HASS: Hardware-Aware Sparsity Search for Dataflow DNN Accelerator

0

Sign in to get full access
Overview
- This paper presents HASS, a hardware-aware sparsity search algorithm for efficient deployment of deep neural networks (DNNs) on dataflow accelerators.
- HASS aims to find the optimal sparsity pattern for a DNN model that maximizes the overall performance and energy efficiency on a target hardware accelerator.
- The proposed approach considers the hardware characteristics, such as the memory hierarchy and dataflow, to guide the search and find the sparse model that aligns well with the accelerator's architecture.
Plain English Explanation
HASS is a method that helps make deep learning models more efficient when running on specialized hardware accelerators. Deep learning models can become very large and complex, which makes them slow and power-hungry to run. HASS tries to find the best way to make these models "sparse" - that is, to remove some of the less important connections in the model without significantly reducing its accuracy.
The key insight of HASS is that it doesn't just look for any sparse model, but one that is specifically designed to work well with the hardware accelerator it will be running on. Different accelerators have different strengths and weaknesses, so HASS tailors the sparsity pattern to match the accelerator's architecture. For example, if the accelerator has a lot of memory but limited computation power, HASS might keep more weights in memory and remove computations instead.
By finding the right sparse model for the hardware, HASS is able to make deep learning models run much faster and use less power on specialized accelerators, without sacrificing too much accuracy. This could enable powerful AI capabilities to run on energy-efficient edge devices like smartphones or embedded systems.
Technical Explanation
The core of HASS is a hardware-aware sparsity search algorithm that explores different sparsity patterns for a given DNN model and evaluates their performance on the target hardware accelerator. The search is guided by a performance model that captures the key hardware characteristics, such as the memory hierarchy, dataflow, and computational capabilities.
HASS starts with the original dense DNN model and iteratively prunes the connections to create sparse versions. At each iteration, HASS evaluates the sparse model's inference latency, energy consumption, and accuracy using the performance model. The search continues until the desired accuracy-performance tradeoff is achieved.
The performance model in HASS is built upon analytical models for the dataflow accelerator, which estimate the execution time and energy consumption of different operations based on the hardware parameters and the sparsity pattern. HASS also considers the impact of compression techniques, such as weight sharing, to further improve the efficiency of the sparse model.
The authors evaluate HASS on several popular DNN models, including ResNet, BERT, and YOLO, and demonstrate significant performance improvements over other sparsity search methods. For example, HASS was able to achieve a 3.1x speedup and 4.5x energy reduction for ResNet-50 on a dataflow accelerator, while maintaining similar accuracy.
Critical Analysis
The HASS approach provides a promising solution for deploying efficient sparse DNN models on specialized hardware accelerators. By considering the hardware characteristics during the sparsity search, HASS is able to find sparse models that are well-suited for the target accelerator, leading to substantial performance and energy gains.
However, the paper does not provide a comprehensive evaluation of HASS's performance across a wider range of hardware platforms and DNN models. The authors focus on a single dataflow accelerator architecture and a limited set of models, which may limit the generalizability of the results.
Additionally, the performance model used in HASS relies on analytical estimates, which may not capture all the nuances of the hardware and could introduce inaccuracies. Validating the performance model against real hardware measurements would strengthen the confidence in HASS's optimization capabilities.
Further research could also explore ways to make the sparsity search process more efficient, potentially by incorporating machine learning techniques to guide the exploration [1] or by leveraging hardware-specific knowledge to prune the search space [2]. Investigating the interplay between sparsity and other hardware-aware optimizations, such as quantization or specialized kernels, could also lead to more holistic optimization strategies.
Conclusion
The HASS algorithm presented in this paper is a significant step towards enabling efficient deployment of deep learning models on specialized hardware accelerators. By considering the hardware characteristics during the sparsity search, HASS is able to find sparse models that are well-suited for the target accelerator, leading to substantial performance and energy improvements.
