve into the potential privacy and ethical concerns around integrating an LLM into sensitive medical conversations. Further research would be needed to address these important considerations.
Overall, the Tool Calling system represents a promising step forward in enhancing the quality and thoroughness of medication consultations through the integration of retrieval-augmented language models. However, continued development and rigorous testing will be necessary to ensure the system is safe, reliable, and beneficial for both healthcare providers and patients.
Conclusion
The Tool Calling system described in this paper aims to improve medication consultations by leveraging a retrieval-augmented LLM to provide healthcare providers with relevant medical knowledge and context during conversations with patients. By quickly retrieving and integrating key facts and details, the system helps ensure that all important aspects of the medication regimen are thoroughly discussed.
The authors' experimental results demonstrate the potential benefits of this approach, though further research is needed to address limitations and ethical considerations. Overall, the Tool Calling concept represents an innovative way to harness the power of large language models to enhance the quality and effectiveness of healthcare communication.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
New!MKRAG: Medical Knowledge Retrieval Augmented Generation for Medical Question Answering
Yucheng Shi, Shaochen Xu, Tianze Yang, Zhengliang Liu, Tianming Liu, Xiang Li, Ninghao Liu
0
0
Large Language Models (LLMs), although powerful in general domains, often perform poorly on domain-specific tasks like medical question answering (QA). Moreover, they tend to function as black-boxes, making it challenging to modify their behavior. To address the problem, our study delves into retrieval augmented generation (RAG), aiming to improve LLM responses without the need for fine-tuning or retraining. Specifically, we propose a comprehensive retrieval strategy to extract medical facts from an external knowledge base, and then inject them into the query prompt for LLMs. Focusing on medical QA using the MedQA-SMILE dataset, we evaluate the impact of different retrieval models and the number of facts provided to the LLM. Notably, our retrieval-augmented Vicuna-7B model exhibited an accuracy improvement from 44.46% to 48.54%. This work underscores the potential of RAG to enhance LLM performance, offering a practical approach to mitigate the challenges of black-box LLMs.
7/1/2024
💬
A Survey on RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, Qing Li
0
0
As one of the most advanced techniques in AI, Retrieval-Augmented Generation (RAG) can offer reliable and up-to-date external knowledge, providing huge convenience for numerous tasks. Particularly in the era of AI-Generated Content (AIGC), the powerful capacity of retrieval in providing additional knowledge enables RAG to assist existing generative AI in producing high-quality outputs. Recently, Large Language Models (LLMs) have demonstrated revolutionary abilities in language understanding and generation, while still facing inherent limitations, such as hallucinations and out-of-date internal knowledge. Given the powerful abilities of RAG in providing the latest and helpful auxiliary information, Retrieval-Augmented Large Language Models (RA-LLMs) have emerged to harness external and authoritative knowledge bases, rather than solely relying on the model's internal knowledge, to augment the generation quality of LLMs. In this survey, we comprehensively review existing research studies in RA-LLMs, covering three primary technical perspectives: architectures, training strategies, and applications. As the preliminary knowledge, we briefly introduce the foundations and recent advances of LLMs. Then, to illustrate the practical significance of RAG for LLMs, we systematically review mainstream relevant work by their architectures, training strategies, and application areas, detailing specifically the challenges of each and the corresponding capabilities of RA-LLMs. Finally, to deliver deeper insights, we discuss current limitations and several promising directions for future research. Updated information about this survey can be found at https://advanced-recommender-systems.github.io/RAG-Meets-LLMs/
6/18/2024
💬
BiomedRAG: A Retrieval Augmented Large Language Model for Biomedicine
Mingchen Li, Halil Kilicoglu, Hua Xu, Rui Zhang
0
0
Large Language Models (LLMs) have swiftly emerged as vital resources for different applications in the biomedical and healthcare domains; however, these models encounter issues such as generating inaccurate information or hallucinations. Retrieval-augmented generation provided a solution for these models to update knowledge and enhance their performance. In contrast to previous retrieval-augmented LMs, which utilize specialized cross-attention mechanisms to help LLM encode retrieved text, BiomedRAG adopts a simpler approach by directly inputting the retrieved chunk-based documents into the LLM. This straightforward design is easily applicable to existing retrieval and language models, effectively bypassing noise information in retrieved documents, particularly in noise-intensive tasks. Moreover, we demonstrate the potential for utilizing the LLM to supervise the retrieval model in the biomedical domain, enabling it to retrieve the document that assists the LM in improving its predictions. Our experiments reveal that with the tuned scorer,textsc{ BiomedRAG} attains superior performance across 5 biomedical NLP tasks, encompassing information extraction (triple extraction, relation extraction), text classification, link prediction, and question-answering, leveraging over 9 datasets. For instance, in the triple extraction task, textsc{BiomedRAG} outperforms other triple extraction systems with micro-F1 scores of 81.42 and 88.83 on GIT and ChemProt corpora, respectively.
