Data Generation using Large Language Models for Text Classification: An Empirical Case Study

0

Sign in to get full access
Overview
- This paper explores the use of large language models (LLMs) for generating synthetic data to augment text classification datasets.
- The researchers conduct an empirical case study to evaluate the effectiveness of LLM-generated data in improving text classification performance.
- They investigate different prompting methods for generating synthetic data and assess its impact on model training and performance.
Plain English Explanation
In this study, the researchers looked at how large language models (LLMs) - powerful AI systems trained on vast amounts of text data - could be used to generate new text data. The goal was to see if this synthetic data could be used to improve the performance of text classification models, which are used to automatically categorize different types of text.
The researchers tried out different ways of prompting the LLM to generate new text that would be useful for training text classification models. They then evaluated how well the models performed when trained on a mix of real and synthetic data, compared to using only the original real-world data.
The key idea is that LLMs can be tapped to create additional training data, which can be particularly helpful when the original dataset is small or imbalanced (i.e., has very different amounts of examples for different classes). By generating plausible new examples, the LLM-powered data augmentation approach could potentially boost the classification model's performance.
Technical Explanation
The paper presents an empirical case study on using large language models (LLMs) to generate synthetic text data for text classification tasks. The researchers explore different prompting strategies to elicit relevant and high-quality synthetic samples from the LLM, and then evaluate the impact of incorporating this augmented data on the performance of text classification models.
The experimental setup involves several text classification datasets, including link to related work on empowering LLMs for data augmentation and link to related work on exploring prompting methods for class imbalance. The researchers compare the classification performance when training on the original dataset versus a dataset augmented with LLM-generated samples.
The prompting techniques investigated include link to related work on utilizing LLMs to generate synthetic data and link to related work on best practices and lessons learned for synthetic data generation. The paper also analyzes the quality and diversity of the synthetic data generated by the different prompting approaches.
Critical Analysis
The paper provides a thorough empirical evaluation of using LLMs for synthetic data generation in the context of text classification. The researchers acknowledge that the effectiveness of the approach may depend on the specific dataset and task, and highlight the need for careful prompting and synthetic data curation to ensure the generated samples are relevant and beneficial.
One potential limitation is that the paper does not explore the long-term implications of relying heavily on synthetic data, such as potential distribution shift or model overfitting. Additionally, the paper could have discussed more about the ethical considerations around the use of LLM-generated content, such as concerns about bias, fairness, and transparency.
Overall, the research presents a promising direction for leveraging the generative capabilities of LLMs to augment text classification datasets, but further investigation is needed to fully understand the trade-offs and best practices for this approach.
Conclusion
This empirical case study demonstrates the potential of using large language models to generate synthetic text data for improving the performance of text classification models. The researchers explore various prompting strategies and find that the augmented datasets can lead to significant gains in classification accuracy, particularly when the original dataset is small or imbalanced.
The findings suggest that LLM-driven synthetic data generation could be a valuable tool for text-based machine learning tasks, providing a way to expand limited datasets and potentially mitigate issues like class imbalance. However, the paper also highlights the importance of careful prompting and data curation to ensure the generated samples are high-quality and relevant.
As the use of large language models continues to grow, this research contributes to our understanding of how these powerful AI systems can be harnessed for data augmentation and other practical applications. The insights and lessons learned can inform future work in this area and help advance the state-of-the-art in text classification and other text-based machine learning domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Data Generation using Large Language Models for Text Classification: An Empirical Case Study
Yinheng Li, Rogerio Bonatti, Sara Abdali, Justin Wagle, Kazuhito Koishida
Using Large Language Models (LLMs) to generate synthetic data for model training has become increasingly popular in recent years. While LLMs are capable of producing realistic training data, the effectiveness of data generation is influenced by various factors, including the choice of prompt, task complexity, and the quality, quantity, and diversity of the generated data. In this work, we focus exclusively on using synthetic data for text classification tasks. Specifically, we use natural language understanding (NLU) models trained on synthetic data to assess the quality of synthetic data from different generation approaches. This work provides an empirical analysis of the impact of these factors and offers recommendations for better data generation practices.