The ability to run powerful AI models on energy-efficient edge devices has far-reaching implications, from enabling new applications in robotics and autonomous systems to improving the privacy and responsiveness of AI-powered services. Further research and refinement of hardware-aware optimization techniques, like HASS, could help unlock the full potential of deep learning in real-world deployments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
HASS: Hardware-Aware Sparsity Search for Dataflow DNN Accelerator
Zhewen Yu, Sudarshan Sreeram, Krish Agrawal, Junyi Wu, Alexander Montgomerie-Corcoran, Cheng Zhang, Jianyi Cheng, Christos-Savvas Bouganis, Yiren Zhao
Deep Neural Networks (DNNs) excel in learning hierarchical representations from raw data, such as images, audio, and text. To compute these DNN models with high performance and energy efficiency, these models are usually deployed onto customized hardware accelerators. Among various accelerator designs, dataflow architecture has shown promising performance due to its layer-pipelined structure and its scalability in data parallelism. Exploiting weights and activations sparsity can further enhance memory storage and computation efficiency. However, existing approaches focus on exploiting sparsity in non-dataflow accelerators, which cannot be applied onto dataflow accelerators because of the large hardware design space introduced. As such, this could miss opportunities to find an optimal combination of sparsity features and hardware designs. In this paper, we propose a novel approach to exploit unstructured weights and activations sparsity for dataflow accelerators, using software and hardware co-optimization. We propose a Hardware-Aware Sparsity Search (HASS) to systematically determine an efficient sparsity solution for dataflow accelerators. Over a set of models, we achieve an efficiency improvement ranging from 1.3$times$ to 4.2$times$ compared to existing sparse designs, which are either non-dataflow or non-hardware-aware. Particularly, the throughput of MobileNetV3 can be optimized to 4895 images per second. HASS is open-source: url{https://github.com/Yu-Zhewen/HASS}
Read more6/6/2024
🤿
0
Workload-Aware Hardware Accelerator Mining for Distributed Deep Learning Training
Muhammad Adnan, Amar Phanishayee, Janardhan Kulkarni, Prashant J. Nair, Divya Mahajan
In this paper, we present a novel technique to search for hardware architectures of accelerators optimized for end-to-end training of deep neural networks (DNNs). Our approach addresses both single-device and distributed pipeline and tensor model parallel scenarios, latter being addressed for the first time. The search optimized accelerators for training relevant metrics such as throughput/TDP under a fixed area and power constraints. However, with the proliferation of specialized architectures and complex distributed training mechanisms, the design space exploration of hardware accelerators is very large. Prior work in this space has tried to tackle this by reducing the search space to either a single accelerator execution that too only for inference, or tuning the architecture for specific layers (e.g., convolution). Instead, we take a unique heuristic-based critical path-based approach to determine the best use of available resources (power and area) either for a set of DNN workloads or each workload individually. First, we perform local search to determine the architecture for each pipeline and tensor model stage. Specifically, the system iteratively generates architectural configurations and tunes the design using a novel heuristic-based approach that prioritizes accelerator resources and scheduling to critical operators in a machine learning workload. Second, to address the complexities of distributed training, the local search selects multiple (k) designs per stage. A global search then identifies an accelerator from the top-k sets to optimize training throughput across the stages. We evaluate this work on 11 different DNN models. Compared to a recent inference-only work Spotlight, our method converges to a design in, on average, 31x less time and offers 12x higher throughput. Moreover, designs generated using our method achieve 12% throughput improvement over TPU architecture.
Read more4/24/2024

0
FLAASH: Flexible Accelerator Architecture for Sparse High-Order Tensor Contraction
Gabriel Kulp, Andrew Ensinger, Lizhong Chen
Tensors play a vital role in machine learning (ML) and often exhibit properties best explored while maintaining high-order. Efficiently performing ML computations requires taking advantage of sparsity, but generalized hardware support is challenging. This paper introduces FLAASH, a flexible and modular accelerator design for sparse tensor contraction that achieves over 25x speedup for a deep learning workload. Our architecture performs sparse high-order tensor contraction by distributing sparse dot products, or portions thereof, to numerous Sparse Dot Product Engines (SDPEs). Memory structure and job distribution can be customized, and we demonstrate a simple approach as a proof of concept. We address the challenges associated with control flow to navigate data structures, high-order representation, and high-sparsity handling. The effectiveness of our approach is demonstrated through various evaluations, showcasing significant speedup as sparsity and order increase.
