Harnessing Orthogonality to Train Low-Rank Neural Networks

0
🧠
Sign in to get full access
Overview
- This study explores the learning dynamics of neural networks by analyzing the singular value decomposition (SVD) of their weights throughout training.
- The researchers found that an orthogonal basis within each multidimensional weight's SVD representation stabilizes during training.
- Building on this finding, they introduce Orthogonality-Informed Adaptive Low-Rank (OIALR) training, a novel method that exploits the intrinsic orthogonality of neural networks.
- OIALR can be seamlessly integrated into existing training workflows with minimal accuracy loss, as demonstrated by benchmarking on various datasets and well-established network architectures.
- With appropriate hyperparameter tuning, OIALR can surpass conventional training setups, including those of state-of-the-art models.
Plain English Explanation
The study explores how neural networks learn by looking at the mathematical properties of the numbers (weights) inside the network as it trains. The researchers discovered that during training, the weights in the network naturally start to form an "orthogonal" or perpendicular structure. Building on this finding, they developed a new training method called Orthogonality-Informed Adaptive Low-Rank (OIALR) that takes advantage of this orthogonal structure.
OIALR can be easily added to existing neural network training workflows with little impact on the network's accuracy. The researchers tested OIALR on various datasets and network architectures, and found that with the right settings, it can actually perform better than the standard training approach, including the latest state-of-the-art models.
Technical Explanation
The researchers in this study analyzed the singular value decomposition (SVD) of the weight matrices in neural networks during training. They discovered that an orthogonal basis emerges within each weight matrix's SVD representation as training progresses.
Leveraging this insight, the researchers developed a new training method called Orthogonality-Informed Adaptive Low-Rank (OIALR). OIALR seamlessly integrates with existing training workflows by adaptively adjusting the rank (complexity) of the weight matrices based on their orthogonal structure. This helps to reduce the number of parameters in the network without significant accuracy loss.
The team benchmarked OIALR on various datasets and well-established network architectures, including state-of-the-art models. They found that with proper hyperparameter tuning, OIALR can outperform conventional training approaches.
Critical Analysis
The paper provides a compelling analysis of the intrinsic orthogonality in neural network weights and demonstrates the potential benefits of exploiting this property through the OIALR training method. However, the researchers acknowledge that the performance gains of OIALR are dependent on appropriate hyperparameter tuning, which may require additional effort and domain expertise.
Furthermore, the study focuses on feedforward neural networks and does not explore the implications of orthogonality in other network architectures, such as convolutional or recurrent neural networks. Additional research may be needed to understand the generalizability of the findings across different neural network types.
While the paper demonstrates the effectiveness of OIALR on various benchmarks, it would be valuable to see how the method performs on real-world, large-scale applications with more complex data and model requirements. Evaluating the scalability and practical deployment considerations of OIALR would further strengthen the research.
Conclusion
This study provides valuable insights into the inherent orthogonality of neural network weights and introduces a novel training method, OIALR, that exploits this property. The findings suggest that leveraging the natural structure of neural networks can lead to more efficient and potentially higher-performing models.
The OIALR approach offers a promising direction for advancing the state of the art in neural network training, with potential applications in a wide range of domains. As the field of deep learning continues to evolve, studies like this that delve into the fundamental dynamics of neural networks can help drive further breakthroughs and more robust, scalable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Harnessing Orthogonality to Train Low-Rank Neural Networks
Daniel Coquelin, Katharina Flugel, Marie Weiel, Nicholas Kiefer, Charlotte Debus, Achim Streit, Markus Gotz
This study explores the learning dynamics of neural networks by analyzing the singular value decomposition (SVD) of their weights throughout training. Our investigation reveals that an orthogonal basis within each multidimensional weight's SVD representation stabilizes during training. Building upon this, we introduce Orthogonality-Informed Adaptive Low-Rank (OIALR) training, a novel training method exploiting the intrinsic orthogonality of neural networks. OIALR seamlessly integrates into existing training workflows with minimal accuracy loss, as demonstrated by benchmarking on various datasets and well-established network architectures. With appropriate hyperparameter tuning, OIALR can surpass conventional training setups, including those of state-of-the-art models.