Read more7/23/2024
0
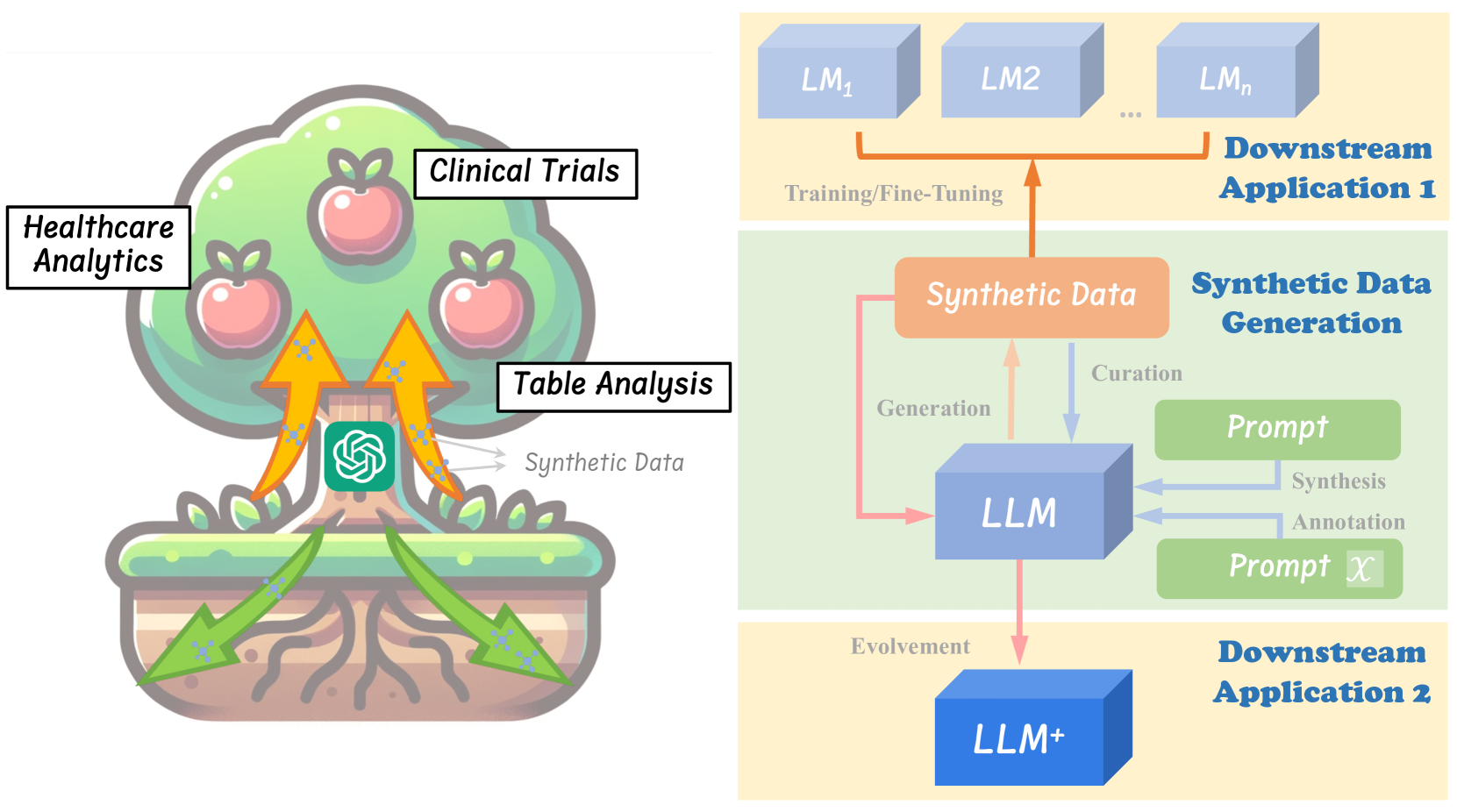
On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey
Lin Long, Rui Wang, Ruixuan Xiao, Junbo Zhao, Xiao Ding, Gang Chen, Haobo Wang
Within the evolving landscape of deep learning, the dilemma of data quantity and quality has been a long-standing problem. The recent advent of Large Language Models (LLMs) offers a data-centric solution to alleviate the limitations of real-world data with synthetic data generation. However, current investigations into this field lack a unified framework and mostly stay on the surface. Therefore, this paper provides an organization of relevant studies based on a generic workflow of synthetic data generation. By doing so, we highlight the gaps within existing research and outline prospective avenues for future study. This work aims to shepherd the academic and industrial communities towards deeper, more methodical inquiries into the capabilities and applications of LLMs-driven synthetic data generation.
Read more6/24/2024
0
Empowering Large Language Models for Textual Data Augmentation
Yichuan Li, Kaize Ding, Jianling Wang, Kyumin Lee
With the capabilities of understanding and executing natural language instructions, Large language models (LLMs) can potentially act as a powerful tool for textual data augmentation. However, the quality of augmented data depends heavily on the augmentation instructions provided, and the effectiveness can fluctuate across different downstream tasks. While manually crafting and selecting instructions can offer some improvement, this approach faces scalability and consistency issues in practice due to the diversity of downstream tasks. In this work, we address these limitations by proposing a new solution, which can automatically generate a large pool of augmentation instructions and select the most suitable task-informed instructions, thereby empowering LLMs to create high-quality augmented data for different downstream tasks. Empirically, the proposed approach consistently generates augmented data with better quality compared to non-LLM and LLM-based data augmentation methods, leading to the best performance on 26 few-shot learning tasks sourced from a wide range of application domains.
Read more4/30/2024
0
Group-wise Prompting for Synthetic Tabular Data Generation using Large Language Models
Jinhee Kim, Taesung Kim, Jaegul Choo
Large language models (LLMs) have demonstrated impressive in-context learning capabilities across various domains. Inspired by this, our study explores the effectiveness of LLMs in generating realistic tabular data to mitigate class imbalance. We investigate and identify key prompt design elements such as data format, class presentation, and variable mapping to optimize the generation performance. Our findings indicate that using CSV format, balancing classes, and employing unique variable mapping produces realistic and reliable data, significantly enhancing machine learning performance for minor classes in imbalanced datasets. Additionally, these approaches improve the stability and efficiency of LLM data generation. We validate our approach using six real-world datasets and a toy dataset, achieving state-of-the-art performance in classification tasks. The code is available at: https://github.com/seharanul17/synthetic-tabular-LLM
Read more5/28/2024