Harnessing LLMs for API Interactions: A Framework for Classification and Synthetic Data Generation

0
Sign in to get full access
Overview
- Explores using large language models (LLMs) to classify and generate synthetic data for API interactions
- Proposes a framework for leveraging LLMs in API management tasks
- Demonstrates potential benefits of LLM-powered classification and data generation
Plain English Explanation
Large language models (LLMs) are powerful artificial intelligence systems that can understand and generate human-like text. This paper explores how LLMs can be used to improve the management of application programming interfaces (APIs), which are the building blocks of modern software applications.
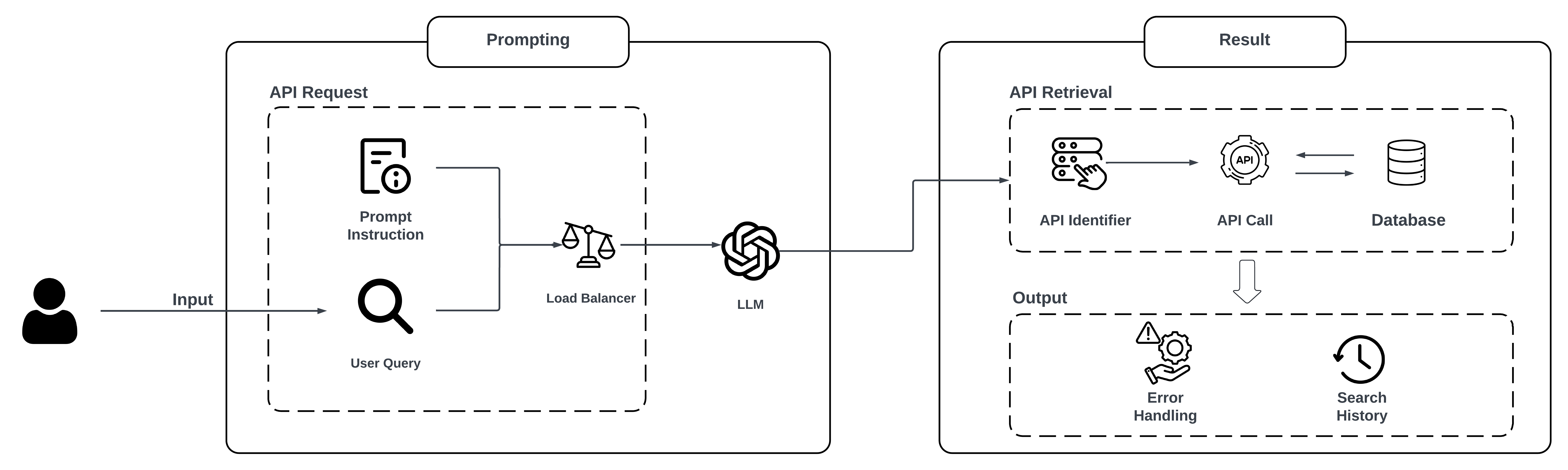
The researchers present a framework that shows how LLMs can be applied to two key API management tasks: classification and synthetic data generation.
For classification, the LLM can analyze the text of an API request or response and automatically categorize it. This could help developers and operators better understand how their APIs are being used.
For synthetic data generation, the LLM can create realistic-looking API data without using real customer information. This synthetic data can be used to test and improve API-based applications, while protecting user privacy.
The paper demonstrates the potential benefits of these LLM-powered capabilities through experiments and examples. By leveraging the capabilities of large language models, the researchers believe the framework can enhance API management and help organizations better understand and optimize their APIs.
Technical Explanation
The paper proposes a framework for harnessing LLMs to improve API management, with a focus on two key tasks: classification and synthetic data generation.
For API classification, the framework uses an LLM-based model to analyze the text of API requests and responses and automatically categorize them. The researchers experiment with different LLM architectures and fine-tuning approaches to optimize the classification performance.
The synthetic data generation component of the framework leverages the text generation capabilities of LLMs to create realistic-looking API data. The researchers explore techniques for conditioning the LLM to generate data that matches the statistical properties of real API traffic.
Through a series of experiments, the paper demonstrates the potential benefits of these LLM-powered capabilities. The classification model is shown to outperform traditional machine learning approaches, while the synthetic data generation produces samples that are difficult to distinguish from real API data.
The researchers also discuss potential limitations and areas for future work, such as improving the fidelity of the synthetic data and exploring the use of LLMs for other API management tasks like anomaly detection and documentation generation.
Critical Analysis
The paper presents a compelling framework for applying LLMs to API management tasks, but there are a few potential areas for further exploration and improvement:
-
Evaluation of synthetic data quality: While the paper shows that the generated data is difficult to distinguish from real API data, a more rigorous evaluation of the synthetic data's suitability for various API testing and development tasks would be beneficial.
-
Handling of sensitive information: The paper does not explicitly address how the framework would handle the generation of synthetic data that may contain sensitive or personally identifiable information. Addressing privacy and security concerns would be an important next step.
-
Scalability and performance: As the volume and complexity of API traffic grows, the scalability and performance of the LLM-based classification and data generation models will be crucial. The paper could explore techniques for improving the efficiency and robustness of these components.
-
Interpretability and explainability: LLMs can be challenging to interpret, which could be a concern for mission-critical API management tasks. The framework could be enhanced by incorporating techniques to improve the transparency and explainability of the LLM-powered models.
Overall, the paper presents an interesting and promising approach to leveraging LLMs for API management, but additional research and development would be needed to address these potential limitations and concerns.
Conclusion
This paper introduces a framework for harnessing the capabilities of large language models (LLMs) to enhance API management tasks, specifically API classification and synthetic data generation. By demonstrating the potential benefits of LLM-powered approaches, the researchers highlight the growing role of these advanced AI systems in improving the development, testing, and optimization of API-based applications.
The framework's ability to automatically classify API requests and responses, as well as generate realistic synthetic data, could help organizations better understand and manage their API ecosystems. As the use of APIs continues to expand, tools like the one described in this paper may become increasingly valuable for developers, operators, and product managers.
While the paper identifies some areas for further refinement and exploration, it represents an important step in exploring the intersection of LLMs and API management, a domain that is likely to see continued innovation and advancement in the years to come.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Harnessing LLMs for API Interactions: A Framework for Classification and Synthetic Data Generation
Chunliang Tao, Xiaojing Fan, Yahe Yang
As Large Language Models (LLMs) advance in natural language processing, there is growing interest in leveraging their capabilities to simplify software interactions. In this paper, we propose a novel system that integrates LLMs for both classifying natural language inputs into corresponding API calls and automating the creation of sample datasets tailored to specific API functions. By classifying natural language commands, our system allows users to invoke complex software functionalities through simple inputs, improving interaction efficiency and lowering the barrier to software utilization. Our dataset generation approach also enables the efficient and systematic evaluation of different LLMs in classifying API calls, offering a practical tool for developers or business owners to assess the suitability of LLMs for customized API management. We conduct experiments on several prominent LLMs using generated sample datasets for various API functions. The results show that GPT-4 achieves a high classification accuracy of 0.996, while LLaMA-3-8B performs much worse at 0.759. These findings highlight the potential of LLMs to transform API management and validate the effectiveness of our system in guiding model testing and selection across diverse applications.
Read more9/19/2024
💬
0
Large Language Model Enhanced Machine Learning Estimators for Classification
Yuhang Wu, Yingfei Wang, Chu Wang, Zeyu Zheng
Pre-trained large language models (LLM) have emerged as a powerful tool for simulating various scenarios and generating output given specific instructions and multimodal input. In this work, we analyze the specific use of LLM to enhance a classical supervised machine learning method for classification problems. We propose a few approaches to integrate LLM into a classical machine learning estimator to further enhance the prediction performance. We examine the performance of the proposed approaches through both standard supervised learning binary classification tasks, and a transfer learning task where the test data observe distribution changes compared to the training data. Numerical experiments using four publicly available datasets are conducted and suggest that using LLM to enhance classical machine learning estimators can provide significant improvement on prediction performance.
Read more5/10/2024