Read more7/11/2024

0
SARA: Singular-Value Based Adaptive Low-Rank Adaption
Jihao Gu, Shuai Chen, Zelin Wang, Yibo Zhang, Ping Gong
With the increasing number of parameters in large pre-trained models, LoRA as a parameter-efficient fine-tuning(PEFT) method is widely used for not adding inference overhead. The LoRA method assumes that weight changes during fine-tuning can be approximated by low-rank matrices. However, the rank values need to be manually verified to match different downstream tasks, and they cannot accommodate the varying importance of different layers in the model. In this work, we first analyze the relationship between the performance of different layers and their ranks using SVD. Based on this, we design the Singular-Value Based Adaptive Low-Rank Adaption(SARA), which adaptively finds the rank during initialization by performing SVD on the pre-trained weights. Additionally, we explore the Mixture-of-SARA(Mo-SARA), which significantly reduces the number of parameters by fine-tuning only multiple parallel sets of singular values controlled by a router. Extensive experiments on various complex tasks demonstrate the simplicity and parameter efficiency of our methods. They can effectively and adaptively find the most suitable rank for each layer of each model.
Read more8/7/2024
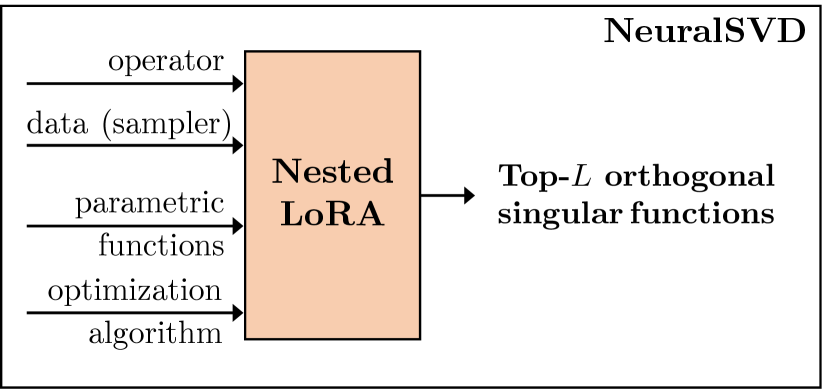
0
Operator SVD with Neural Networks via Nested Low-Rank Approximation
J. Jon Ryu, Xiangxiang Xu, H. S. Melihcan Erol, Yuheng Bu, Lizhong Zheng, Gregory W. Wornell
Computing eigenvalue decomposition (EVD) of a given linear operator, or finding its leading eigenvalues and eigenfunctions, is a fundamental task in many machine learning and scientific computing problems. For high-dimensional eigenvalue problems, training neural networks to parameterize the eigenfunctions is considered as a promising alternative to the classical numerical linear algebra techniques. This paper proposes a new optimization framework based on the low-rank approximation characterization of a truncated singular value decomposition, accompanied by new techniques called emph{nesting} for learning the top-$L$ singular values and singular functions in the correct order. The proposed method promotes the desired orthogonality in the learned functions implicitly and efficiently via an unconstrained optimization formulation, which is easy to solve with off-the-shelf gradient-based optimization algorithms. We demonstrate the effectiveness of the proposed optimization framework for use cases in computational physics and machine learning.
Read more8/22/2024
⚙️
0
A Random Matrix Approach to Low-Multilinear-Rank Tensor Approximation
Hugo Lebeau, Florent Chatelain, Romain Couillet
This work presents a comprehensive understanding of the estimation of a planted low-rank signal from a general spiked tensor model near the computational threshold. Relying on standard tools from the theory of large random matrices, we characterize the large-dimensional spectral behavior of the unfoldings of the data tensor and exhibit relevant signal-to-noise ratios governing the detectability of the principal directions of the signal. These results allow to accurately predict the reconstruction performance of truncated multilinear SVD (MLSVD) in the non-trivial regime. This is particularly important since it serves as an initialization of the higher-order orthogonal iteration (HOOI) scheme, whose convergence to the best low-multilinear-rank approximation depends entirely on its initialization. We give a sufficient condition for the convergence of HOOI and show that the number of iterations before convergence tends to $1$ in the large-dimensional limit.
Read more6/7/2024