Read more4/26/2024
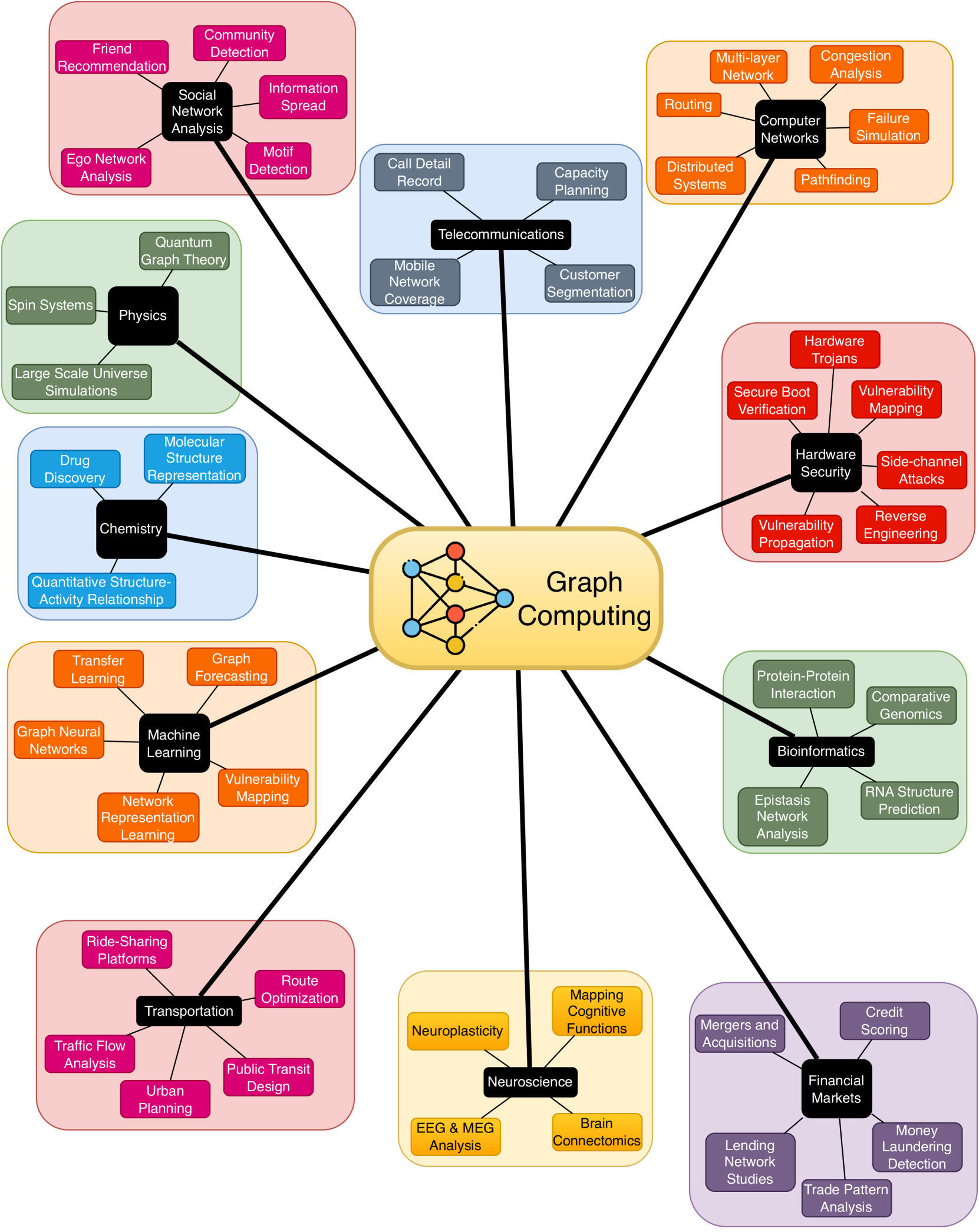
0
Enabling Accelerators for Graph Computing
Kaustubh Shivdikar
The advent of Graph Neural Networks (GNNs) has revolutionized the field of machine learning, offering a novel paradigm for learning on graph-structured data. Unlike traditional neural networks, GNNs are capable of capturing complex relationships and dependencies inherent in graph data, making them particularly suited for a wide range of applications including social network analysis, molecular chemistry, and network security. GNNs, with their unique structure and operation, present new computational challenges compared to conventional neural networks. This requires comprehensive benchmarking and a thorough characterization of GNNs to obtain insight into their computational requirements and to identify potential performance bottlenecks. In this thesis, we aim to develop a better understanding of how GNNs interact with the underlying hardware and will leverage this knowledge as we design specialized accelerators and develop new optimizations, leading to more efficient and faster GNN computations. A pivotal component within GNNs is the Sparse General Matrix-Matrix Multiplication (SpGEMM) kernel, known for its computational intensity and irregular memory access patterns. In this thesis, we address the challenges posed by SpGEMM by implementing a highly optimized hashing-based SpGEMM kernel tailored for a custom accelerator. Synthesizing these insights and optimizations, we design state-of-the-art hardware accelerators capable of efficiently handling various GNN workloads. Our accelerator architectures are built on our characterization of GNN computational demands, providing clear motivation for our approaches. This exploration into novel models underlines our comprehensive approach, as we strive to enable accelerators that are not just performant, but also versatile, able to adapt to the evolving landscape of graph computing.
Read more5/7/2024