0
Data Generation using Large Language Models for Text Classification: An Empirical Case Study
Yinheng Li, Rogerio Bonatti, Sara Abdali, Justin Wagle, Kazuhito Koishida
Using Large Language Models (LLMs) to generate synthetic data for model training has become increasingly popular in recent years. While LLMs are capable of producing realistic training data, the effectiveness of data generation is influenced by various factors, including the choice of prompt, task complexity, and the quality, quantity, and diversity of the generated data. In this work, we focus exclusively on using synthetic data for text classification tasks. Specifically, we use natural language understanding (NLU) models trained on synthetic data to assess the quality of synthetic data from different generation approaches. This work provides an empirical analysis of the impact of these factors and offers recommendations for better data generation practices.
Read more7/23/2024

0
A Systematic Evaluation of Large Language Models for Natural Language Generation Tasks
Xuanfan Ni, Piji Li
Recent efforts have evaluated large language models (LLMs) in areas such as commonsense reasoning, mathematical reasoning, and code generation. However, to the best of our knowledge, no work has specifically investigated the performance of LLMs in natural language generation (NLG) tasks, a pivotal criterion for determining model excellence. Thus, this paper conducts a comprehensive evaluation of well-known and high-performing LLMs, namely ChatGPT, ChatGLM, T5-based models, LLaMA-based models, and Pythia-based models, in the context of NLG tasks. We select English and Chinese datasets encompassing Dialogue Generation and Text Summarization. Moreover, we propose a common evaluation setting that incorporates input templates and post-processing strategies. Our study reports both automatic results, accompanied by a detailed analysis.
Read more5/17/2024