5/6/2024
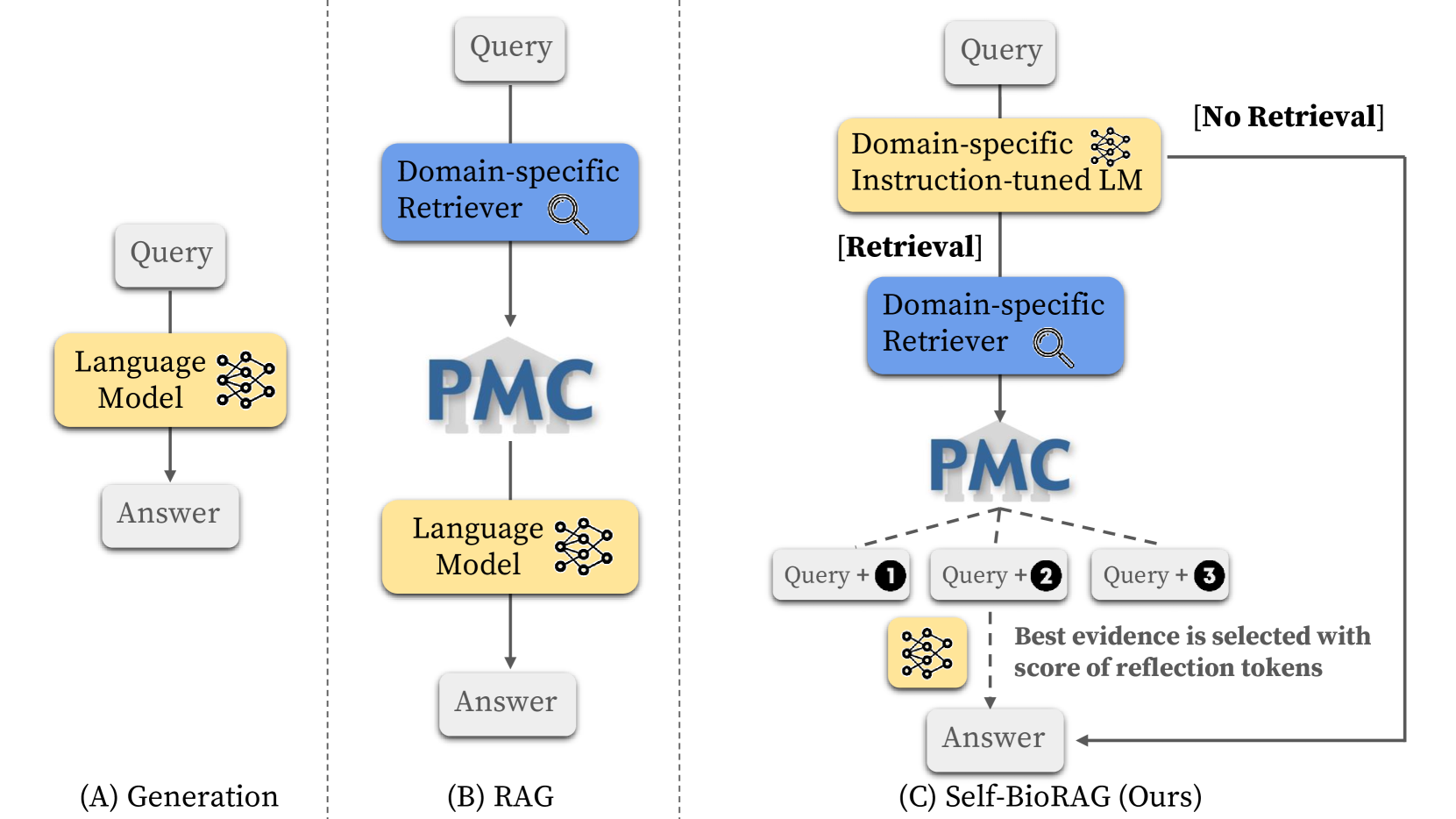
Improving Medical Reasoning through Retrieval and Self-Reflection with Retrieval-Augmented Large Language Models
Minbyul Jeong, Jiwoong Sohn, Mujeen Sung, Jaewoo Kang
0
0
Recent proprietary large language models (LLMs), such as GPT-4, have achieved a milestone in tackling diverse challenges in the biomedical domain, ranging from multiple-choice questions to long-form generations. To address challenges that still cannot be handled with the encoded knowledge of LLMs, various retrieval-augmented generation (RAG) methods have been developed by searching documents from the knowledge corpus and appending them unconditionally or selectively to the input of LLMs for generation. However, when applying existing methods to different domain-specific problems, poor generalization becomes apparent, leading to fetching incorrect documents or making inaccurate judgments. In this paper, we introduce Self-BioRAG, a framework reliable for biomedical text that specializes in generating explanations, retrieving domain-specific documents, and self-reflecting generated responses. We utilize 84k filtered biomedical instruction sets to train Self-BioRAG that can assess its generated explanations with customized reflective tokens. Our work proves that domain-specific components, such as a retriever, domain-related document corpus, and instruction sets are necessary for adhering to domain-related instructions. Using three major medical question-answering benchmark datasets, experimental results of Self-BioRAG demonstrate significant performance gains by achieving a 7.2% absolute improvement on average over the state-of-the-art open-foundation model with a parameter size of 7B or less. Overall, we analyze that Self-BioRAG finds the clues in the question, retrieves relevant documents if needed, and understands how to answer with information from retrieved documents and encoded knowledge as a medical expert does. We release our data and code for training our framework components and model weights (7B and 13B) to enhance capabilities in biomedical and clinical domains.
6/19/2024